Methodology Report #8: Construction of Weights for the 1996 Medical Expenditure Panel Survey Insurance Component List Sample
by John Paul Sommers, Ph.D., Agency for Health Care Policy and Research
Select for more information on
Health Care Information and Electronic Ordering Through the AHRQ Web Site.
Abstract
The Medical Expenditure Panel Survey (MEPS) is the third in a series of nationally representative surveys of medical care use and expenditures sponsored by the Agency for Health Care Research and Qualtiy (AHRQ). MEPS comprises four component surveys. The Insurance Component (IC) collects employment-related health insurance information, such as premiums and types of plans offered. Respondent characteristics-such as size of business, employee characteristics, and type of industry-also are collected. The IC sample comprises a household sample component (linked to the MEPS household survey) and a list sample. The list sample is an independently selected random sample of governments and private-sector establishments. Its numbers of employees enrolled. This report describes the overall response rates for the list sample and the process used to correct the weights for respondents. The weights are corrected in order to adequately represent all nonrespondents and all important subgroups, especially subgroups that may have had different response rates from the average for the survey.
Select for information on The Medical Expenditure Panel Survey (MEPS).
The Medical Expenditure Panel Survey (MEPS) Insurance Component (IC) is a survey of employers, unions, and other providers of health insurance. It is sponsored by the Agency for Health Care Research and Qualtiy (AHRQ) and is conducted by the U.S. Bureau of the Census. The IC sample is composed of two sets of employers and other providers of health insurance.
The first part of the IC sample is the list sample, an independently selected random sample of governments and private-sector establishments. The purpose of this sample of just over 40,000 employers is to make national and State estimates of employer insurance characteristics, their costs, and the numbers of employees enrolled (Sommers, 1999).
The second part of the IC sample, the household sample component, serves a different purpose: it is person oriented, not employer oriented. The two samples are collected together because of the similarity in data collected from similar types of respondents.
The IC household sample component is the set of employers and other providers of health insurance for persons who were members of the sample of the MEPS Household Component (HC), a household survey. Respondents in this part of the IC sample serve as proxy respondents, giving employer and insurance information for household members who are part of the HC sample. The data for household members collected during the IC are attached as data elements to other information collected directly from the household respondents. Weights derived for the data from the household sample component of the IC are thus dependent on the sample design of the HC (J. Cohen, 1997; S. Cohen, 1997). The development of weights for the MEPS HC will be presented in a separate document.
This report briefly describes the overall response rates for the list sample and the process used to correct the weights for respondents. The weights are corrected in order to adequately represent all nonrespondents and all important subgroups, especially subgroups that may have had different response rates from the average for the survey. Return To Top
In this section, various response rates are given for the list sample. Response rates for subgroups of the population that may have characteristics different from the average are especially important. Their importance is discussed in later sections describing the construction of weights for sampling units. Before the rates are presented, it is necessary to discuss the data collection methodology used for the IC. This affects the definition of a response and the method selected to create weights.
The IC sample is composed of governments and private-sector establishments. Governments were selected from the Census of Governments, and private-sector establishments from the Census Bureau's Standard Statistical Establishment List (Sommers, 1999). For all samples except State and very large local governments, each sample unit was prescreened. The purpose of this step was to determine a point of contact for data collection and determine whether the employer offered insurance to its employees. If the employer did not offer insurance, a small number of questions were administered and, with this done, the employer was considered a respondent. This was a quick and inexpensive method to collect the necessary data from the large number of employers that do not offer health insurance to their employees.
Return To Top
Employers that offered insurance were asked several brief questions and then mailed a questionnaire about their insurance. If they failed to return the mail questionnaire, an attempt was made to collect the information by telephone. For the purpose of this survey, employers that offered insurance were considered respondents only if they answered key questions on their health insurance. Those that did not were considered nonrespondents.
If no contact was made by telephone, a questionnaire was mailed. If the questionnaire was not returned, another attempt was made to collect information by telephone. Any employer from this group that responded by mail or telephone was a respondent. Note that for this group whether a nonrespondent had insurance was unknown.
Table 1 shows the private-sector sample by in scope and respondent status. Out-of-scope private-sector establishments were those that had gone out of business or consisted of a self-employed person with no other employees.
Although an establishment with insurance that does not answer questions about the plans offered is considered a nonresponse for the IC, one can argue that it provided certain valuable information. If one assumed that all cases were successfully prescreened, then the entire sample size could be used to estimate the percentage of establishments that offer insurance. As will be shown in the section describing the weighting methodology used, this partial information can be used as a part of the correction for nonresponse.
Table 2 shows the government sample by in scope and respondent status. Private-sector and government employers are shown separately because of the differences in response rates and other features. To be out of scope, a government must have ceased to function. To be a respondent, a government had to answer questions similar to those for a private-sector respondent.
Return To Top
Motivation for Weighting
Because the sample units were selected with unequal probabilities and because of nonresponse in the data collection, sampling weights must be calculated for each unit in the original sample and the weights of respondents must be adjusted for nonresponse (Kish, 1965). To motivate this adjustment, it is assumed that p i is the probability of selection of the ith unit in the sample, and wti = 1/pi , the initial weight. Then
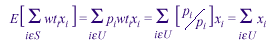
where S and U are the set of sampled units and set of units in the universe, respectively.
A method of making an unbiased estimate of a total from the sample is to use the weighted sum from the sample as the estimate. If there is nonresponse-if, for example, some of the x values are missing-one would try to adjust sampling weights for the values of respondents in cells for which the responding x's have the same or very similar expected values to those of the nonresponding x's. Thus, the final objective is to have the sum of the new adjusted weights of respondents over cells with various characteristics equal to the totals from the original sample or some other set of known control totals for the population.
Classification of Establishments
Cells defined by size of establishment, size of firm, and State were used to create cells for weighting. These same characteristics had been used for sample selection (Sommers, 1999). It was first thought that the original cell classification of establishments would be used. However, the following factors led to a decision to update the classification:
- The frame used for sampling was preliminary for 1996. The Census Bureau had since produced a final listing of establishments for March 1996.
- The reported and verified employment sizes of establishments sometimes differed considerably from the employment sizes on the frame.
A scheme was developed to update the size classification. Otherwise, a unit with a frame employment of 2 but a reported establishment employment of 2,000 would cause extreme results during the poststratification process (described later in this report).
Establishments were divided into the six size classes used for sample selection. (See Sommers, 1999, and the appendix.) If the reported employment would have placed an establishment more than one cell away from its original frame-defined cell, then the establishment was reclassified. These establishments were considered to have been mistakes on the frame. Establishments that moved only one cell were allowed because the date of the frame employments was early March and the reference date in the survey was July of the same year. Since there is seasonality and growth in employment, with March being a relatively low month for employment and July high, it seemed that this change should be allowed (Bureau of Labor Statistics, 1996). Approximately 5.6 percent of the private-sector sample changed its establishment size cell either up or down at least two classes to correspond to the reported employment. The remaining establishments kept their original frame classification. Return To Top
Prescreener Respondent Weight Adjustments
As discussed earlier, during data collection a telephone prescreener was conducted. Employers that reported during this prescreener that they did not offer insurance to their employees were considered respondents. Those that did offer health insurance were not considered respondents unless they provided further information on the insurance either by mail or telephone. As shown in Table 1, 5,061 private-sector employers (14.4 percent of the sample) were prescreened, had insurance, and later were classified as nonrespondents. However, after the prescreener, 25,064, or 71.3 percent of the in scope sample, had answered whether they provided insurance. It is of utmost importance that this information be retained in the weights after adjustment for nonresponse. Thus, the first step in weighting was to adjust the weights of respondents that provided insurance and were successfully prescreened so that their adjusted total weight would be equal to the total weight for all employers who were successfully prescreened and provided insurance to their employees.
First, weights for the respondents that offered insurance and had also responded to the prescreener were adjusted so that their total weight equaled the weight of all respondents to the prescreener that offered insurance for a large number of cells. Among the variables chosen to define these important cells were:
Return To Top
- A variable with 41 levels that was defined by crossing groups of States with a variable with 8 levels based on employment size of the establishment and that of the enterprise as listed on the frame (Sommers, 1999).
- Whether the establishment was from a firm with multiple establishments.
- The industry of the establishment.
Because crossing all these variables divides the sample into too many cells, a method called raking was employed to create an adjustment that retained the sum of the weights for as many cells as possible.
In an ideal world, if the value of the ith unit's initial weight were wt i , the adjusted weight for responding units within each response cell C, where CR is the set of respondents in C, would be
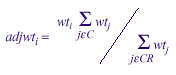
The adjusted weights for nonrespondents would be set to zero. This would be done for all cells C and CR defined by the cross of all the important variables.
Because the number of cells defined by the cross of all levels of these variables was very large, the sum of the respondent weights for each cell created by these cross-classifications was not made equal to the population total. Instead, the sums of the respondent weights for all cells defined by any one of the variables alone were made to sum to the totals for respondents and nonrespondents in the cell. Thus, the sum of the respondents' weights equaled the total sample weights for all the marginal cells defined by these variables. Return To Top
The method can be illustrated with an example. Suppose one were concerned only with two variables: (1) type of firm, with 2 levels-single establishment and multi establishment, and (2) industry, with 7 levels. The sum of weights of respondents in the 14 cells defined by a cross of the two variables (for instance, single and mining) is not made to equal the total of sampling weights for all establishments in each of the cells. Instead, the sum of the weights for respondents for each of the nine marginal cells defined by one of the individual variables (for instance, single or mining) is made to equal the total weights of all establishments in the cell. To accomplish this, one uses an iterative technique called raking, which is explained below (Madow, Olkin, and Rubin, 1983).
Assume 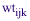 is the sampling weight for the ith sample unit in the jkth cell. For example, the first variable could break the population by type of firm and the second by industry. One would adjust the weights to create a set of weights is the sampling weight for the ith sample unit in the jkth cell. For example, the first variable could break the population by type of firm and the second by industry. One would adjust the weights to create a set of weights 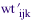 such that [equation] such that [equation]
To do this, one first creates values a j such that

Then 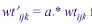 for all cases where the ijkth case is a respondent. Otherwise, the adjusted weight is 0. for all cases where the ijkth case is a respondent. Otherwise, the adjusted weight is 0.
One continues this process through all values of j. This makes the respondents' weights sum to the proper values for the first defining variable, but not the second. One then operates on the values of wt 9 ijk to adjust them so that the cells defined by the second variable are equal. Of course, now this third set of weights may not sum properly for cells defined by the first variable. The cycle is repeated, readjusting each new set of weights by continuing to iterate through the process. Usually, within several cycles, the weights will converge so that for each cell defined by either of the two variables, the sum of the latest set of weights is a value very close to the required marginal total. This completes the raking process. The process can be applied to make weights sum to marginal cell totals for as many variables as one likes. In this example, two variables were used to create marginal totals and the weights were forced to add to the sample total for the type of firm and for each industry, but not necessarily by type of firm and industry.
Return To Top
In adjustments for the sampling weights for respondents offering insurance that also responded to the prescreener, three variables defined the marginal cells and their totals for this process:
- Eight combinations of establishment size and firm size within the 41 State sets. (Each of the 40 most populous States was a set, and the District of Columbia and the 10 least populous States were grouped together as a single set.)
- Multi and single establishment firms.
- Industry type.
Exact category definitions can be found in the appendix.
Return To Top
Prescreener Nonrespondent Weight Adjustments
Weights for the remaining respondents from which no prescreener information was collected must be adjusted to account for nonrespondents that did not provide prescreener information. Because of the lack of the prescreener information, there is no partial response in this group. Establishments in this group could either provide or not provide insurance to their employees. This part of the sample adjustment is similar to that done for most surveys which have only one stage of data collection. A nonresponse correction adjusted the current set of weights of all 23,232 (6,381 + 13,622 + 3,229) complete respondents, regardless of their prescreener status, so that their weights after the correction also included the total sampling weight of the 6,850 nonrespondents that had an incomplete prescreener and unknown insurance status. The weights used for the respondents were those currently available. For the 6,381 prescreener respondents that did not offer insurance and the 3,229 respondents that did not answer the prescreener, these were the original sampling weights. For the prescreener respondents that offered insurance, they were the weights after the first adjustment, described above.
To make this second adjustment, raking was used. The variables and cells used were the same as those used for the previous correction for those nonrespondents that answered the prescreener and offered insurance. Return To Top
Poststratification of Private-Sector Weights
Correction of weights can be taken further using a technique called poststratification. This method is used when outside information is available about the population. The weighted sum of a variable can be thought of as an estimate of the population total for the variable. Ideally, the total weighted sum for each important subset of the population should equal the population for that subset. Controlling weights to population totals from another source is called poststratification (Madow, Olkin, and Rubin, 1983; Skinner, Holt, and Smith, 1989).
The MEPS IC private-sector sample is selected from a list of establishments, the Standard Statistical Establishment List (SSEL) maintained by the Census Bureau (Kreps, Slater, and Plotkin, 1979; Sommers, 1999). This list contains each establishment that was in business during the year and its employment size as of March of the year. It is the source of official Census Bureau figures of the number and employment size of establishments in the United States. For this reason, it is very desirable that the estimates of employment obtained from the IC match the values from the SSEL for the total and a variety of subtotals.
Because establishments go out of business during the year, the list used for the IC represented a point in time, establishments in business as of a certain date, rather than the entire frame for the year. It was felt that this type of list, showing the entire population of workers at one instant, would give a better picture of the percentage of establishments in business at any point that were offering insurance and the numbers of employees in the work force offered insurance. It was felt that including all establishments in business during the year might skew the results. Small establishments tend not to offer health insurance and also go in and out of business more rapidly than larger ones. Thus to include all the small businesses from the entire year would give a higher estimate of the numbers of establishments not offering insurance to their employees and the number of employees not offered insurance. It also could tend to double-count employees who moved from closed establishments where they were likely not to have had insurance. Thus, one could get a higher proportional count of people not offered insurance.
The SSEL used to provide control totals for the IC was the list of establishments in business as of the end of the third quarter of 1996. Because of the retrospective time frame of the data collected, this information was available in late 1997, when weighting took place. This time frame also fit well with the timing of the data collected.
Return To Top
To implement this process, the same 41 ´ 8 categories were used that were assigned during the raking process. These cells were based on the establishment's location, firm size, and employment size. The size used was the one reported for the frame, not the size reported during the survey, except for establishments that were reassigned to new establishment size classes during the classification process described earlier. The size reported for the SSEL frame was used because the survey period was later in the year than the SSEL, and it was felt that the frame categories and employment sizes were the most comparable variables. The frame employment for the SSEL is for early March of 1996.
The weighted frame employment sizes from the responding sample establishments were obtained using the weights after the two other adjustments and the total employment on the frame for in scope establishments were calculated for each of the 328 categories. The ratio of the frame employment size for March to the estimated employment size from the sample was calculated for each category. A new corrected weight for each respondent in the category was created by multiplying its category ratio times the current value of its corrected weight before poststratification. This procedure corrected the sample weights so that the sample employment for March equaled the frame employment. The collected employment estimate was somewhat higher than the frame employment because employment tends to have a lower seasonal component in March than in the later months of the year for which data were collected (Bureau of Labor Statistics, 1996).
Return To Top
Government Weights
Data for governments were collected in the same manner as for the private sector: a prescreener phone contact was used as the first contact, and the process for adjusting weights parallels that for the private sector. The differences are in the definition and sizes of the cells used. Cells were determined by a cross of the 41 State sets (40 most populous States and the residual set of 10 States and the District of Columbia) and 5 classes based on size and type of government. The classes are listed in the appendix. These cells were used for two nonresponse adjustments and for poststratification of governments.
As with the private-sector weights, the last step of the process was a poststratification adjustment. Units within the 41 ´ 5 cells were adjusted using the ratio of the total 1996 frame employment size for the cell divided by the weighted total 1996 employment size for the sample within the cell.
Return To Top
Representative Results
Table 3 contains some typical results for the private sector along with their relative standard errors.
Return To Top
References
Bureau of Labor Statistics (US). Current employment statistics. Washington. Series EEU00500005; 1996.
Cohen J. Design and methods of the Medical Expenditure Panel Survey Household Component. Rockville (MD): Agency for Health Care Policy and Research; 1997. MEPS Methodology Report No. 1. AHRQ Pub. No. 97-0026.
Cohen S. Sample design of the 1996 Medical Expenditure Panel Survey Household Component Rockville (MD): Agency for Health Care Policy and Research; 1997. MEPS Methodology Report No. 2. AHRQ Pub. No. 97-0027.
Kish L. Survey sampling. New York: John Wiley and Sons; 1965.
Kreps J, Slater CM, Plotkin MD. The Standard Statistical Establishment List Program. Washington: U.S. Bureau of the Census; 1979. Technical Paper No. 44.
Madow WG, Olkin I, Rubin DR. Incomplete data in sample surveys, volume 2: theory and bibliographies. New York: Academic Press; 1983.
Skinner CJ, Holt D, Smith TMF. Analysis of complex surveys. New York: John Wiley and Sons; 1989.
Sommers JP. List sample design of the 1996 Medical Expenditure Panel Survey Insurance Component. Rockville (MD): Agency for Health Care Policy and Research; 1999. MEPS Methodology Report No. 6. AHRQ Pub. No. 99-0037.
Return To Top
Appendix: Definition of Selected Variables
Industry type (Standard Industry Code)
| 1 |
Construction, SIC = 15-17 |
| 2 |
Mining, manufacturing, SIC = 10-14, 20-39 |
| 3 |
Transportation, communications, utilities, SIC = 40-49 |
| 4 |
Wholesale trade, SIC = 50-51 |
| 5 |
Agriculture, retail trade, SIC = 01-09, 52-59 |
| 6 |
Finance, insurance, real estate, SIC = 60-67 |
| 7 |
Services, SIC = 70-89 |
| 8 |
Unknown, SIC = missing |
| Firm size |
| S |
Less than 50 employees |
| M |
50-999 employees |
| L |
1,000 employees or more |
| Establishment size |
| 1 |
1-5 employees |
| 2 |
6-24 employees |
| 3 |
25-49 employees |
| 4 |
50-249 employees |
| 5 |
250-999 employees |
| 6 |
1,000 employees or more |
| Collapsed firm size X establishment size |
| 1 |
Firm size = S, establishment size = 1 |
| 2 |
Firm size = S, establishment size = 2 |
| 3 |
Firm size = S, establishment size = 3 |
| 4 |
Firm size = M, establishment size = 1,2 |
| 5 |
Firm size = M, establishment size = 3,4 |
| 6 |
Firm size = L, establishment size = 1,2 |
| 7 |
Firm size = L, establishment size = 3,4 |
| 8 |
Firm size = M, L, establishment size = 5, 6 |
| Multi/single establishment firm |
| 1 |
if multi, 0 otherwise |
| State groupings |
| A DE, DC, ID, MT, NH, ND, RI, SD, VT, and WY are grouped together because of small sample sizes |
| All 40 other States stand on their own |
| Government size groups |
| 1 |
if a State government |
| 2 |
if a local certainty |
| 3 |
if a local noncertainty government and frame employment 200 |
| 4 |
if a local noncertainty government and 199 |
| 5 |
if a local noncertainty government and frame employment is 1,000 or more |
| Note: State governments were classified separately because there is only one per State (they are unique within each State). |
Return To Top
Table 1. Private-sector response in the 1996 Medical Expenditure Panel Survey Insurance Component list sample
| 37,710 |
| 2,567 |
| 35,143 |
| 23,232 |
| 20,003 |
| 13,622 |
| 6,381 |
| 3,229 |
| 11,911 |
| 5,061 |
| 6,850 |
Source: Center for Financing, Access, and Cost Trends, Agency for Health Care Policy and Research: Medical Expenditure Panel Survey Insurance Component, 1996.
Return to Top
Table 2. Government response in the 1996 Medical Expenditure Panel Survey Insurance Component list sample
| 2,649 |
| 20 |
| 2,629 |
| 2,224 |
| 1,049 |
| 1,049 |
| 0 |
| 1,175 |
| 405 |
| 151 |
| 254 |
Source: Center for Financing, Access, and Cost Trends, Agency for Health Care Policy and Research: Medical Expenditure Panel Survey Insurance Component, 1996.
Return to Top
Table 3. Selected statistics from the 1996 Medical Expenditure Panel Survey Insurance Component list sample
| 5,998,994 |
0.6 |
| 103,846,469 |
1.5 |
| 53.2 |
0.5 |
| $1,996.90 |
0.8 |
| $338.33 |
2.6 |
Source: Center for Financing, Access, and Cost Trends, Agency for Health Care Policy and Research: Medical Expenditure Panel Survey Insurance Component, 1996.
Return to Top
Suggested Citation:
Methodology Report #8: Construction of Weights for the 1996 Medical Expenditure Panel Survey Insurance Component List Sample.
November 1999. Agency for Healthcare Research and Quality, Rockville, MD.
http://www.meps.ahrq.gov/data_files/publications/mr8/mr8.shtml
|
|
|
