|
|
|
Font Size:
|
||||
|
|
|
|
||||
MEPS HC-198: 2017 Food SecurityJuly 2019 Agency for Healthcare Research and Quality NOTE: The MEPS instrument design changed beginning in Spring of 2018, affecting Panel 23 Round 1, Panel 22 Round 3, and Panel 21 Round 5. For the Full-Year 2017 PUFs, the Panel 22 Round 3 and Panel 21 Round 5 data were transformed to the degree possible to conform to the previous design. For the Full-Year 2018 PUFs, Panel 22 Rounds 1 and 2, collected under the old design, were transformed to the degree possible to conform to the new design. Data users should be aware of possible impacts on the data and especially trend analysis for these data years due to the design transition. A. Data Use Agreement A. Data Use AgreementIndividual identifiers have been removed from the micro-data contained in these files. Nevertheless, under sections 308 (d) and 903 (c) of the Public Health Service Act (42 U.S.C. 242m and 42 U.S.C. 299 a-1), data collected by the Agency for Healthcare Research and Quality (AHRQ) and/or the National Center for Health Statistics (NCHS) may not be used for any purpose other than for the purpose for which they were supplied; any effort to determine the identity of any reported cases is prohibited by law. Therefore in accordance with the above referenced Federal Statute, it is understood that:
By using these data you signify your agreement to comply with the above stated statutorily based requirements with the knowledge that deliberately making a false statement in any matter within the jurisdiction of any department or agency of the Federal Government violates Title 18 part 1 Chapter 47 Section 1001 and is punishable by a fine of up to $10,000 or up to 5 years in prison. The Agency for Healthcare Research and Quality requests that users cite AHRQ and the Medical Expenditure Panel Survey as the data source in any publications or research based upon these data. B. Background1.0 Household ComponentThe Medical Expenditure Panel Survey (MEPS) provides nationally representative estimates of health care use, expenditures, sources of payment, and health insurance coverage for the U.S. civilian noninstitutionalized population. The MEPS Household Component (HC) also provides estimates of respondents’ health status, demographic and socio-economic characteristics, employment, access to care, and satisfaction with health care. Estimates can be produced for individuals, families, and selected population subgroups. The panel design of the survey, which includes 5 Rounds of interviews covering 2 full calendar years, provides data for examining person level changes in selected variables such as expenditures, health insurance coverage, and health status. Using computer assisted personal interviewing (CAPI) technology, information about each household member is collected, and the survey builds on this information from interview to interview. All data for a sampled household are reported by a single household respondent. The MEPS-HC was initiated in 1996. Each year a new panel of sample households is selected. Because the data collected are comparable to those from earlier medical expenditure surveys conducted in 1977 and 1987, it is possible to analyze long-term trends. Each annual MEPS-HC sample size is about 15,000 households. Data can be analyzed at either the person or event level. Data must be weighted to produce national estimates. The set of households selected for each panel of the MEPS HC is a subsample of households participating in the previous year’s National Health Interview Survey (NHIS) conducted by the National Center for Health Statistics. The NHIS sampling frame provides a nationally representative sample of the U.S. civilian noninstitutionalized population and reflects an oversample of Blacks and Hispanics. In 2006, the NHIS implemented a new sample design, which included Asian persons in addition to households with Black and Hispanic persons in the oversampling of minority populations. NHIS introduced a new sample design in 2016 that discontinued oversampling of these minority groups. The linkage of the MEPS to the previous year’s NHIS provides additional data for longitudinal analytic purposes. 2.0 Medical Provider ComponentUpon completion of the household CAPI interview and obtaining permission from the household survey respondents, a sample of medical providers are contacted by telephone to obtain information that household respondents can not accurately provide. This part of the MEPS is called the Medical Provider Component (MPC) and information is collected on dates of visits, diagnosis and procedure codes, charges and payments. The Pharmacy Component (PC), a subcomponent of the MPC, does not collect charges or diagnosis and procedure codes but does collect drug detail information, including National Drug Code (NDC) and medicine name, as well as date filled and sources and amounts of payment. The MPC is not designed to yield national estimates. It is primarily used as an imputation source to supplement/replace household reported expenditure information. 3.0 Survey Management and Data CollectionMEPS HC and MPC data are collected under the authority of the Public Health Service Act. Data are collected under contract with Westat, Inc. (MEPS HC) and Research Triangle Institute (MEPS MPC). Data sets and summary statistics are edited and published in accordance with the confidentiality provisions of the Public Health Service Act and the Privacy Act. The National Center for Health Statistics (NCHS) provides consultation and technical assistance. As soon as data collection and editing are completed, the MEPS survey data are released to the public in staged releases of summary reports, micro data files, and tables via the MEPS website. Selected data can be analyzed through MEPSnet, an on-line interactive tool designed to give data users the capability to statistically analyze MEPS data in a menu-driven environment. Additional information on MEPS is available from the MEPS project manager or the MEPS public use data manager at the Center for Financing, Access, and Cost Trends, Agency for Healthcare Research and Quality, 5600 Fishers Lane, Rockville, MD 20857 (301-427-1406). C. Technical and Programming Information1.0 General InformationThis documentation describes the 2017 food security data file from the Medical Expenditure Panel Survey Household Component (MEPS HC). Released as an ASCII file (with related SAS, SPSS, and Stata programming statements and data user information) and a SAS transport dataset, this public use file provides information collected on a nationally representative sample of the civilian noninstitutionalized population of the United States for calendar year 2017. The file contains 16 variables and has a logical record length of 51 with an additional 2-byte carriage return/line feed at the end of each record. This file consists of MEPS survey data obtained in Round 4 of Panel 21 and Round 2 of Panel 22, in calendar year 2017, and contains variables pertaining to food security. The following documentation offers a brief overview of the types and levels of data provided, content and structure of the files, and programming information. It contains the following sections:
Both weighted and unweighted frequencies of most variables included in the 2017 food security data file are provided in the accompanying codebook file. The exceptions to this are weight variables and variance estimation variables. Only unweighted frequencies of these variables are included in the accompanying codebook file. See the Weights Variables list in Section D, Variable-Source Crosswalk. A database of all MEPS products released to date and a variable locator indicating the major MEPS data items on public use files that have been released to date can be found on the MEPS website. 2.0 Data File InformationThis public use dataset contains variables and frequency distributions associated with 12,715 households who participated in the MEPS Household Component of the Medical Expenditure Panel Survey in 2017. These households received a positive family-level weight and were part of one of the two MEPS panels for whom food security data were collected in Round 4 of Panel 21 or Round 2 of Panel 22. 2.1 Codebook StructureThe codebook and data file sequence lists variables in the following order:
2.2 Reserved Codes
2.3 Codebook Format
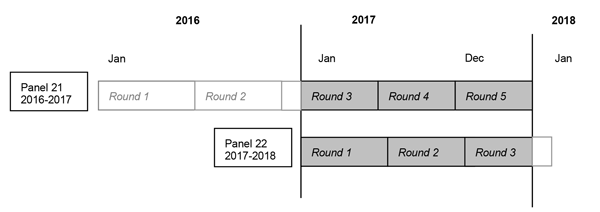
2.4 Variable NamingVariable names reflect the content of the variable, with an eight-character limitation. The last two characters denote the rounds of data collection, Round 4 of Panel 21 and Round 2 of Panel 22. Variables contained in this delivery were derived either from the questionnaire itself or from the CAPI. The source of each variable is identified in Appendix 1 “Variable-Source Crosswalk.” Sources for each variable are indicated in one of three ways: (1) variables derived from CAPI or assigned in sampling are so indicated; (2) variables collected at one or more specific questions have those numbers and questionnaire sections indicated in the “SOURCE” column; and (3) variables constructed from multiple questions using complex algorithms are labeled “Constructed” in the “SOURCE” column. 2.5 File Contents2.5.1 Survey Administration Variables (HOMEIDX – PANEL)HOMEIDX uniquely identifies each household on the file and consists of the Dwelling Unit ID (DUID) followed by the RU letter and round number. The definitions of Dwelling Units (DUs) in the MEPS Household Survey are generally consistent with the definitions employed for the National Health Interview Survey (NHIS). The DUID is a five-digit random ID number assigned after the case was sampled for MEPS. PANEL is a constructed variable used to specify the panel number for the person. PANEL will indicate either Panel 21 or Panel 22 for each person on the file. Panel 21 is the panel that started in 2016, and Panel 22 is the panel that started in 2017. Households are eligible for the Food Security PUF if the MEPS interview was completed by an RU member and if the household is not a student RU. 2.5.2 Food Security Variables (FSOUT42 – FSNEDY42)Respondents were asked: FSOUT42 - how often in the last 30 days anyone in the household worried whether food would run out before getting money to buy more FSLAST42 - how often in the last 30 days the food purchased didn’t last and the person/household didn’t have money to get more FSAFRD42 - how often in the last 30 days the person/household could not afford to eat balanced meals FSSKIP42 - in the last 30 days did the person/household reduce or skip meals because there wasn’t enough money for food (coded as “-1 Inapplicable” when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9) FSSKDY42 - how many meals were skipped in the last 30 days (coded as “-1 Inapplicable” when FSSKIP42 = 2, -7, -8, or -9 OR when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9) FSLESS42 - in the last 30 days did the person/household ever eat less because there wasn’t enough money for food (coded as “-1 Inapplicable” when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9) FSHGRY42 - in the last 30 days was the person/household ever hungry but didn’t eat because there wasn’t enough money for food (coded as “-1 Inapplicable” when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9) FSWTLS42 - in the last 30 days did anyone in the household lose weight because there wasn’t enough money for food (coded as “-1 Inapplicable” when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9) FSNEAT42 - in the last 30 days did anyone in the household not eat for a whole day because there wasn’t enough money for food (coded as “-1 Inapplicable” when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9; or when FSLESS42, FSHGRY42, and FSWTLS42 = 2, -7, -8, or -9) FSNEDY42 - how many days in the last 30 days anyone in the household had not eaten for a whole day because there wasn’t enough money for food (coded as “-1 Inapplicable” when FSOUT42, FSLAST42, and FSAFRD42 = 3, -7, -8, or -9; or when FSLESS42, FSHGRY42, and FSWTLS42 = 2, -7, -8, or -9; or when FSNEAT42 = 2, -7, -8, or -9) 2.6 Linking to Other Files2.6.1 MEPS Public Use FilesThe family (RU) level records in this public use file can be linked to the 2017 full year Consolidated file to obtain additional data for the families included in this file. To link the records with the Consolidated data file records, create an RU ID using the first six characters of HOMEIDX (columns 1-5 are DUID and column 6 is RU letter). On the full year Consolidated file concatenate DUID with RULETR42 (Round 4/2 RU letter) to obtain an equivalent ID. The records in both files can then be linked with this ID. The reference person of the RU can be identified in the Consolidated data file by the variable REFPRS42. Food Security PUF: Includes HOMEIDX(12345A4) as DUID(12345) + RULETER42(A) + Round(4) Construct RUID(12345A) as substr(HOMEIDX, 1,6) Consolidated PUF: Includes DUID(12345) and RULETER42(A) Construct RUID(12345A) as DUID(12345) + RULETER42(A) 2.6.2 National Health Interview SurveyThe set of households selected for MEPS is a subsample of those participating in the National Health Interview Survey (NHIS), thus, each MEPS panel can also be linked back to the previous year’s NHIS public use data files. For information on obtaining MEPS/NHIS link files please see the AHRQ website. 2.6.3 Longitudinal AnalysisPanel-specific longitudinal files are available for downloading in the data section of the MEPS website. For each panel, the longitudinal file comprises MEPS survey data obtained in Rounds 1 through 5 of the panel and can be used to analyze changes over a two-year period. Variables in the file pertaining to survey administration, demographics, employment, health status, disability days, quality of care, patient satisfaction, health insurance, and medical care use and expenditures were obtained from the MEPS full-year Consolidated files from the two years covered by that panel. For more details or to download the data files, please see Longitudinal Weight Files at the AHRQ website. 3.0 Survey Sample Information3.1 Background on Sample Design and Response RatesThe MEPS is designed to produce estimates at the national and regional level over time for the civilian, noninstitutionalized population of the United States and some subpopulations of interest. The data in this public use file pertain to calendar year 2017. The data were collected in Rounds 1, 2, and 3 for MEPS Panel 22 and Rounds 3, 4, and 5 for MEPS Panel 21. (Note that Round 3 for a MEPS panel is designed to overlap two calendar years, as illustrated below.) The 2017 food security data were collected only in Round 4 of Panel 21 and Round 2 of Panel 22.
A sample design feature shared by both Panel 21 and Panel 22 involved the partitioning of the sample domain “Other” (serving as the catchall stratum, and consisting mainly of households with “White” members) into two sample domains. This was done for the first time in Panel 16. The two domains were defined as: those households characterized as “complete” respondents to the NHIS; and those characterized as “partial completes.” NHIS “partial completes” typically have a lower response rate to MEPS and for both MEPS panels the “partial” domain was sampled at a lower rate than the “complete” domain. This approach has served to reduce survey costs, since the “partials” tend to have higher costs in gaining survey participation, but has also increased sample variability due to the resulting increased variance in sampling rates. 3.1.1 ReferencesFor detailed historical information on the MEPS sample design, see Chowdhury, S.R., Machlin, S.R., Gwet, K.L.
Sample Designs of the Medical Expenditure Panel Survey Household Component, 1996–2006 and 2007–2016. Methodology Report #33. January 2019.
Agency for Healthcare Research and Quality, Rockville, MD. 3.1.2 MEPS-Linked to the National Health Interview Survey (NHIS)Each responding household found in this 2017 MEPS dataset is associated with one of two separate and overlapping MEPS panels, MEPS Panel 21 and MEPS Panel 22. These panels consist of subsamples of households participating in the 2015 and 2016 NHIS, respectively. Panel 21 is the last MEPS panel reflecting the NHIS sample design first implemented in 2006, while Panel 22 is the first MEPS panel reflecting the new NHIS sample design first implemented in 2016. Whenever there is a change in sample or study design, it is good survey practice to assess whether such a change could affect the sample estimates. For example, increased coverage of the target populations with an updated sample design based on data from the latest Census can improve the accuracy of the sample estimates. MEPS estimates have been and will continue to be evaluated to determine if an important change in the survey estimates might be associated with a change in design. Background on the two NHIS sample designs of interest here is provided next. Background on the NHIS Sample Redesign Implemented in 2006 (associated with MEPS Panel 21)The sample for the NHIS is redesigned approximately every 10 years. From 1995 to 2005 the NHIS used the same sample design, an area probability sample of PSUs (one or more counties) and Secondary Sampling Units (SSUs, to be referred to as segments here and generally consisting of one or more census blocks). Segments with a higher concentration of blacks or Hispanics were oversampled to increase the sample yields of these two minority groups for the NHIS. The segments were designed to be large enough to support the sample selection of housing units within each segment for up to 12 years. The initial MEPS sample design, which began in 1996, was based on that NHIS design through MEPS Panel 11, thus clustering the MEPS sample in the same general geographic areas from 1996–2006. A new NHIS sample design was implemented in 2006 that was very similar in structure to the previous NHIS sample design. The PSUs and segments were sampled independently from the prior design. The major difference was that a third minority group, Asians, was oversampled under the 2006 NHIS sample design. Thus, the sample selection of segments was designed to oversample all three minority groups. All three of these minority groups were also oversampled for MEPS from among the NHIS responding households from 2007 through to 2016. The only major difference in eligibility status for housing units between NHIS under the 1996 and 2006 designs and MEPS was that college dorms were eligible for sampling for the NHIS but not for MEPS. That is, college aged students living away from home during the school year were interviewed at their place of residence for the NHIS but were identified by and linked to their parents’ household for MEPS. Panel 21 Household Sample SizeThere were 9,700 households (occupied DUs) selected for MEPS Panel 21, of which 9,658 were fielded for MEPS after the elimination of any units characterized as ineligible for fielding. Background on the NHIS Sample Redesign Implemented in 2016 (associated with MEPS Panel 22)Beginning in 2016, NCHS implemented another new sample design for the NHIS which differed substantially from the prior design. Each of the 50 states as well as the District of Columbia served as explicit strata for sample selection purposes with the intent of providing the capability of state level NHIS estimates obtained through pooling across years if the sample size for a single year would result in unreliable estimates. In contrast to the previous design, households in areas with higher concentrations of minorities are not oversampled. PSUs are still formed at the county level. However, within sampled PSUs, the clusters of addresses that have been sampled for each year are not in the form of segments as described above for the previous designs. For the 2016 NHIS each such cluster consisted of roughly 25 subclusters selected using random systematic sampling across the full geography of the PSU. Each subcluster is made up of, generally, four nearby addresses. Thus, for 2016 each cluster contained approximately 100 addresses in all. The number of subclusters per cluster can vary from year to year. Another major change is that the list of DUs (addresses) was obtained from the Computerized Delivery Sequence File (CDSF) of the U.S. Post Office, which is a different approach than the standard listing process for area probability samples used in the pre-2016 designs. While addresses in the CDSF provide very high coverage of most areas of the country, coverage in rural areas can be somewhat lower. For rural areas where this was a concern, address lists were created through the conventional listing process. A description of the NHIS sample design is provided by NCHS on the NHIS website. Panel 22 Household Sample SizeA subsample of 9,700 households was randomly selected for MEPS Panel 22 from the households responding to the 2016 NHIS, of which 9,693 were fielded for MEPS after the elimination of any units characterized as ineligible for fielding. Implications of the New Design on MEPS EstimatesUnder the new design, MEPS sampled households will not be clustered within the same segments as in the previous designs. Due to the use of PSU-wide lists of addresses, sampled households will be widely scattered within PSUs serving to limit the impact of clustering on the variance of MEPS estimates. Also, in contrast to the previous design, the NHIS sampling rates at the address level currently do not vary due to oversampling of minorities (although this could change in subsequent years). On balance, the overall variation in sampling rates/weights at the national level is expected to be lower with a corresponding positive impact on the precision of MEPS estimates. However, with a reduction in the sample sizes of minority households, precision levels of MEPS estimates for Blacks, Hispanics, and Asians may be reduced to some extent. For the calendar year 2017, unlike prior or subsequent data years when both MEPS panels are/will be based on the same NHIS sample design, Panel 21 was based on the 2006 design while Panel 22 was based on the 2016 design. As a result, the 2017 MEPS sample is based on more PSUs than a typical year, serving to increase the precision of 2017 MEPS estimates compared to prior and later years. Also, since the samples selected under the two designs are independent, there are many more degrees of freedom available for variance estimation for MEPS 2017 data, improving the precision of variance estimates. 3.1.3 Sample Weights and Variance EstimationIn the dataset “MEPS HC-198: 2017 Food Security Data File,” a weight variable is provided for generating MEPS estimates of totals, means, percentages, and rates for families in the civilian noninstitutionalized population. Procedures and considerations associated with the construction and interpretation of family estimates using these and other variables are discussed below. 3.2 The MEPS Sampling Process and Response Rates: An OverviewFor most MEPS panels, a sample representing about three-eighths of the NHIS responding households is made available for use in MEPS. This was the case for both MEPS Panel 21 and Panel 22. Because the MEPS subsampling has to be done soon after NHIS responding households are identified, a small percentage of the NHIS households initially characterized as NHIS respondents are later classified as nonrespondents for the purposes of NHIS data analysis. This actually serves to increase the overall MEPS response rate slightly since the percentage of NHIS households designated for use in MEPS (all those characterized initially as respondents from the NHIS panels and quarters used by MEPS for a given year) is slightly larger than the final NHIS household-level response rate and some NHIS nonresponding households do participate in MEPS. However, as a result, these NHIS nonrespondents who are MEPS participants have no NHIS data available to link with MEPS data. Once the MEPS sample is selected from among the NHIS households characterized as NHIS respondents, RUs representing students living in student housing or consisting entirely of military personnel are deleted from the sample. For the NHIS, college students living in student housing are sampled independently from their families. For MEPS, such students are identified through the sample selection of their parents’ RU. Removing from MEPS those college students found in college housing sampled for the NHIS eliminates the opportunity of multiple chances of selection for MEPS for these students. Military personnel not living in the same RU as civilians are ineligible for MEPS. After such exclusions, all RUs associated with households selected from among those identified as NHIS responding households are then fielded in the first round of MEPS. Table 3.1 shows in Rows A, B, and C the three informational components just discussed. Row A indicates the percentage of NHIS households eligible for MEPS. Row B indicates the number of NHIS households sampled for MEPS. Row C indicates the number of sampled households actually fielded for MEPS (after dropping the students and military members discussed above). Note that all response rates discussed here are unweighted.
*Among the panels and quarters of the NHIS allocated to MEPS, the percentage of households that were considered to be NHIS respondents at the time the MEPS sample was selected. 3.2.1 Response RatesIn order to produce annual health care estimates for calendar year 2017 based on the full MEPS sample data from the MEPS Panel 21 and Panel 22, the two panels are combined. More specifically, full calendar year 2017 data collected in Rounds 3 through 5 for the MEPS Panel 21 sample are pooled with data from the first three rounds of data collection for the MEPS Panel 22 sample (the general approach is described below). As mentioned above, all response rates discussed here are unweighted. To understand the calculation of MEPS response rates, some features related to MEPS data collection should be noted. When an RU is visited for a round of data collection, changes in RU membership are identified. Such changes include the formation of student RUs as well as other new RUs created when RU members from a previous round have moved to another location in the U.S. Thus, the number of RUs eligible for MEPS interviewing in a given round is determined after data collection is fully completed. The ratio of the number of RUs completing the MEPS interview in a given round to the number of RUs characterized as eligible to complete the interview for that round represents the “conditional” response rate for that round expressed as a proportion. It is “conditional” in that it pertains to the set of RUs characterized as eligible for MEPS for that round and thus is “conditioned” on prior participation rather than representing the overall response rate through that round. For example, in Table 3.1, for Panel 22 Round 2 the ratio of 7,023 (Row G) to 7,528 (Row F) multiplied by 100 represents the response rate for the round (93.3 percent when computed), conditioned on the set of RUs characterized as eligible for MEPS for that round. Taking the product of the percentage of the NHIS sample eligible for MEPS (Row A) with the product of the ratios for a consecutive set of MEPS rounds beginning with Round 1 produces the overall response rate through the last MEPS round specified. The overall unweighted response rate for the combined sample of Panel 21 and Panel 22 for 2017 was obtained by computing the products of the relative sample sizes and the corresponding overall panel response rates and then summing the two products. Panel 22 represents about 50.0 percent of the combined sample size while Panel 21 represents the remaining 50.0 percent. Thus, the combined response rate of 44.2 percent was computed as 0.500 times 43.8, the overall Panel 21 response rate through Round 5 plus 0.500 times 44.5, the overall Panel 22 response rate through Round 3. 3.2.2 Panel 22 Response RatesFor MEPS Panel 22 Round 1, 9,693 households were fielded in 2017 (Row C of Table 3.1), a randomly selected subsample of the households responding to the 2016 National Health Interview Survey (NHIS). Table 3.1 shows the number of RUs eligible for interviewing in each Round of Panel 22 as well as the number of RUs completing the MEPS interview. Computing the individual round “conditional” response rates as described in section 3.2.1 and then taking the product of these three response rates and the factor 69.2 (the percentage of the NHIS sampled households designated for use in selecting a sample of households for MEPS) yields an overall response rate of 44.5 percent for Panel 22 through Round 3. 3.2.3 Panel 21 Response RatesFor MEPS Panel 21, 9,658 households were fielded in 2016 (as indicated in Row C of Table 3.1), a randomly selected subsample of the households responding to the 2015 National Health Interview Survey (NHIS). Table 3.1 shows the number of RUs eligible for interviewing and the number completing the interview for all five rounds of Panel 21. The overall response rate for Panel 21 was computed in a similar fashion to that of Panel 22 but covering all five rounds of MEPS interviewing as well the factor representing the percentage of NHIS sampled households eligible for MEPS. The overall response rate for Panel 21 through Round 5 is 43.8 percent. 3.2.4 Annual (Combined Panel) Response RateA combined panel response rate for the survey respondents in this data set is obtained by taking a weighted average of the panel specific response rates. The Panel 21 response rate was weighted by a factor of 0.500 and Panel 22 was weighted by a factor of 0.500, reflecting approximately the distribution of the overall sample between the two panels. The resulting combined response rate for the combined panels was computed as (0.500 x 43.8) plus (0.500 x 44.5) or 44.2 percent (as shown in Table 3.1). 3.2.5 OversamplingOversampling is a feature of the MEPS sample design, helping to increase the precision of estimates for some subgroups of interest. Before going into details related to MEPS, the concept of oversampling will be discussed. In a sample where all persons in a population are selected with the same probability and survey coverage of the population is high, the sample distribution is expected to be proportionate to the population distribution. For example, if Hispanics represent 15 percent of the general population, one would expect roughly 15 percent of the persons sampled to be Hispanic. However, in order to improve the precision of estimates for specific subgroups of a population, one might decide to select samples from those subgroups at higher rates than the remainder of the population. Thus, one might select Hispanics at twice the rate (i.e., at double the probability) of persons not oversampled. As a result, an oversampled subgroup comprises a higher proportion of the sample than it represents in the general population. Sample weights ensure that population estimates are not distorted by a disproportionate contribution from oversampled subgroups. Base sample weights for oversampled groups will be smaller than for the portion of the population not oversampled. For example, if a subgroup is sampled at roughly twice the rate of sample selection for the remainder of the population not oversampled, members of the oversampled subgroup will receive base or initial sample weights (prior to nonresponse or poststratification adjustments) that are roughly half the size of the group not oversampled. As mentioned above, oversampling is implemented to increase the sample sizes and thus improve the precision of survey estimates for particular subgroups of the population. The “cost” of oversampling is that the precision of estimates for the general population and subgroups not oversampled will be reduced to some extent compared to the precision one could have achieved if the same overall sample size were selected without any oversampling. The oversampling of Hispanic, Black, and Asian households for the 2015 NHIS carried over to MEPS through the set of NHIS responding households eligible for sample selection for MEPS. In the NHIS under the sample design utilized through 2005, Hispanic households were oversampled at a rate of roughly 2 to 1. That is, the probability of selecting a Hispanic household for participation in the NHIS was roughly twice that for households in the general population that were not oversampled. The oversampling rate for Black households under the old design was roughly 1.5 to 1. Under the NHIS sample design employed through 2015 (this is the sample design applicable to MEPS Panel 21), Asians, as well as Hispanics and Blacks, were oversampled. The average oversampling rates for the three minority groups were not reported. The new NHIS sample design introduced in 2016 (this is the sample design applicable to MEPS Panel 22) discontinued the oversampling of these minority groups. For both Panel 21 and Panel 22, all households in the Asian, Hispanic, and Black domains were sampled with certainty (i.e., all households assigned to those domains were included in the MEPS). For Panel 21, the “Other, complete” domain was sampled at a rate of about 81 percent while the “Other, partial complete” domain was sampled at a rate of about 49 percent. For Panel 22, the corresponding sampling rates for the “Other, complete” domain and the “Other, partial complete” domain were about 77 percent and 49 percent, respectively. Within strata (domains) for both panels, responding NHIS households were selected for MEPS using a systematic sample selection procedure from among those eligible. For the “non-Other” strata households were all selected with certainty. Within strata involving “Others” (two strata for both panels) the selection was with probability proportionate to size (pps) where the size measure was the inverse of the NHIS initial probability of selection. The pps sampling was undertaken to help reduce the variability in the MEPS weights incurred due to the variability of the NHIS sampling rates. With the subsampling, households that were oversampled for MEPS in calendar year 2017 were those responding households in the NHIS identified as having members whose race/ethnicity was Hispanic, Black, or Asian for both panels. Typically, sample allocations across sample domains change from one MEPS panel to another. The sample domains used may also vary by panel although this was not the case for Panel 21 and Panel 22. When one compares unweighted measures (e.g., response rates) between panels and years, one should take into account such differences. Suppose, for example, members of one domain have a lower propensity to respond than those of another domain. Then if that domain has been allocated a higher proportion of the sample, the corresponding panel may have a lower unweighted response rate simply because of the differences in sample allocation. Within each domain (sample stratum) systematic samples of the MEPS-eligible households were selected from among the NHIS household respondents made available for MEPS sample selection purposes. 3.3 Food Security Weight (FSWT42)The Food Security questionnaire was administered to RU level respondents in Round 4 of Panel 21 and Round 2 of Panel 22. A family weight specific to Rounds 4/2, FSWT42, was created for the purposes of analyzing the Food Security questionnaire data. To create FSWT42, first those RUs that were MEPS respondents in Round 4/2 were identified. The MEPS family weight (FAMWT17F) from the 2017 full year Consolidated data file of the RU reference person was then assigned as the family weight of the RU. A small number of RUs (less than 2 percent) had a reference person with no MEPS family weight in the Consolidated data file because at least one member of the family became a nonrespondent for MEPS in the subsequent round. For these RUs, the reference person’s full-year person weight was assigned as the family weight. The reference person of the RU in MEPS is defined as the household member 16 years of age or older who own or rents the home. Note that there are two different family weights provided in the 2017 Full Year Consolidated PUF: the MEPS family weight, FAMWT17F; and the family weight based on the Current Population Survey (CPS) definition of a family, FAMWT17C. The MEPS family weight (FAMWT17F) was used for the food security data because the MEPS family weight definition of family was closest to the MEPS Round 4/2 RU definition. For more information on the derivation of FAMWT17F and FAMWT17C, see the MEPS HC-201, 2017 Full Year Consolidated Data File Documentation. Table 3.2 shows the number of families in the food security data file by panel and the weighted total number of the families.
3.4 Variance EstimationThe MEPS is based on a complex sample design. To obtain estimates of variability (such as the standard error of sample estimates or corresponding confidence intervals) for MEPS estimates, analysts need to take into account the complex sample design of MEPS for both person-level and family-level analyses. Several methodologies have been developed for estimating standard errors for surveys with a complex sample design, including the Taylor-series linearization method, balanced repeated replication, and jackknife replication. Various software packages provide analysts with the capability of implementing these methodologies. MEPS analysts most commonly use the Taylor Series approach. However, an option is also provided to apply the BRR approach when needed to develop variances for more complex estimators. 3.4.1 Taylor-series Linearization MethodThe variables needed to calculate appropriate standard errors based on the Taylor-series linearization method are included on this and all other MEPS public use files. Software packages that permit the use of the Taylor-series linearization method include SUDAAN, Stata, SAS (version 8.2 and higher), and SPSS (version 12.0 and higher). For complete information on the capabilities of each package, analysts should refer to the corresponding software user documentation. Using the Taylor-series linearization method, variance estimation strata and the variance estimation PSUs within these strata must be specified. The variables VARSTR and VARPSU on this MEPS data file serve to identify the sampling strata and primary sampling units required by the variance estimation programs. Specifying a “with replacement” design in one of the previously mentioned computer software packages will provide estimated standard errors appropriate for assessing the variability of MEPS survey estimates. It should be noted that the number of degrees of freedom associated with estimates of variability indicated by such a package may not appropriately reflect the number available. For variables of interest distributed throughout the country (and thus the MEPS sample PSUs), one can generally expect to have at least 100 degrees of freedom associated with the estimated standard errors for national estimates based on this MEPS database. Prior to 2002, MEPS variance strata and PSUs were developed independently from year to year, and the last two characters of the strata and PSU variable names denoted the year. However, beginning with the 2002 Point-in-Time PUF, the variance strata and PSUs were developed to be compatible with all future PUFs until the NHIS design changed. Thus, when pooling data across years 2002 through the Panel 11 component of the 2007 files, the variance strata and PSU variables provided can be used without modification for variance estimation purposes for estimates covering multiple years of data. There were 203 variance estimation strata, each stratum with either two or three variance estimation PSUs. From Panel 12 of the 2007 files, a new set of variance strata and PSUs were developed because of the introduction of a new NHIS design. There are 165 variance strata with either two or three variance estimation PSUs per stratum starting from Panel 12. Therefore, there are a total of 368 (203+165) variance strata in the 2007 Full Year file as it consists of two panels that were selected under two independent NHIS sample designs. Since both MEPS panels in the Full Year files from 2008 through 2016 were based on the next NHIS design, there are only 165 variance strata. These variance strata (VARSTR values) have been numbered from 1001 to 1165 so that they can be readily distinguished from those developed under the former NHIS sample design in the event that data are pooled for several years. As discussed, the most recent change in the NHIS sample design took place in 2016, effectively changing the MEPS design beginning with calendar year 2017, where Panel 22 is based on the new NHIS design while Panel 21 is based on the old one. There were 117 variance strata formed for Panel 22. With the 165 available from Panel 21, there are a total of 282 variance strata appearing on the 2017 Full Year PUF. In order to make the pooling of data across multiple years of MEPS more straightforward, the numbering system for the variance strata has changed. Those strata associated with the new design will have four digit values with a “2” as the first digit. Those associated with the previous design will have “1” as the first of four digits. To ensure that variance strata are identified appropriately for variance estimation purposes when pooling MEPS data across several years, one can proceed as follows:
3.4.2 Balanced Repeated Replication (BRR) MethodBRR replicate weights are not provided on this MEPS PUF for the purposes of variance estimation. However, a file containing a BRR replication structure is made available so that the users can form replicate weights, if desired, from the final MEPS weight to compute variances of MEPS estimates using either BRR or Fay’s modified BRR (Fay 1989) methods. The replicate weights are useful to compute variances of complex non-linear estimators for which a Taylor linear form is not easy to derive and not available in commonly used software. For instance, it is not possible to calculate the variances of a median or the ratio of two medians using the Taylor linearization method. For these types of estimators, users may calculate a variance using BRR or Fay’s modified BRR methods. However, it should be noted that the replicate weights have been derived from the final weight through a shortcut approach. Specifically, the replicate weights are not computed starting with the base weight and all adjustments made in different stages of weighting are not applied independently in each replicate. So the variances computed using this one-step BRR do not capture the effects of all weighting adjustments that would be captured in a set of full developed BRR replicate weights. The Taylor Series approach does not fully capture the effects of the different weighting adjustments either. The dataset HC-036BRR contains the information necessary to construct the BRR replicates. It contains a set of 128 flags (BRR1—BRR128) in the form of half sample indicators, each of which is coded 0 or 1 to indicate whether the person should or should not be included in that particular replicate. These flags can be used in conjunction with the full-year weight to construct the BRR replicate weights. For analysis of MEPS data pooled across years, the BRR replicates can be formed in the same way using the HC-036 file. For more information about creating BRR replicates, users can refer to the documentation for the HC-036BRR pooled linkage file. D. Variable-Source CrosswalkVARIABLE-SOURCE CROSSWALK
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||