|
|
|
Font Size:
|
||||
|
|
|
|
||||
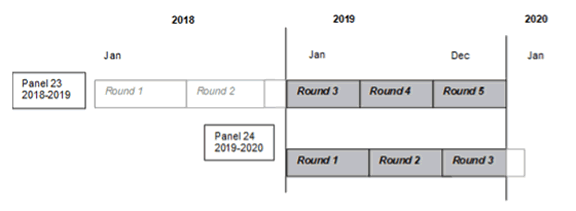
MEPS HC-216 2019 Full Year Consolidated Data FileAugust 2021 Agency for Healthcare Research and Quality A. Data Use Agreement A. Data Use AgreementIndividual identifiers have been removed from the micro-data contained in these files. Nevertheless, under sections 308 (d) and 903 (c) of the Public Health Service Act (42 U.S.C. 242m and 42 U.S.C. 299 a-1), data collected by the Agency for Healthcare Research and Quality (AHRQ) and/or the National Center for Health Statistics (NCHS) may not be used for any purpose other than for the purpose for which they were supplied; any effort to determine the identity of any reported cases is prohibited by law. Therefore in accordance with the above referenced Federal Statute, it is understood that:
By using these data you signify your agreement to comply with the above stated statutorily based requirements with the knowledge that deliberately making a false statement in any matter within the jurisdiction of any department or agency of the Federal Government violates Title 18 part 1 Chapter 47 Section 1001 and is punishable by a fine of up to $10,000 or up to 5 years in prison. The Agency for Healthcare Research and Quality requests that users cite AHRQ and the Medical Expenditure Panel Survey as the data source in any publications or research based upon these data. B. Background1.0 Household ComponentThe Medical Expenditure Panel Survey (MEPS) provides nationally representative estimates of health care use, expenditures, sources of payment, and health insurance coverage for the U.S. civilian noninstitutionalized population. The MEPS Household Component (HC) also provides estimates of respondents’ health status, demographic and socio-economic characteristics, employment, access to care, and satisfaction with health care. Estimates can be produced for individuals, families, and selected population subgroups. The panel design of the survey, which includes 5 Rounds of interviews covering 2 full calendar years, provides data for examining person level changes in selected variables such as expenditures, health insurance coverage, and health status. Using computer assisted personal interviewing (CAPI) technology, information about each household member is collected, and the survey builds on this information from interview to interview. All data for a sampled household are reported by a single household respondent. The MEPS HC was initiated in 1996. Each year a new panel of sample households is selected. Because the data collected are comparable to those from earlier medical expenditure surveys conducted in 1977 and 1987, it is possible to analyze long-term trends. Each annual MEPS HC sample size is about 15,000 households. Data can be analyzed at either the person or event level. Data must be weighted to produce national estimates. The set of households selected for each panel of the MEPS HC is a subsample of households participating in the previous year’s National Health Interview Survey (NHIS) conducted by the National Center for Health Statistics. The NHIS sampling frame provides a nationally representative sample of the U.S. civilian noninstitutionalized population. In 2006, the NHIS implemented a new sample design, which included Asian persons in addition to households with Black and Hispanic persons in the oversampling of minority populations. NHIS introduced a new sample design in 2016 that discontinued oversampling of these minority groups. The linkage of the MEPS to the previous year’s NHIS provides additional data for longitudinal analytic purposes. 2.0 Medical Provider ComponentUpon completion of the household CAPI interview and obtaining permission from the household survey respondents, a sample of medical providers are contacted by telephone to obtain information that household respondents can not accurately provide. This part of the MEPS is called the Medical Provider Component (MPC) and information is collected on dates of visits, diagnosis and procedure codes, charges and payments. The Pharmacy Component (PC), a subcomponent of the MPC, does not collect charges or diagnosis and procedure codes but does collect drug detail information, including National Drug Code (NDC) and medicine name, as well as amounts of payment. The MPC is not designed to yield national estimates. It is primarily used as an imputation source to supplement/replace household reported expenditure information. 3.0 Survey Management and Data CollectionMEPS HC and MPC data are collected under the authority of the Public Health Service Act. Data are collected under contract with Westat, Inc. (MEPS HC) and Research Triangle Institute (MEPS MPC). Data sets and summary statistics are edited and published in accordance with the confidentiality provisions of the Public Health Service Act and the Privacy Act. The National Center for Health Statistics (NCHS) provides consultation and technical assistance. As soon as data collection and editing are completed, the MEPS survey data are released to the public in staged releases of summary reports, micro data files, and tables via the MEPS website. Additional information on MEPS is available from the MEPS project manager or the MEPS public use data manager at the Center for Financing, Access, and Cost Trends, Agency for Healthcare Research and Quality, 5600 Fishers Lane, Rockville, MD 20857 (301-427-1406). C. Technical and Programming Information1.0 General InformationThis documentation describes the 2019 full-year consolidated data file from the Medical Expenditure Panel Survey Household Component (MEPS HC). Released as an ASCII file (with related SAS, Stata, SPSS, and R programming statements and data user information),a SAS data set, a SAS transport dataset, a Stata data set, and an Excel file this public use file provides information collected on a nationally representative sample of the civilian noninstitutionalized population of the United States for calendar year 2019. The file contains 1,447 variables and has a logical record length of 4,202 with an additional 2-byte carriage return/line feed at the end of each record. This file consists of MEPS survey data obtained in Rounds 3, 4, and 5 of Panel 23 and Rounds 1, 2, and 3 of Panel 24, the rounds for the MEPS panels covering calendar year 2019, and contains variables pertaining to survey administration, demographics, income, person-level conditions, health status, disability days, quality of care, employment, health insurance, and person-level medical care use and expenditures. The following documentation offers a brief overview of the types and levels of data provided, content and structure of the files, and programming information. It contains the following sections:
Both weighted and unweighted frequencies of most variables included in the 2019 full-year consolidated data file are provided in the accompanying codebook file. The exceptions to this are weight variables, variance estimation variables, and variables that have a separate weight (SAQ, DCS, and VSAQ). Only unweighted frequencies of these variables are included in the accompanying codebook file. See the Weights Variables list in Section D, Variable-Source Crosswalk. A database of all MEPS products released to date and a variable locator indicating the major MEPS data items on public use files that have been released to date can be found on the MEPS website. 2.0 Data File InformationThis public use dataset contains variables and frequency distributions associated with 28,512 persons who participated in the MEPS Household Component of the Medical Expenditure Panel Survey in 2019. These persons received a positive person-level weight, a family-level weight, or both (some participating persons belonged to families characterized as family-level nonrespondents while some members of participating families were not eligible for a person-level weight). These 28,512 persons were part of one of the two MEPS panels for whom data were collected in 2019: Rounds 3, 4, and 5 of Panel 23 or Rounds 1, 2, and 3 of Panel 24. Of these persons, 27,648 were assigned a positive person-level weight. There were 11,924 families receiving a positive family-level weight. The codebook provides both weighted and unweighted frequencies for most variables on the dataset. In conjunction with the person-level weight variable (PERWT19F) provided on this file, data for persons with a positive person-level weight can be used to make estimates for the civilian noninstitutionalized U.S. population for 2019. The MEPS CAPI design has changed significantly beginning with the specifications for Panel 21 Round 5/Panel 22 Round 3/Panel 23 Round 1. 2.1 Codebook StructureThe codebook and data file sequence lists variables in the following order:
2.2 Reserved Codes
The value -15 (CANNOT BE COMPUTED) is assigned to MEPS constructed variables in cases where there is not enough information from the MEPS instrument to calculate the constructed variables. “Not enough information” is often the result of skip patterns in the data or from missing information resulting from MEPS responses of -7 (REFUSED) or -8 (DK). Note that reserved code -8 includes cases where the information from the question was “not ascertained” or where the respondent chose “don’t know”. 2.3 Codebook Format
2.4 Variable NamingIn general, variable names reflect the content of the variable. Edited variables end in an X and are so noted in the variable label. The last two characters in round-specific variables denote the rounds of data collection, Round 3, 4, or 5 of Panel 23 and Round 1, 2, or 3 of Panel 24. Unless otherwise noted, variables that end in “19” represent status as of December 31, 2019. Beginning in 2018, as variable collection, universe, or categories are altered, the variable name will be appended with “_Myy” to indicate in which year the alterations took place. Details about these alterations can be found throughout this document. Variables contained in this delivery were derived either from the questionnaire itself or from the CAPI. The source of each variable is identified in the section of the documentation entitled “Section D. Variable-Source Crosswalk.” Sources for each variable are indicated in one of four ways: (1) variables derived from CAPI or assigned in sampling are so indicated; (2) variables derived from complex algorithms associated with reenumeration are labeled “RE Section”; (3) variables that are collected by one or more specific questions in the instrument have those question numbers listed in the Source column; and (4) variables constructed from multiple questions using complex algorithms are labeled “Constructed.” 2.5 File ContentsUsers of MEPS data should be aware that the survey collects data for all sample persons who were in the survey target population at any time during the survey period. In other words, a small proportion of individuals in MEPS analytic files are not members of the survey target population (i.e., civilian noninstitutionalized) for the entire survey period. These persons include those who had periods during which they lived in an institution (e.g., nursing home or prison), were in the military, or lived out of the country, as well as those who were born (or adopted) into MEPS sample households or died during the year. They are considered sample persons for the survey and are included in MEPS data files with positive person weights, but no data were collected for the periods they were not inscope and their annual data for variables like health care utilization, expenditures, and insurance coverage reflect only the part of the year they were inscope for the survey. Persons who are inscope for only part of the year should not be confused with non-respondents. Sample persons who are classified as non-respondents to one or more rounds of data collection (i.e., initial non-respondents and dropouts over time) are not included in MEPS annual files, and survey weights for full-year respondents are inflated through statistical adjustment procedures to compensate for both full and part-year nonresponse (see Section 3.0 “Survey Sample Information” for more information). The AHRQ website provides more details about the identification and analytic considerations regarding sample persons who are inscope only part of the year. 2.5.1 Survey Administration Variables (DUID -RURSLT53)The survey administration variables contain information related to conducting the interview, household and family composition, and person-level and RU-level status codes. Data for the survey administration variables were derived from the sampling process, the CAPI programs, or were computed based on information provided by the respondent in the Reenumeration section of the questionnaire. Most survey administration variables on this file are asked during every round of the MEPS interview. They describe data for Rounds 3/1, 4/2, 5/3 status and status as of December 31, 2019. Variable names ending in “xy” represent variables relevant to Round “x” of Panel 23 or Round “y” of Panel 24. For example, RULETR53 is a variable relevant to Round 5 of Panel 23 or Round 3 of Panel 24, depending on the panel in which the person was included. The variable PANEL indicates the panel in which the person participated. The December 31, 2019 variables were developed in two ways. Those used in the construction of eligibility, inscope, and the end reference date were based on an exact date. The remaining variables were constructed using data from specific rounds, if available. If data were missing from the target round but were available in another round, data from that other round were used in the variable construction. If no valid data were available during any round of data collection, an appropriate reserved code was assigned. Dwelling Units, Reporting Units, and Families The definitions of Dwelling Units (DUs) in the MEPS Household Survey are generally consistent with the definitions employed for the National Health Interview Survey (NHIS). The Dwelling Unit ID (DUID) is a seven-digit ID number consisting of a 2-digit panel number followed by a five-digit random number assigned after the case was sampled for MEPS. A three-digit person number (PID) uniquely identifies each person within the DU. The variable DUPERSID is the combination of the variables DUID and PID. As part of the new CAPI design, the lengths of the ID variables have changed in the file. The additional 2 bytes in the IDs resulted from adding a 2-digit panel number to the beginning of all the IDs. PANEL is a constructed variable used to specify the panel number for the person. PANEL will indicate either Panel 23 or Panel 24 for each person on the file. Panel 23 is the panel that started in 2018, and Panel 24 is the panel that started in 2019. Beginning in 2018, the panel number is included as the first two digits of the DUID and DUPERSID. A Reporting Unit (RU) is a person or group of persons in the sampled DU who are related by blood, marriage, adoption, or other family association. Each RU was interviewed as a single entity for MEPS. Thus, the RU serves chiefly as a family-based “survey” operations unit rather than an analytic unit. Members of each RU within the DU are identified in the pertinent three rounds by the round-specific variables RULETR31, RULETR42, and RULETR53. End-of-year status (as of December 31, 2019 or the last round they were in the survey) is indicated by the RULETR19 variable. Regardless of the legal status of their association, two persons living together as a “family” unit were treated as a single RU if they chose to be so identified. Examples of different types of RUs are:
Unmarried college students (less than 24 years of age) who usually live in the sampled household but were living away from home and going to school at the time of the Round 3/1 MEPS interview were treated as an RU separate from that of their parents for the purpose of data collection. The round-specific variables RUSIZE31, RUSIZE42, RUSIZE53, and the end-of-year status variable RUSIZE19 indicate the number of persons in each RU, treating students as single RUs separate from their parents. Thus, students are not included in the RUSIZE count of their parents’ RU. However, for many analytic objectives, the student RUs would be combined with their parents’ RU, treating the combined entity as a single family. Family identifier and size variables are described below and include students with their parents’ RU. The round-specific variables FAMID31, FAMID42, FAMID53, and the end-of-year status variable FAMID19 identify a family (i.e., persons related to one another by blood, marriage, adoption, or self-identified as a single unit) for each round and as of December 31, 2019. The FAMID variables differ from the RULETR variables only in that student RUs are combined with their parents’ RU. Two other family identifiers, FAMIDYR and CPSFAMID, are provided on this file. The annualized family ID letter, FAMIDYR, identifies eligible members of the eligible annualized families within a DU. The CPSFAMID represents a redefinition of MEPS families into families defined by the Current Population Survey (CPS). Some of the distinctions between CPS-and MEPS-defined families are that MEPS families include and CPS families do not include: non-married partners, and in-laws. These persons are considered as members of separate families for CPS-like families. CPS-like families are defined so a poverty status classification variable consistent with established definitions of poverty can be assigned to the CPS-like families and used for weight poststratification purposes. In order to identify a person’s family affiliation, users must create a unique set of FAMID variables by concatenating the DU identifier and the FAMID variable. Instructions for creating family estimates are described in Section 3.5. Beginning with the 2017 Consolidated Public Use File, foster care relationships and fostered members of households are not included in MEPS data. The round-specific variables FAMSZE31, FAMSZE42, FAMSZE53, and the end-of-year status variable FAMSZE19 indicate the number of persons associated with a single family unit after students are linked to their associated parent RUs for analytical purposes. Family-level analyses should use the FAMSZE variables. Note that the variables RUSIZE31, RUSIZE42, RUSIZE53, RUSIZE19, FAMSZE31, FAMSZE42, FAMSZE53, and FAMSZE19 exclude persons who are ineligible for data collection (i.e., those where ELGRND31 NE 1, ELGRND42 NE 1, ELGRND53 NE 1 or ELGRND19 NE 1); analysts should exclude ineligible persons in a given round from all family-level analyses for that round. The round-specific variables RURSLT31, RURSLT42, and RURSLT53 indicate the RU response status for each round. Users should note that the values for RURSLT31 differ from those for RURSLT42 and RURSLT53.
Standard or primary RUs are the original RUs from NHIS. A new RU is one created when members of the household leave the primary RU and are followed according to the rules of the survey. A student RU is an unmarried college student (under 24 years of age) who is considered a usual member of the household, but was living away from home while going to school, and was treated as a Reporting Unit (RU) separate from his or her parents’ RU for the purpose of data collection. RUCLAS19 was set based on the RUCLAS values from Rounds 3/1, 4/2, and 5/3. If the person was present in the responding RU in Round 5/3, then RUCLAS19 was set to RUCLAS53. If the person was not present in a responding RU in Round 5/3 but was present in Round 4/2, then RUCLAS19 was set to RUCLAS42. If the person was not present in either Rounds 4/2 or 5/3 but was present in Round 3/1, then RUCLAS19 was set to RUCLAS31. If the person was not linked to a responding RU during any round, then RUCLAS19 was set to -15. Geographic Variables The round-specific variables REGION31, REGION42, REGION53, and the end-of-year status variable REGION19 indicate the Census region for the RU. REGION19 indicates the region for the 2019 portion of Round 5/3. For most analyses, REGION19 should be used.
Reference Period Dates The reference period is the period of time for which data were collected in each round for each person. The reference period dates were determined during the interview for each person by the CAPI program. The round-specific beginning reference period dates are included for each person. These variables include BEGRFM31, BEGRFY31, BEGRFM42, BEGRFY42, BEGRFM53, and BEGRFY53. The reference period for Round 1 for most persons began on January 1, 2019 and ended on the date of the Round 1 interview. For RU members who joined later in Round 1, the beginning Round 1 reference date was the date the person entered the RU. For all subsequent rounds, the reference period for most persons began on the date of the previous round’s interview and ended on the date of the current round’s interview. Persons who joined after the previous round’s interview had their beginning reference date for the round set to the day they joined the RU. The round-specific ending reference period dates for Rounds 3/1, 4/2, and 5/3 as well as the end-of-year reference period end date variables are also included for each person. These variables include ENDRFM31, ENDRFY31, ENDRFM42, ENDRFY42, ENDRFM53, ENDRFY53, ENDRFM19, and ENDRFY19. For most persons in the sample, the date of the round’s interview is the reference period end date. Note that the end date of the reference period for a person is prior to the date of the interview if the person was deceased during the round, left the RU, was institutionalized prior to that round’s interview, or left the RU to join the military. For a small number of cases, the reference period dates may be recoded for confidentiality. Reference Person Identifiers The round-specific variables REFPRS31, REFPRS42, and REFPRS53 and the end-of-year status variable REFPRS19 identify the reference person for Rounds 3/1, 4/2 and 5/3, and as of December 31, 2019 (or the last round they were in the survey). In general, the reference person is defined as the household member 16 years of age or older who owns or rents the home. If more than one person meets this description, the household respondent identifies one from among them. If the respondent is unable to identify a person fitting this definition, the questionnaire asks for the head of household and this person is then considered the reference person for that RU. This information is collected in the Reenumeration section of the CAPI questionnaire. Respondent Identifiers The respondent is the person who answered the interview questions for the Reporting Unit (RU). The round-specific variables RESP31, RESP42, and RESP53 and the end-of-year status variable RESP19 identify the respondent for Rounds 3/1, 4/2, and 5/3 and as of December 31, 2019 (or the last round they were in the survey). Only one respondent is identified for each RU. In instances where the interview was completed in more than one session, only the first respondent is indicated. There are two types of respondents. The respondent can be either an RU member or a non-RU member proxy. The round-specific variables PROXY31, PROXY42, and PROXY53 and the end-of-year status variable PROXY19 identify the type of respondent for Rounds 3/1, 4/2, 5/3 and as of December 31, 2019 (or the last round they were in the survey). Language of Interview The language of interview variable (INTVLANG) is a summary value of the round-specific RU-level information section question (RU30), which asks the interviewer to record the language in which the interview was completed: English, Spanish, Both English and Spanish, Other Language. Given the first round that the person was part of the study and the person’s associated RU for that round, INTVLANG is assigned the interview language value reported for the person’s RU for the round. Person Status A number of variables describe the various components reflecting each person’s status for each round of data collection. These variables provide information about a person’s in-scope status, Keyness status, eligibility status, and disposition status. These variables include: KEYNESS, INSCOP31, INSCOP42, INSCOP53, INSCOP19, INSC1231, INSCOPE, ELGRND31, ELGRND42, ELGRND53, ELGRND19, PSTATS31, PSTATS42, and PSTATS53. These variables are set based on sampling information and responses provided in the reenumeration section of the CAPI questionnaire. Through the Reenumeration section of the CAPI questionnaire, each member of an RU was classified as “Key” or “Non-Key”, “in-scope” or “out-of-scope”, and “eligible” or “ineligible” for MEPS data collection. To be included in the set of persons used in the derivation of MEPS person-level estimates, a person had to be a member of the civilian noninstitutionalized population for at least one day during 2019. Because a person’s eligibility for the survey might have changed since the NHIS interview, a sampling Reenumeration of household membership was conducted at the start of each round’s interview. Only persons who were “inscope” sometime during the year, were “Key”, and responded for the full period in which they were inscope were assigned positive person-level weights and thus are to be used in the derivation of person-level national estimates from the MEPS. Note: If analysts want to subset to infants born during 2019, then newborns should be identified using AGE19X = 0 rather than PSTATSxy = 51. Inscope The round-specific variables INSCOP31, INSCOP42, and INSCOP53 indicate a person’s in-scope status for Rounds 3/1, 4/2, and 5/3. INSCOP19, INSC1231, and INSCOPE indicate a person’s in-scope status for the portion of Round 5/3 that covers 2019, the person’s in-scope status as of 12/31/19, and whether a person was ever in-scope during the calendar year 2019. A person was considered as in-scope during a round or a referenced time period if he or she was a member of the U.S. civilian, noninstitutionalized population at some time during that round or that time period. The values of these variables taken in conjunction allow one to determine in-scope status over time (for example, becoming inscope in the middle of a round, as would be the case for newborns).
Keyness The term “Keyness” is related to an individual’s chance of being included in MEPS. A person is Key if that person is linked for sampling purposes to the set of NHIS sampled households designated for inclusion in MEPS. Specifically, a Key person was either a member of a responding NHIS household at the time of interview, or joined a family associated with such a household after being out-of-scope at the time of the NHIS (examples of the latter situation include newborns and those returning from military service, an institution, or residence in a foreign country). A non-Key person is one whose chance of selection for the NHIS (and MEPS) was associated with a household eligible but not sampled for the NHIS and who later became a member of a MEPS Reporting Unit. MEPS data (e.g., utilization and expenditures) were collected for the period of time a non-Key person was part of the sampled unit to provide information for family-level analyses. However, non-Key persons who leave a sample household unaccompanied by a Key, in-scope member were not followed for subsequent interviews. Non-Key individuals do not receive sample person-level weights and thus do not contribute to person-level national estimates. The variable KEYNESS indicates a person’s Keyness status. This variable is not round-specific. Instead, it is set at the time the person enters MEPS, and the person’s Keyness status never changes. Once a person is determined to be Key, that person will always be Key. It should be pointed out that a person might be Key even though not part of the civilian, noninstitutionalized portion of the U.S. population. For example, a person in the military may have been living with his or her civilian spouse and children in a household sampled for NHIS. The person in the military would be considered a Key person for MEPS; however, such a person would not be eligible to receive a person-level sample weight if he or she was never inscope during 2019. Eligibility The eligibility of a person for MEPS pertains to whether or not data were to be collected for that person. All of the Key in-scope persons of a sampled RU were eligible for data collection. The only non-Key persons eligible for data collection were those who happened to be living in an RU with at least one Key, in-scope person. Their eligibility continued only for the time that they were living with at least one such person. The only out-of-scope persons eligible for data collection were those who were living with Key in-scope persons, again only for the time they were living with such a person. Only military persons can meet this description (for example, a person on full-time active duty military, living with a spouse who is Key). A person may be classified as eligible for an entire round or for some part of a round. For persons who are eligible for only part of a round (for example, persons may have been institutionalized during a round), data were collected for the period of time for which that person was classified as eligible. The round-specific variables ELGRND31, ELGRND42, ELGRND53 and the end-of-year status variable ELGRND19 indicate a person’s eligibility status for Rounds 3/1, 4/2, and 5/3 and as of December 31, 2019. Person Disposition Status The round-specific variables PSTATS31, PSTATS42, and PSTATS53 indicate a person’s response and eligibility status for each round of interviewing. The PSTATSxy variables indicate the reasons for either continuing or terminating data collection for each person in the MEPS. Using this variable, one could identify persons who moved during the reference period, died, were born, institutionalized, or who were in the military. Analysts should note that PSTATS53 provides a summary for all of Round 5/3, including transitions that occurred after 2019. Note that some categories may be collapsed for confidentiality purposes.
2.5.2 Navigating the MEPS Data with Information on Person Disposition StatusSince the variables PSTATS31, PSTATS42, and PSTATS53 indicate the reasons for either continuing or terminating data collection for each person in MEPS, these variables can be used to explain the beginning and ending dates for each individual’s reference period of data collection, as well as which sections in the instrument each individual did not receive. By using the information included in the following table, analysts will be able to determine for each individual which sections of the MEPS questionnaire collected data elements for that person. Some individuals have a reference period that spans an entire round, while other individuals may have data collected only for a portion of the round. When an individual’s reference period does not coincide with the RU reference period, the individual’s start date may be a later date, or the end date may be an earlier date, or both. In addition, some individuals have reference period information coded as “Inapplicable” (e.g., for individuals who were not actually in the household). The information in this table indicates the beginning and ending dates of reference periods for persons with various values of PSTATS31, PSTATS42, and PSTATS53. The actual dates for each individual can be found in the following variables included on this file: BEGRFM31, BEGRFM42, BEGRFM53, BEGRFY31, BEGRFY42, BEGRFY53, ENDRFM31, ENDRFM42, ENDRFM53, ENDRFY31, ENDRFY42, ENDRFY53, ENDRFM19, and ENDRFY19. The table below also describes the section or sections of the questionnaire that were NOT asked for each value of PSTATS31, PSTATS42, and PSTATS53. For example, the Closing (CL) section contains some questions or question rosters that exclude certain persons depending on whether the person died, became institutionalized, or otherwise left the RU; however, no one is considered to have skipped the entire section. Some questions or sections (e.g., Health Status (HE), Employment (RJ, EM, EW)) are skipped if individuals are not within a certain age range. Since the PSTATS variables do not address skip patterns based on age, analysts will need to use the appropriate age variables. The paper-and-pencil Self-Administered Questionnaire (SAQ) was designed to collect information during Panel 24 Round 2 and Panel 23 Round 4. A person was considered eligible to receive an SAQ if that person did not have a status of deceased or institutionalized, did not move out of the U.S. or to a military facility, was not a non-response at the time of the Round 2 or Round 4 interview date, and was 18 years of age or older. No RU members added in Round 3 or Round 5 were asked to complete an SAQ questionnaire. Because PSTATS variables do not address skip patterns based on age, this questionnaire was not included in the table below. Once again, analysts will need to use the appropriate age variable, which in this case would be AGE42X. The documentation for this questionnaire appears in the SAQ section of this document under “Health Status Variables.”
2.5.3 Demographic Variables (AGE31X-DAPID53X)General Information Demographic variables provide information about the demographic characteristics of each person from the MEPS HC. The characteristics include age, sex, race, ethnicity, marital status, educational attainment, and military service. As noted below, some variables have edited and imputed values. Most demographic variables on this file were asked during every round of the MEPS interview. These variables describe data for Rounds 3, 4, and 5 of Panel 23 (the panel that started in 2018); Rounds 1, 2 and 3 of Panel 24 (the panel that started in 2019); and status as of December 31, 2019. Demographic variables that are round-specific are identified by names including numbers “xy”, where x and y refer to round numbers of Panel 23 and Panel 24 respectively. For example, AGE31X represents the age data relevant to Round 3 of Panel 23 or Round 1 of Panel 24. As mentioned in Section 2.5.1 “Survey Administration Variables”, the variable PANEL indicates the panel from which the data were derived. A value of 23 indicates Panel 23 data and a value of 24 indicates Panel 24 data. The remaining demographic variables on this file are not round-specific. The variables describing demographic status of the person as of December 31, 2019 were developed in two ways. First, the age variable (AGE19X) represents the exact age, calculated from date of birth and indicates age status as of 12/31/19. For the remaining December 31st variables [i.e., related to marital status (MARRY19X, SPOUID19, SPOUIN19), student status (FTSTU19X), and the relationship to reference persons (REFRL19X)], the following algorithm was used: data were taken from the Round 5/3 counterpart if non-missing; else, if missing, data were taken from the Round 4/2 counterpart; else from the Round 3/1 counterpart. If no valid data were available during any of these rounds of data collection, the algorithm assigned the missing value (other than -1 “Inapplicable”) from the first round that the person was part of the study. When all three rounds were set to -1, a value of -15 “Cannot be Computed” was assigned. Age Date of birth and age for each RU member were asked or verified during each MEPS interview (DOBMM, DOBYY, AGE31X, AGE42X, AGE53X). If date of birth was available, age was calculated based on the difference between date of birth and date of interview. Inconsistencies between the calculated age and the age reported during the CAPI interview were reviewed and resolved. For purposes of confidentiality, the variables AGE31X, AGE42X, AGE53X, AGE19X, and AGELAST were top-coded at 85 years. When date of birth was not provided but age was provided (either from the MEPS interviews or the 2017-2018 NHIS data), the month and year of birth were assigned randomly from among the possible valid options. For any cases still not accounted for, age was imputed using:
For example, a mother’s age is imputed as her child’s age plus 26, where 26 is the mean age difference between MEPS mothers and their children. A wife’s age is imputed as the husband’s age minus 3, where 3 is the mean age difference between MEPS wives and husbands. Age was imputed in this way for 10 persons on this file. Age was determined for no additional persons from data in a later round. AGELAST indicates a person’s age from the last time the person was eligible for data collection during a specific calendar year. The age range for this variable is between 0 and 85. Sex Data on the sex of each RU member (SEX) were initially determined from the 2017 NHIS for Panel 23 and from the 2018 NHIS for Panel 24. The SEX variable was verified and, if necessary, corrected during each MEPS interview. The data for new RU members (persons who were not members of the RU at the time of the NHIS interviews) were also obtained during each MEPS round. When sex of the RU member was not available from the NHIS interviews and was not determined during one of the subsequent MEPS interviews, it was assigned in the following way. The person’s first name was used to assign sex if obvious (no cases were resolved in this way). If the person’s first name provided no indication of sex, then family relationships were reviewed (no cases were resolved this way). If neither of these approaches made it possible to determine the individual’s sex, sex was randomly assigned (no cases were resolved this way). Race and Ethnicity Group The race and the ethnic background questions were asked for each RU member during the MEPS interview. If the information was not obtained in Round 1, the questions were asked in subsequent rounds. It should be noted that race/ethnicity questions in the MEPS were revised starting with data collection in 2013 for Panel 16 Round 5, Panel 17 Round 3, and Panel 18 Round 1; this affected data starting with the FY 2012 file. Previously, there were two race questions, but starting with data collection in 2013, there is only one race question. All Asian categories listed in the second question were moved to the new single question. In addition, the new race question had additional detail for the Native Hawaiian and Other Pacific Islander categories. The main change for ethnicity is that the new questions allowed respondents to report more than one Hispanic ethnicity. Race/ethnicity data from earlier years may not be directly comparable. The following table shows the variables used for FY 2002-2011 and FY 2012-2019, with these exceptions: 1) in FY 2012, RACEV1X categories 4 and 5 were not combined but are combined starting with 2013, and 2) RACEV2X and HISPNCAT were first introduced in 2013.
Race and ethnicity variables and their response categories for years prior to 2002 are available in the documentation for the FY Consolidated PUF for each data year. Values for these variables were obtained based on the following priority order. If available, data collected were used to determine race and ethnicity. If race and/or ethnicity were not reported in the interview, then data obtained from the originally collected NHIS data were used. (27 cases were resolved this way for race, and 14 cases were resolved this way for ethnicity.) If still not determined, the race, and/or ethnicity were assigned based on relationship to other members of the DU using a priority ordering that gave precedence to blood relatives in the immediate family (this approach was used on 8 persons to set race and 5 persons to set ethnicity). For the FY12 and FY13 PUFs, three new race variables were constructed for both the old and the new questions: RACEVER, RACEV1X, and RACETHX. The variable RACEVER was constructed to indicate which version of the race question(s) was asked and was included in only the 2012 and 2013 FY PUFs. RACEVER has been dropped starting with the 2014 PUF. The variables RACEV1X and RACETHX replace the variables RACEX and RACETHNX from 2002-2011. A new race variable, RACEV2X, was constructed only for the new race question and was added for the first time to the 2013 files. RACEV2X was set to -1 “Inapplicable” for persons that were not asked the new race question in FY13 only. This variable includes the expanded detail Asian categories and continues to be constructed for all PUFs. The “multiple races reported” categories for RACEV1X and RACEV2X differ in the 2013-2015 PUFs but are the same starting with the 2016 PUF. In the 2013-2015 PUFs, persons with multiple Asian races or multiple Hawaiian/Pacific Islander races were considered multiple races for RACEV2X and were not considered multiple races for RACEV1X. Starting with the 2016 PUFs, persons with multiple Asian races or multiple Hawaiian/Pacific Islander races were no longer considered multiple races in RACEV2X. For the FY12 and FY13 PUFs, the two Hispanic ethnicity variables from previous years were included: HISPANX and HISPCAT. The HISPANX variable continues to be constructed. The HISPCAT variable was constructed for specific Hispanic categories based only on the old question in FY12 and FY13 and HISPCAT has been dropped starting with the 2014 PUF. A new ethnicity variable, HISPNCAT, based on the new question, was introduced starting with 2013. HISPNCAT includes similar categories as HISPCAT but in a different order, and contains an additional category, 8 “Multiple Hispanic Groups Reported”, to represent any multiple responses reported. HISPNCAT was set to -1 “Inapplicable” for persons that were not asked the new ethnicity question in FY13. This variable continues to be constructed for all PUFs. Categories have been collapsed in the variables RACEV1X, RACEV2X and HISPNCAT. For RACEV1X, new with the 2012 PUF, categories 4 and 5 were collapsed in category 4 as “ASIAN/NATV HAWAIIAN/PACFC ISL-NO OTH” starting with the 2013 PUF. For RACEV2X, new with and starting with the 2013 PUF, categories 7, 8, 9, 10, and 11 were collapsed in category 10 as “OTH ASIAN/NATV HAWAIIAN/PACFC ISL-NO OTH,” and for HISPNCAT, new with and starting with the 2013 PUF, categories 6 and 7 were collapsed in category 6 as “OTH LAT AM/HISP/LATINO/SPNSH ORGN-NO OTH”. Language and English Proficiency The 2018 PUF represented a transition year for language variables. It contained two sets of variables that were similar in nature, but were collected differently. The new variables OTHLGSPK, WHTLGSPK, and HWELLSPK were collected at the person level. The old variables OTHLANG, LANGSPK were collected at the family level (RU) and old variable HWELLSPE was collected at the person level. For the 2019 PUF, the old variables (OTHLANG, LANGSPK, and HWELLSPE) have been dropped since they are no longer being populated. Language Variables: OTHLGSPK, WHTLGSPK, and HWELLSPK Beginning with the 2018 PUF, there were three new language variables (OTHLGSPK, WHTLGSPK, and HWELLSPK) that were collected at the person level in the round in which the person entered the MEPS survey. Beginning with Panel 23 Round 1, the household respondent was asked for each person, age 5 or older, a person-level question to determine whether that person speaks a language other than English at home (RE1170, OTHLGSPK). If the response to OTHLGSPK was ‘yes’, then two other questions were asked. WHTLGSPK (RE1170) is a person-level question that asks whether the non-English language spoken at home is Spanish or some other language, and HWELLSPK (RE1170) is a person-level question that asks how well that person can speak English. If the response to OTHLGSPK was ‘No’, then WHTLGSPK and HWELLSPK are set to ‘-1’ (Inapplicable). Family members who are deceased or institutionalized in Round 1 are coded with a value of ‘-1’ (Inapplicable). Minors under age 5 in households have all three variables coded to “5” (Under 5 years old – Inapplicable). Foreign Born Status Three questions regarding foreign-born status were asked in the Demographic section to ascertain whether a person was born in the U.S. (RE1170), what year they came to the U.S. (RE1170) if not born in the U.S., and years lived in the U.S. (RE1170) if the response to RE1170 was ‘Don’t Know’. They replaced similar questions that had been asked in the Access to Care section prior to 2013. The three questions were only asked once for each eligible person, that is, the first round the person was included in the interview. These new questions were asked of everyone, except deceased and institutionalized persons. The data from RE1170 are reported as the constructed variable BORNUSA. The data from RE1170 (YRCAMEUS) and RE1170 (YRSINUSA) were used to calculate the number of years a person has lived in the U.S. for the constructed variable YRSINUS. Please note that YRSINUS is a discrete variable and has collapsed categories: 1 “less than 1 year”; 2 “1 yr., less than 5 years”; 3 “5 yrs., less than 10 years”; 4 “10 yrs., less than 15 years”; 5 “15 years or more”. Marital Status and Spouse ID Current marital status was collected and/or updated during every round of the MEPS interview. This information was obtained in RE100 and RE1170 and is reported as MARRY31X, MARRY42X, MARRY53X, and MARRY19X. Persons under the age of 16 were coded as 6 “Under 16 – Inapplicable”. If marital status of a specified round differed from that of the previous round, then the marital status of the specified round was edited to reflect a change during the round (e.g., married in round, divorced in round, separated in round, or widowed in round). In instances where there were discrepancies between the marital statuses of two individuals within a family, other person-level variables were reviewed to determine the edited marital status for each individual. Thus, when one spouse was reported as married and the other spouse reported as widowed, the data were reviewed to determine if one partner should be coded as 8 “Widowed in Round”. Edits were performed to ensure some consistency across rounds. First, a person could not be coded as “Never Married” after previously being coded as any other marital status (e.g., “Widowed”). Second, a person could not be coded as “Under 16 – Inapplicable” after being previously coded as any other marital status. Third, a person could not be coded as “Married in Round” after being coded as “Married” in the round immediately preceding. Fourth, a person could not be coded as an “in Round” code (e.g., “Widowed in Round”) in two subsequent rounds. Since marital status can change across rounds and it was not feasible to edit every combination of values across rounds, unlikely sequences for marital status across the round-specific variables do exist. The person identifier for each individual’s spouse is reported in SPOUID31, SPOUID42, SPOUID53, and SPOUID19. These are the PIDs (within each family) of the person identified as the spouse during Round 3/1, Round 4/2, and Round 5/3 and as of December 31, 2019, respectively. If no spouse was identified in the household, the variable was coded as 995 “No Spouse in House”. Those with unknown marital status are coded as 996 “Marital Status Unknown”. Persons under the age of 16 are coded as 997 “Less than 16 Years Old”. The SPOUIN31, SPOUIN42, SPOUIN53, and SPOUIN19 variables indicate whether a person’s spouse was present in the RU during Round 3/1, Round 4/2, Round 5/3 and as of December 31, 2019 respectively. If the person had no spouse in the household, the value was coded as 2 “Not Married/No Spouse”. For persons under the age of 16 the value was coded as 3 “Under 16 – Inapplicable”. The SPOUID and SPOUIN variables were obtained from RE900, where the respondent was asked to identify how each pair of persons in the household was related. Analysts should note that this information was collected in a set of questions separate from the questions that asked about marital status. While editing was performed to ensure that SPOUID and SPOUIN are consistent within each round, there was no consistency check between these variables and marital status in a given round. Apparent discrepancies between marital status and spouse information may be due to any of the following causes:
Student Status and Educational Attainment The variables FTSTU31X, FTSTU42X, FTSTU53X, and FTSTU19X indicate whether the person was a full-time student at the interview date (or 12/31/19 for FTSTU19X). These variables have valid values for all persons between the ages of 17 - 23 inclusive. When this question was asked during Round 1 of Panel 24, it was based on age as of the 2018 NHIS interview date. Education questions were only asked when persons first entered MEPS, typically Round 1 for most people. It should be noted that education questions were changed with data collection in 2012 and then changed back to the original questions with data collection in 2015. The variables associated with the original education questions (data collection in 2011 and prior years and 2015 and subsequent years) are EDUCYR and HIDEG. The variable associated with the interim education question (data collection in 2012-2014) is EDUYRDEG (or EDUYRDG with collapsed categories). The variable EDRECODE relates variables for the original and interim education questions. As a result, different education variables are in the 2011-2015 PUFs based on the panel and round when a person first entered MEPS. The PUF documentation for each of the 2011-2015 years contains details about which education variables are in the respective files. Starting with the 2016 PUFs, EDUCYR and HIDEG are the only education variables on the PUFs. EDUCYR contains the number of years of education completed when entering MEPS for individuals 5 years or older. Children under the age of 5 years were coded as -1 “Inapplicable” regardless of whether they attended school. Individuals who were 5 years of age or older and had never attended school were coded as 0. The user should note that EDUCYR is an unedited variable and minimal data cleaning was performed on this variable. HIDEG contains information on the highest degree of education attained at the time the individual entered MEPS. Information was obtained from three questions: highest grade completed, high school diploma, and highest degree. Persons under 16 years of age when they first entered MEPS were coded as 8 “Under 16 – Inapplicable”. In cases where the response to the highest degree question was “No Degree” and the response to the highest grade question was 13 through 17, the variable HIDEG was coded as 3 “High School Diploma”. If the response to the highest grade completed was “Refused” or “Don’t Know” and the response to the highest degree question was “No Degree”, the variable HIDEG was coded as 1 “No Degree”. The user should note that HIDEG is an unedited variable and minimal data cleaning was performed on this variable. Military Service Information on active duty military status was collected during each round of the MEPS interview. Persons currently on full-time active duty status are identified in the variables ACTDTY31, ACTDTY42, and ACTDTY53. Those under 16 years of age were coded as 3 “Under 16 – Inapplicable”, and those over the age of 59 were coded as 4 “Over 59 – Inapplicable”. Beginning in Panel 23 Round 3, the question asking who have been honorably discharged from active duty was removed. Relationship to the Reference Person within Reporting Units For each Reporting Unit (RU), the person who owns or rents the DU is usually defined as the reference person. For student RUs, the student is defined as the reference person. (For additional information on reference persons, see the documentation on survey administration variables.) The relationship variables indicate the relationship of each individual to the reference person of the Reporting Unit (RU) in a given round. For confidentiality, starting in 2013, detailed relationships were combined into more general categories in the variables REFRL31X, REFRL42X, REFRL53X, and REFRL19X. These variables replaced RFREL31X, RFREL42X, RFREL53X, and RFRELyyX used before 2013. The new and old variables are defined differently, so researchers using multiple years of MEPS should refer to prior years’ documentation to assure consistency in their data. Note that categories for Child (4), Parent (7), and Sibling (8) for REFRL31X, REFRL42X, REFRL53X, and REFRL19X changed in 2017. In 2013-2016, these categories included biological, adoptive, step relationships, as well as in-law and foster relationships. Starting in 2017, in-law relationships are included in 91 OTHER RELATED, SPECIFY. Foster children were no longer included in MEPS starting on 2017, so those relationships no longer appear in any of the categories.
For the reference person, these variables have the value “Household reference person”; for all other persons in the RU, relationship to the reference person is indicated by codes representing “Spouse”, “Unmarried Partner”, “Child”, etc. A code of 91, meaning “Other Related, Specify”, was used to indicate rarely observed relationship descriptions such as “Mother of Partner”, “Partner of Sister”, etc. If the relationship of an individual to the reference person was not determined during the round-specific interview, relationships between other RU members were used, where possible, to assign a relationship to the reference person. If MEPS data from calendar year 2019 were not sufficient to identify the relationship of an individual to the reference person, relationship variables from the 2018 MEPS or NHIS data were used to assign a relationship. In the event that a meaningful value could not be determined or data were missing, the relationship variable was assigned a missing value code. If the relationship of two individuals indicated they were spouses, but both had marital status indicating they were not married, their relationship was changed to non-marital partners. In addition, the relationship variables were edited to insure that they did not change across rounds for RUs in which the reference person did not change, with the exception of relationships identified as partner or spouse relationships. Parent Identifiers The variables MOPID31X, MOPID42X, MOPID53X and DAPID31X, DAPID42X, DAPID53X are round-specific and are used to identify the parents (biological, adopted, or step) of the person represented on that record. MOPID##X contains the person identifier (PID) for each individual’s mother if she lived in the RU in that panel/round of the survey, or a value of –1 “Inapplicable” if she did not. Similarly, DAPID##X contains the person identifier (PID) for each individual’s father if he lived in the RU in that panel/round of the survey, or a value of –1 “Inapplicable” if he did not. MOPID##X and DAPID##X were constructed based on information collected in the relationship grid of the instrument each round at question RE900, and include biological, adopted, and stepparents. Foster parents were not included. For persons who were not present in the household during a round, MOPID##X and DAPID##X have values of –1 “Inapplicable”. Edits were performed to ensure that MOPID##X and DAPID##X were consistent with each individual’s age, sex, and other relationships within the family. For instance, the sex of the parent must be consistent with the indicated relationship; mothers are at least 12 years older than the person and no more than 55 years older than the person; fathers are at least 12 years older than the person; each person has no more than one mother and no more than one father; and the PID for the person’s mother and father are valid PIDs for that person’s RU for the 2019 Full Year File. 2.5.4 Income and Tax Filing Variables (FILEDR19-HIEUIDX)The file provides income and tax-related variables that were constructed primarily from data collected in the Panel 23 Round 5 and Panel 24 Round 3 Income Sections. Person-level income amounts have been edited and imputed for every record on the full-year file, with detailed imputation flags provided as a guide to the method of editing. The tax-filing variables and some program participation variables are unedited, as discussed below. Beginning with the income data collected for Panel 21 Round 5 and Panel 22 Round 3, two skip patterns were introduced to reduce respondent burden. Prior to Panel 21 Round 5 and Panel 22 Round 3, unemployment compensation income (IN360) was asked of all respondents eligible for income collection. Beginning with Panel 21 Round 5 and Panel 22 Round 3, IN360 was not administered for respondents who reported employment at the same current main job in the current round and the previous two rounds. Similarly, prior to Panel 21 Round 5 and Panel 22 Round 3, alimony income (IN170) was collected for all respondents eligible for income collection. Beginning with Panel 21 Round 5 and Panel 22 Round 3, IN170 was not administered for respondents who were married in the current round and married in the previous two rounds. As detailed below, weighted, sequential hot-decks were used to estimate amounts for unemployment compensation (UNEMP19X) and alimony income (ALIMP19X) for these respondents. Users should note that the introduction of these skip patterns may affect comparability of these income measures across survey years. During imputation, logical editing and weighted, sequential hot-decks were used to estimate income amounts for missing values (both for item nonresponse and for persons in the full-year file who were not in the income rounds). Reported income components were generally left unedited (with the few exceptions noted below). Thus, analysts using these data may wish to apply additional checks for outlier values that would appear to stem from misreporting. The editing process began with wage and salary income, WAGEP19X. Complete responses were left unedited, and this group of people was assigned WAGIMP19=1, where WAGIMP19 is the imputation flag for wage and salary data. The only exception was for a small number of persons who reported zero wage and salary income despite having been employed for pay during the year according to round-level data (see below). Data on tax filing and on taxable income sources were collected using an approach that encouraged respondents to provide information from their federal tax returns. Logical edits as well as a specific question on the wage income of the respondent (IN110) were used to assign separate income amounts to married persons whose responses were based on combined income amounts on their joint tax returns. Persons assigned WAGIMP19=2 were those providing broad income ranges (brackets) rather than giving specific dollar amounts. Weighted sequential hot-decking was used to provide these individuals with specific dollar amounts. For this imputation, donors were persons who reported specific dollar amounts within the corresponding broad income ranges. In 2019 (as in all previous years) there were a small number of cases where WAGEP19X=0 and WAGIMP19=2. These are cases where a married couple filing jointly reported wages with a bracket, and reported that one spouse earned $0 of that bracketed amount. All WAGEP19X hot-deck imputations used cells defined on the basis of a conventional list of person-level characteristics including age, education, employment status, race, sex, and region. Persons assigned WAGIMP19=3 were those who did not report wage and salary income and who were assigned WAGEP19X=0 based on not having been employed during the year. Persons assigned WAGIMP19=4 were those who did not provide valid dollar amounts or dollar ranges, but for whom we had related information from the employment sections of the survey. In most cases this information included wages, hours, and weeks worked; for some persons, only hours and weeks worked data were reported in the employment section. The available employment section data were used to construct annualized wage amounts to be used in place of missing income section annual wage and salary data. Comparisons of reported and constructed wages and salaries using persons who provided both sorts of information yielded a high degree of confidence that employment data could be reliably used to derive values to serve in place of missing wage and salary information. To implement this approach, part-year responders were assumed to be fully employed during the remainder of the year if they were employed during the period in which they provided data. An exception was made for those who either died or were institutionalized. These persons were assigned zero wages and salaries for the time they were not in MEPS. Hot-deck imputation was used for the remaining persons with missing WAGEP19X. Donor pools included persons whose WAGEP19X amounts were edited in the steps described above. Whenever possible, the hot-deck imputations used data on whether or not the person had been employed at any point during the year (and, if available, the number of weeks worked). Imputations for persons deemed to have been employed were conditional in nature, using only donors with positive WAGEP19X amounts (WAGIMP19=5). Imputations for WAGEP19X for the remaining persons were unconditional, using both workers and non-workers as donors (WAGIMP19=6). After editing WAGEP19X for all persons in the full-year file, the remaining income sources were edited in the following sequence: INTRP19X, BUSNP19X, DIVDP19X, ALIMP19X, SALEP19X, TRSTP19X, PENSP19X, IRASP19X, SSECP19X, UNEMP19X, WCMPP19X, VETSP19X, CASHP19X, OTHRP19X, CHLDP19X, SSIP19X, and PUBP19X. Income components were edited sequentially, in each case using information regarding income amounts that had already been edited (so as to maintain patterns of correlation across income sources whenever possible). In all cases, bracketed responses were edited first (using hot-deck imputations from donors in corresponding brackets who gave specific dollar amounts), followed by imputations for remaining missing values. The hot-deck imputations used cells defined on the basis of income amounts already edited and a conventional list of person-level characteristics such as age, education, employment status, race, sex, and region. In addition, hot-deck imputations for CHLDP19X used family-level information concerning marital status and the number of children. Hot-deck imputations for SSIP19X and PUBP19X were also assigned using, in part, simulated program eligibility indicators that integrated state-level program eligibility criteria with data on family composition and income. In the hot-decks for some income types, information from the National Health Interview Survey (NHIS) was used. The NHIS sample is the frame for the new sample selected for MEPS collection each year, with a year’s time lag. Data from the 2017 NHIS correspond to MEPS Panel 23, while those from the 2018 NHIS correspond to MEPS Panel 24. Because MEPS units come from the NHIS, it is possible to match individual MEPS responding units to an NHIS unit. Taking advantage of this matching ability, income recipiency indicators collected by NHIS were used in imputing for missing data in certain MEPS income components − interest, dividends, business income, pensions, and Social Security. (Not all MEPS income categories have an equivalent in NHIS. Also, wage data were available from NHIS, but were not used in the MEPS imputation process.) In cases where data on a particular income category were missing for a person in MEPS, the indicator in that income category on the NHIS file was employed, if a valid response was supplied. Indicators were examined for the entire tax-filing unit (two people in the case of married couples filing jointly; one person in all other cases). Reported income amounts of less than one dollar were treated as missing amounts (to be hot-decked from donors with positive amounts of the corresponding income source). Also, very few cases of outlier responses were edited (primarily public sources of income that exceeded possible amounts). Otherwise, reported amounts were left unchanged. For each income component, the corresponding xxxIMP19 variable contains an indicator concerning the method for editing/imputation. All the flag variables have the following formatted values:
Missing values were set to zero when there were too few recipients to warrant hot-deck imputations of positive values (as in the case of ALIMP19X received by males). “Conditional hot-decks” indicate instances where the respondent indicated receipt but not a specific dollar amount. In these cases, the donor pool was restricted to persons with nonzero amounts of the income source in question. “Unconditional hot-decks” indicate instances where the donor pool included persons receiving both zero and nonzero amounts (implemented in cases where there was little or no information about a person’s income source). Total person-level income (TTLP19X) is the sum of all income components with the exception of SALEP19X (to match as closely as possible the CPS definition of income; see Section 2.5.4). Some researchers may wish to define their own income measure by adding in one or both of these excluded components. The tax variables and food stamp variables are all completely unedited. Unedited tax variables are provided to assist researchers building tax simulation programs. No efforts have been made to eliminate inconsistencies among these program participation and tax variables and other MEPS data. All of these unedited variables should be used with great care. Income Top-Coding All person-level income amounts on the file, including both total income and the separate sources of income, were top-coded to preserve confidentiality. For each income source, top codes were applied to the top percentile of all cases (including negative amounts that exceeded income thresholds in absolute value). In cases where less than one percent of all persons received a particular income source, all recipients were top-coded. Top-coded income amounts were masked using a regression-based approach. The regressions relied on many of the same variables used in the hot-deck imputations, with the dependent variable in each case being the natural logarithm of the amount that the income component was in excess of its top-code threshold. Predicted values from this regression were reconverted from logarithms to levels using a smearing correction, and these predicted amounts were then added back to the top-code thresholds. This approach preserves the component-by-component weighted means (both overall and among top-coded cases), while also preserving much of the income distribution conditional on the variables contained in the regressions. At the same time, this approach ensures that every reported amount in excess of its respective threshold is altered on the public use file. The process of top-coding income amounts in this way inevitably introduces measurement error in cases where income amounts were reported correctly by respondents. Note, however, that top-coding can also help to reduce the impact of outliers that occur due to reporting errors. Total person-level income is constructed as the sum of the adjusted person-level income components. Having constructed total income in this manner, this total was then top-coded using the same regression-based procedure described above (again masking the top percentile of cases). Finally, the components of income were scaled up or down in order to make the sources of income consistent with the newly-adjusted totals. Poverty Status The definitions of income, family, and poverty categories used to construct the related variables in this file were taken from the 2019 poverty statistics developed by the Current Population Survey (CPS). The categorical variable for 2019 family income as a percentage of poverty (POVCAT19) was constructed using the same method as in earlier years’ files. FAMINC19 contains total family income for each person’s CPS family. Family income was derived by constructing person-level total income comprising annual earnings from wages, salaries, bonuses, tips, commissions; business and farm gains and losses; unemployment and workers’ compensation; interest and dividends; alimony, child support, and other private cash transfers; private pensions, IRA withdrawals, social security, and veterans payments; supplemental security income and cash welfare payments from public assistance, and related programs; gains or losses from estates, trusts, partnerships, S corporations, rent, and royalties; and a small amount of “other” income. Person-level income excluded tax refunds and capital gains. Person-level income totals were then summed over family members, as defined by CPSFAMID, to yield CPS family-level total income (FAMINC19). POVLEV19 is the continuous version of the POVCAT19 variable. The POVLEV19 percentage was computed by dividing CPS family income by the applicable poverty line (based on family size and composition). POVCAT19 takes the POVLEV19 percentage for each person and classifies it into one of five poverty categories: negative or poor (less than 100%), near poor (100% to less than 125%), low income (125% to less than 200%), middle income (200% to less than 400%), and high income (greater than or equal to 400%). Persons missing CPSFAMID were treated as one-person families in constructing their poverty percentage and category. Family income, as well as the components of person-level income, has been subjected to internal editing patterns and derivation methods that are in accordance to specific definitions, and are not being released at this time. Researchers working with a family definition other than CPSFAMID may wish to create their own versions of total family income. Health Insurance Eligibility Units (HIEUs) are sub-family relationship units constructed to include adults plus those family members who would typically be eligible for coverage under the adults' private health insurance family plans. To construct the HIEUIDX variable, which links persons into a common HIEU, we begin with the family identification variable CPSFAMID. Working with this family ID, we define HIEUIDX using family relationships as of the end of 2019. Persons missing end-of-year relationship information are assigned to an HIEUIDX using relationship information from the last round in which they provided such information. HIEUs comprise adults, their spouses, and their unmarried natural/adoptive children age 18 and under. Prior to the 2018 data year, only opposite-sex spouses were eligible to be included in the same HIEU. Beginning with the 2018 data year, both same-sex and opposite-sex spouses are included in the same HIEU. We also include children under age 24 who are full-time students (living at home or away from home). Other children who do not live with their natural/adoptive adult parents are placed in an HIEUIDX as follows:
HIEUs do not, in general, comprise adult (nonmarital) partnerships, because unmarried adult partners are rarely eligible for dependent coverage under each other's insurance. The exception to this rule is that we include adult partners in the same HIEU if there is at least one (out-of-wedlock) child in the family that links to both adult partners. In cases of missing or contradictory relationship codes, HIEUs are edited by hand, with the presumption being that the adults and children form a nuclear family. 2.5.5 Person-Level Condition Variables (RTHLTH31-ADHDAGED)Perceived Health Status Perceived health status (RTHLTH31, RTHLTH42, and RTHLTH53) and perceived mental health status (MNHLTH31, MNHLTH42, and MNHLTH53) were collected in the Priority Conditions Enumeration (PE) section. The target persons of the questions are all current or institutionalized persons regardless of age. These questions (PE10 and PE20) asked the respondent to rate each person in the family according to the following categories: excellent, very good, good, fair, and poor. Priority Condition Variables (HIBPDX-ADHDAGED) The PE section was asked in its entirety in Round 1 for all current or institutionalized persons, and in Rounds 2 and 4 for only new RU members. In Round 3, the specific condition questions (except joint pain and chronic bronchitis) were asked only if the person had not reported the condition in a previous round; the joint pain and chronic bronchitis questions were asked in Round 3 for all current or institutionalized persons aged 18 or older, regardless of Round 1 and Round 2 responses. Beginning in 2017, the PE section is no longer asked in Round 5 and no Round 5/3 variables are included in this file. Priority condition variables whose names end in “DX” indicate whether the person was ever diagnosed with the condition. Chronic bronchitis, joint pain, and asthma follow-up questions (ASSTIL31, ASATAK31, and ASTHEP31 described below) reflect data obtained in Round 3 of Panel 23 and Round 1 of Panel 24. Diagnoses data (except attention deficit hyperactivity disorder/attention deficit disorder, diabetes, and asthma) were collected for persons over 17 years of age. If edited age is within range for the variable to be set, but the source data are missing because person’s age in CAPI is not within range, the constructed variable is set to “Cannot be Computed” (-15). Additionally, if the person was 17 in Round 1, turned 18 in Round 2, and was not a current or institutionalized RU member in Round 3, the source data are missing per design. However, the DX variables are set to “Cannot be Computed” (-15) as the person was old enough to be asked the PE questions within the data year. Following the same pattern, attention deficit hyperactivity disorder/attention deficit disorder is asked of persons age 5 to 17, and diabetes and asthma are asked of persons of all ages. Exceptions to this pattern are the variables JTPAIN31_M18 and CHBRON31, which are described in greater detail below. Questions were asked regarding the following conditions:
These conditions were selected because of their relatively high prevalence, and because generally accepted standards for appropriate clinical care have been developed. This information thus supplements other information on medical conditions that is gathered in other parts of the interview. Condition data were collected at the person-by-round level (indicating if the person was ever diagnosed with the condition) and at the condition level. If the person reported having been diagnosed with a condition, the person-by-round variable was set to ‘1’ (Yes) and a condition record for that medical condition was created. Editing of these variables focused on checking that skip patterns were consistent. High Blood Pressure Questions about high blood pressure (hypertension) were asked only of persons aged 18 or older. Consequently, persons aged 17 or younger were coded as “Inapplicable” (-1) on these variables. HIBPDX ascertained whether the person had ever been diagnosed as having high blood pressure (other than during pregnancy). Those who had received this diagnosis were also asked if they had been told on two or more different visits that they had high blood pressure (BPMLDX). The age of diagnosis for high blood pressure (HIBPAGED) is included in this file. This variable is top-coded to 85 years of age. Heart Disease Heart disease questions were asked only of persons aged 18 or older. Consequently, persons aged 17 or younger were coded as “Inapplicable” (-1) on all the variables in this set. CHDDX – asked if the person had ever been diagnosed as having coronary heart disease ANGIDX – asked if the person had ever been diagnosed as having angina, or angina pectoris MIDX – asked if the person had ever been diagnosed as having a heart attack, or myocardial infarction OHRTDX – asked if the person had ever been diagnosed with any other kind of heart disease or condition The age of diagnosis for coronary heart disease (CHDAGED), angina (ANGIAGED), heart attack or myocardial infarction (MIAGED), and other kind of heart disease (OHRTAGED) are included in this file. These variables are top-coded to 85 years of age. Beginning in 2018, respondents who answered “Yes” to a person being diagnosed with any other kind of heart disease or condition (OHRTDX) were asked a follow up question (OHRTTYPE) to specify other heart diseases or conditions. Stroke STRKDX asked if the person (aged 18 or older) had ever been diagnosed as having had a stroke or transient ischemic attack (TIA or ministroke). Persons aged 17 or younger were coded as “Inapplicable” (-1). The age of diagnosis for stroke or TIA (STRKAGED) is included in this file. This variable is top-coded to 85 years of age. Emphysema EMPHDX asked if the person (aged 18 or older) had ever been diagnosed with emphysema. Persons aged 17 or younger were coded as “Inapplicable” (-1). The age of diagnosis for emphysema (EMPHAGED) is included in this file. This variable is top-coded to 85 years of age. Chronic Bronchitis CHBRON31 asked if the person (aged 18 or older) has had chronic bronchitis in the last 12 months. Persons aged 17 or younger were coded as “Inapplicable” (-1). High Cholesterol Questions about high cholesterol were asked of persons aged 18 or older. Consequently, persons aged 17 or younger were coded as “Inapplicable” (-1) on these variables. CHOLDX ascertained whether the person had ever been diagnosed as having high cholesterol. The age of diagnosis for high cholesterol (CHOLAGED) is included in this file. This variable is top-coded to 85 years of age. Cancer Questions about cancer were asked only of persons aged 18 or older. Consequently, persons aged 17 or younger were coded as “Inapplicable” (-1) on these variables. CANCERDX ascertained whether the person had ever been diagnosed as having cancer or a malignancy of any kind. If the respondent answered “Yes” they were asked at PE140 what type of cancer was diagnosed. CABLADDR, CABLOOD, CABREAST, CACERVIX, CACOLON, CALUNG, CALYMPH, CAMELANO, CAMUSCLE, CAOTHER, CAPROSTA, CASKINNM, CASKINDK, and CAUTERUS indicate selection of cancer of the bladder, blood, breast, cervix, colon, or lung; lymphoma or melanoma; cancer of the soft tissue, muscle, or fat; other type of cancer, cancer of the prostate, skin, or uterus. Cancer of the cervix or uterus could not be reported for males, and cancer of the prostate could not be reported for females. Recoding of Cancer Variables Specific cancer diagnosis variables with a frequency count fewer than 20 and those considered clinically rare (i.e., appear on the National Institutes of Health’s list of rare diseases), were removed from the file for confidentiality reasons, and the corresponding variable CAOTHER, indicating diagnosis of a cancer that is not counted individually, was recoded to “Yes” (1) as necessary. In data year 2019, the clinically rare cancers are:
The variable CABREAST, which indicates diagnosis of breast cancer, was recoded to “Inapplicable” (-1) for males for confidentiality reasons. The corresponding value of the general cancer diagnosis variable, CANCERDX, was recoded to “Cannot be Computed” (-15), and the corresponding values of remaining specific cancer variables were recoded to “Inapplicable” (-1). Diabetes Prior to 2018, diabetes diagnosis was asked for each person aged 18 or older. Beginning in 2018, DIABDX_M18 replaces DIABDX where diabetes is now asked for all ages. DIABDX_M18 indicates whether each person had ever been diagnosed with diabetes (excluding gestational diabetes). The age of diagnosis for diabetes (DIABAGED) is included in this file. This variable is top-coded to 85 years of age. Each person 18 years or older said to have received a diagnosis of diabetes was asked to complete a special self-administered questionnaire. The documentation for this questionnaire appears in the Diabetes Care Survey (DCS) section of the documentation. Joint Pain JTPAIN31_M18 asked if the person (aged 18 or older) had experienced pain, swelling, or stiffness around a joint in the last 12 months. This question is not intended to be used as an indicator of a diagnosis of arthritis. Persons aged 17 or younger were coded as “Inapplicable” (-1). Prior to 2017, joint pain questions were asked in Rounds 5/3 and Rounds 3/1. Beginning in 2017, joint pain questions are no longer asked in Rounds 5/3. Starting in 2018, joint pain questions are skipped if person already has an arthritis condition that is specified on the conditions roster in the PE section. Arthritis ARTHDX asked if the person (aged 18 or older) had ever been diagnosed with arthritis. Persons aged 17 or younger were coded as “Inapplicable” (-1). Respondents who answered “Yes” were asked a follow up question to determine the type of arthritis. ARTHTYPE indicates if the diagnosis was for Rheumatoid Arthritis (1), Osteoarthritis (2), or non-specific arthritis (3). The age of diagnosis for arthritis (ARTHAGED) is included in this file and may be recoded in some cases to “Cannot be Computed” (-15) for confidentiality reasons. This variable is top-coded to 85 years of age. Asthma ASTHDX indicates whether a person had ever been diagnosed with asthma. The age of diagnosis for asthma (ASTHAGED) is included in this file. This variable is top-coded to 85 years of age. Respondents who answered “Yes” to asthma diagnosis were asked additional questions. ASSTIL31 asked if the person still had asthma. ASATAK31 asked whether the person had experienced an episode of asthma or an asthma attack in the past 12 months. If the person did not experience an asthma attack in the past 12 months, a follow-up question (ASTHEP31) asked when the last asthma episode or asthma attack occurred. Additional follow-up questions regarding asthma medication used for quick relief (ASACUT31), preventive medicine (ASPREV31), and peak flow meters (ASPKFL31) were asked. These questions were asked if the person reported having been diagnosed with asthma (ASTHDX = 1). ASACUT31 asked whether, during the last three months, the person had used the kind of prescription inhaler “that you breathe in through your mouth” that gives quick relief from asthma symptoms. ASPREV31 asked whether the person had ever taken the preventive kind of asthma medicine used every day to protect the lungs and prevent attacks, including both oral medicine and inhalers. ASPKFL31 indicates whether the person with asthma had a peak flow meter at home. Respondents who answered “Yes” to ASACUT31 were asked whether the person had used more than three canisters of this type of inhaler in the past three months (ASMRCN31). Respondents who answered “Yes” to ASPREV31 were asked whether the person now took this kind of medication daily or almost daily (ASDALY31). Respondents who answered “Yes” to ASPKFL31 were asked if the person ever used the peak flow meter (ASEVFL31). Those respondents who answered “Yes” to ASEVFL31 were asked when the person last used the peak flow meter (ASWNFL31). Beginning in 2018, questions regarding asthma medication used for quick relief, preventive medicine, and peak flow meters are now implemented starting with Panel 22 Round 3 and Panel 23 Round 1. The asthma variables included in this file are: ASSTIL31 (Does Person Still Have Asthma - RD 3/1) ASATAK31 (Asthma Attack Last 12 Mos - RD 3/1) ASTHEP31 (When Was Last Episode of Asthma - RD 3/1) ASACUT31 (Used Acute Pres Inhaler Last 3 Mos- RD 3/1) ASPREV31 (Ever Used Prev Daily Asthma Meds – RD 3/1) ASPKFL31 (Have Peak Flow Meter at Home – RD 3/1) ASMRCN31 (Used >3 Acute Cn Pres Inh Last 3 Mos – RD 3/1) ASDALY31 (Now Take Prev Daily Asthma Meds - RD 3/1) ASEVFL31 (Ever Used Peak Flow Meter - RD 3/1) ASWNFL31 (When Last Used Peak Flow Meter - RD 3/1) It may appear that there are discrepancies between the diagnosis variable and the follow-up variables. If a person reported asthma in the PE section in Panel 24 Round 3, ASATAK31 and ASSTIL31 will be set to “Inapplicable” (-1) as the person had not reported asthma in Round 1. Attention Deficit Hyperactivity Disorder/Attention Deficit Disorder ADHDADDX asked if persons aged 5 through 17 had ever been diagnosed as having Attention Deficit Hyperactivity Disorder or Attention Deficit Disorder. Persons younger than 5 or older than 17 were coded as “Inapplicable” (-1). The age of diagnosis for attention deficit hyperactivity disorder/attention deficit disorder (ADHDAGED) is included in this file. 2.5.6 Health Status Variables (IADLHP31-ADOVER42)Due to the overlapping panel design of the MEPS (Round 3 for Panel 23 overlapped with Round 1 for Panel 24, Round 4 for Panel 23 coincided with Round 2 for Panel 24, and Round 5 for Panel 23 occurred at the same time as Round 3 for Panel 24), data from overlapping rounds have been combined across panels. Thus, any variable ending in “31” reflects data obtained in Round 3 of Panel 23 and Round 1 of Panel 24. Analogous comments apply to variables ending in “42”. Health Status variables whose names end in “19” indicate a full-year measurement. For persons in Panel 23, Round 3 extended from 2018 into 2019. Therefore, for these people, some information from late 2018 is included for variables that have names ending in “31”. Health Status variables in this data release can be classified into several conceptually distinct sets:
In general, Health Status variables involved the construction of person-level variables based on information collected in the Health Status section of the questionnaire. Many Health Status questions were initially asked at the family level to ascertain if anyone in the household had a particular problem or limitation. These were followed up with questions to determine which household member had each problem or limitation. All information ascertained at the family level has been brought to the person level for this file. Logical edits were performed in constructing the person-level variables to assure that family-level and person-level values were consistent. Particular attention was given to cases where missing values were reported at the family level to ensure that appropriate information was carried to the person level. Inapplicable cases occurred when a question was never asked because of a skip pattern in the survey (e.g., some follow-up verification questions were not asked about individuals who were 13 years of age or older; questions pertaining to children’s health status were not asked about individuals older than 17). Inapplicable cases are coded as -1. In addition, deceased persons were coded as “Inapplicable” (-1). Each of the sets of variables listed above will be described in turn. IADL and ADL Limitations IADL Help The Instrumental Activities of Daily Living (IADL) Help or Supervision variable (IADLHP31) was constructed from a series of three questions administered in the Health Status section of the interview in Panel 23 Round 3 and Panel 24 Round 1. The initial question (HE10) determined if anyone in the family received help or supervision with IADLs such as using the telephone, paying bills, taking medications, preparing light meals, doing laundry, or going shopping. If the response was “Yes”, a follow-up question (HE20) was asked to determine which household member(s) received this help or supervision. For persons under age 13, a final verification question (HE30) was asked to confirm that the IADL help or supervision was the result of an impairment or physical or mental health problem. If the response to the final verification question was “No”, IADLHP31 was coded “No” for persons under the age of 13. If no one in the family was identified as receiving help or supervision with IADLs, all members of the family were coded as receiving no IADL help or supervision. In cases where the response to the family-level question was “Refused” (-7), “Don’t Know” (-8), or “Cannot be Computed” (-15), all persons were coded according to the family-level response. In cases where the response to the family-level question (HE10) was “Yes” but no specific individuals were identified in the follow-up question as having IADL difficulties, all persons were coded as “Don’t Know” (-8). ADL Help The Activities of Daily Living (ADL) Help or Supervision variable (ADLHLP31) was constructed in the same manner, and for the same persons, as the IADL help variable, but using questions HE40-HE60 in Panel 23 Round 3 and Panel 24 Round 1. Coding conventions for missing data were the same as for the IADL variable. Functional and Activity Limitations Functional Limitations A series of questions asked in Panel 23 Round 3 and Panel 24 Round 1 pertained to functional limitations, which are defined as difficulty in performing certain specific physical actions. WLKLIM31 was the filter question. These variables were derived from a question (HE90) that was asked at the family level: “Does anyone in the family have difficulties walking, climbing stairs, grasping objects, reaching overhead, lifting, bending or stooping, or standing for long periods of time?” If the answer was “No”, then all family members were coded as “No” (2) on WLKLIM31. If the answer was “Yes”, then the specific persons who had any of these difficulties were identified and coded as “Yes” (1), and remaining family members were coded as “No” (2). If the response to the family-level question was “Don’t Know” (-8), “Refused” (-7), “Cannot be Computed” (-15), or “Inapplicable” (-1), then the corresponding missing value code was applied to each family member’s value for WLKLIM31. If the answer to HE90 was “Yes” (1) but no specific individual was named as experiencing such difficulties, then each family member was assigned “Don’t Know” (-8). Deceased persons were assigned a code of “Inapplicable” (-1) for WLKLIM31. For Rounds 3 (Panel 23) and 1 (Panel 24), if WLKLIM31 was coded “Yes” (1) for any family member, a subsequent series of questions was administered. The series of questions for which WLKLIM31 served as a filter is as follows: LFTDIF31 – difficulty lifting 10 pounds STPDIF31 – difficulty walking up 10 steps WLKDIF31 – difficulty walking 3 blocks MILDIF31 – difficulty walking a mile STNDIF31 – difficulty standing 20 minutes BENDIF31 – difficulty bending or stooping RCHDIF31 – difficulty reaching over head FNGRDF31 – difficulty using fingers to grasp This series of questions was asked separately for each person whose response to WLKLIM31 was coded “Yes” (1). The series of questions was not asked for other individual family members whose response to WLKLIM31 was “No” (2). In addition, this series was not asked about family members who were less than 13 years of age, regardless of their status on WLKLIM31. These questions were not asked about deceased family members. In such cases (i.e., WLKLIM31 = 2, or age < 13, or PSTATS31 = 23, 24, or 31), each question in the series was coded as “Inapplicable” (-1). Finally, if responses to WLKLIM31 were “Refused” (-7), “Don’t Know” (-8), “Cannot be Computed” (-15), or otherwise “Inapplicable” (-1), then each question in this series was coded as “Inapplicable” (-1). Analysts should note that WLKLIM31 was asked of all household members, regardless of age. For the subsequent series of questions, however, persons less than 13 years old were skipped and coded as “Inapplicable” (-1). Therefore, it is possible for someone age 12 or younger to have a code of “Yes” (1) on WLKLIM31, and also to have codes of “Inapplicable” on the subsequent series of questions. Use of Assistive Technology and Social/Recreational Limitations The variables indicating use of assistive technology (AIDHLP31 from question HE70) and social/recreational limitations (SOCLIM31, from question HE230) were collected initially at the family level. If there was a “Yes” (1) response to the family-level question, a second question identified the specific individual(s) to whom the “Yes” response pertained. Each individual identified as having the difficulty was coded “Yes” (1) for the appropriate variable; all remaining family members were coded “No” (2). If the family-level response was “Refused” (-7), “Don’t Know” (-8), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” but no specific individual was identified as having difficulty, all family members were coded as “Don’t Know” (-8). Work, Housework, and School Limitations The variable indicating any limitation in work, housework, or school (ACTLIM31) was constructed using questions HE190-HE200. Specifically, information was collected initially at the family level. If there was a “Yes” (1) response to the family-level question (HE190), a second question (HE200) identified the specific individual(s) to whom the “Yes” (1) response pertained. Each individual identified as having a limitation was coded “Yes” (1) for the appropriate variable; all remaining family members were coded “No” (2). If the family-level response was “Refused” (-7), “Don’t Know” (-8), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having limitation, all family members were coded as “Don’t Know” (-8). Persons less than five years old were coded as “Inapplicable” (-1) on ACTLIM31. For Round 3 (Panel 23) or Round 1 (Panel 24), if ACTLIM31 was “Yes” (1) and the person was 5 years of age or older, a follow-up question (HE210) was asked to identify the specific limitation or limitations for each person. These included working at a job (WRKLIM31), doing housework (HSELIM31), or going to school (SCHLIM31). Respondents could answer “Yes” (1) or “No” (2) to each activity; thus a person could report limitations in multiple activities. WRKLIM31, HSELIM31, and SCHLIM31 have values of “Yes” (1) or “No” (2) only if ACTLIM31 was “Yes” (1); each variable was coded as “Inapplicable” (-1) if ACTLIM31 was “No” (2). When ACTLIM31 was “Refused” (-7), these variables were all coded as “Refused” (-7); when ACTLIM31 was “Don’t Know” (-8), these variables were all coded as “Don’t Know” (-8); and when ACTLIM31 was “Cannot be Computed” (-15), these variables were all coded as “Cannot be Computed” (-15). If a person was under 5 years old or was deceased, WRKLIM31, HSELIM31, and SCHLIM31 were each coded as “Inapplicable” (-1). An additional question (UNABLE31) asked if the person was completely unable to work at a job, do housework, or go to school. Those persons who were coded “No” (2), “Refused” (-7), “Don’t Know” (-8), or “Cannot be Computed” (-15) on ACTLIM31, were under 5 years of age, or were deceased were coded as “Inapplicable” (-1) on UNABLE31. UNABLE31 was asked once for whichever set of WRKLIM31, HSELIM31, and SCHLIM31 the person had limitations; if a person was limited in more than one of these three activities, UNABLE31 did not specify if the person was completely unable to perform all of them, or only some of them. Cognitive Limitations The variable indicating any cognitive limitation (COGLIM31) was collected at the family level as a three-part question (HE250A to HE250C), asking if any of the adults in the family (1) experience confusion or memory loss, (2) have problems making decisions, or (3) require supervision for their own safety. If a “Yes” response was obtained to any item, the persons affected were identified in HE260, and COGLIM31 was coded as “Yes” (1). Remaining family members not identified were coded as “No” (2) for COGLIM31. If responses to HE250A through HE250C were all “No”, or if two of three were “No” (2) and the remaining was “Refused” (-7), “Don’t Know” (-8), or “Cannot be Computed” (-15), all family members were coded as “No” (2). If responses to the three questions were combinations of “Don’t Know” (-8), “Refused” (-7), and missing, all persons were coded as “Don’t Know” (-8). If the response to any of the three questions was “Yes” (1) but no individual was identified in HE260, all persons were coded as “Don’t Know” (-8). COGLIM31 reflects whether any of the three component questions is “Yes” (1). Family members with one, two, or three specific cognitive limitations cannot be distinguished. In addition, because the question asked specifically about adult family members, all persons less than 18 years of age are coded as “Inapplicable” (-1) on this question. Hearing, Vision Problems A series of questions (HE270 to HE310), asked in Panel 23 Round 4 and Panel 24 Round 2, provides information on hearing and visual impairment. Household members less than one year old and deceased RU members were coded as “Inapplicable” (-1). The hearing impairment variable, DFHEAR42, indicates whether a person has serious difficulty hearing. This variable was based on two questions, HE270 and HE280. The initial question (HE270) determined if anyone in the family had difficulty hearing. If the response was “Yes” (1), a follow-up question (HE280) was asked to determine which household member(s) had a hearing impairment. If the family-level response was “Don’t Know” (-8), “Refused” (-7), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having serious difficulty hearing, all family members were coded as “Don’t Know” (-8). The visual impairment variable, DFSEE42, indicates whether a person has serious difficulty seeing. This variable was based on two questions, HE290C and HE300. The initial question (HE290C) determined if anyone in the family had difficulty seeing. If the response was “Yes” (1), a follow-up question (HE300) was asked to determine which household member(s) had a seeing impairment. If the family-level response was “Don’t Know” (-8), “Refused” (-7), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having serious difficulty seeing, all family members were coded as “Don’t Know” (-8). Disability Status A series of questions (HE310 to HE380) in Panel 23 Round 4 and Panel 24 Round 2 provides information on cognitive difficulty, difficulty walking or climbing stairs, difficulty dressing or bathing, and difficulty doing errands. Questions regarding cognitive difficulty, difficulty walking or climbing stairs, and difficulty dressing or bathing were asked of household members 5 years of age and older. The question regarding difficulty doing errands was asked of household members 15 years of age and older. Deceased RU members were coded “Inapplicable” (-1). DFCOG42 indicates whether a person had serious cognitive difficulty. This variable was based on two questions, HE310 and HE320. The initial question (HE310) determined if anyone in the family had difficulty concentrating, remembering or making decisions. If the response was “Yes” (1), a follow-up question (HE320) was asked to determine which household member(s) had difficulty concentrating, remembering or making decisions. If the family-level response was “Don’t Know” (-8), “Refused” (-7), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having serious cognitive difficulty, all family members were coded as “Don’t Know” (-8). DFWLKC42 indicates whether a person has serious difficulty walking or climbing stairs. This variable was based on two questions, HE330 and HE340. The initial question (HE330) determined if anyone in the family had serious difficulty walking or climbing stairs. If the response was “Yes” (1), a follow-up question (HE340) was asked to determine which household member(s) had difficulty walking or climbing stairs. If the family-level response was “Don’t Know” (-8), “Refused” (-7), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having serious difficulty walking or climbing stairs, all family members were coded as “Don’t Know” (-8). DFDRSB42 indicates whether a person has difficulty dressing or bathing. This variable was based on two questions, HE350 and HE360. The initial question (HE350) determined if anyone in the family had difficulty dressing or bathing. If the response was “Yes” (1), a follow-up question (HE360) was asked to determine which household member(s) had difficulty dressing or bathing. If the family-level response was “Don’t Know” (-8), “Refused” (-7), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having difficulty dressing or bathing, all family members were coded as “Don’t Know” (-8). DFERND42 indicates whether a person has difficulty doing errands alone. This variable was based on two questions, HE370 and HE380. The initial question (HE370) determined if anyone in the family had difficulty doing errands alone. If the response was “Yes” (1), a follow-up question (HE380) was asked to determine which household member(s) had difficulty doing errands alone. If the family-level response was “Don’t Know” (-8), “Refused” (-7), or “Cannot be Computed” (-15), all persons were coded with the family-level response. In cases where the family-level response was “Yes” (1) but no specific individual was identified as having difficulty doing errands alone, all family members were coded as “Don’t Know” (-8). Any Limitation Rounds 3 and 4 (Panel 23) / Rounds 1 and 2 (Panel 24) ANYLMI19 summarizes whether a person had any IADL, ADL, functional, or activity limitations in any of the pertinent rounds. ANYLMI19 was built using the component variables IADLHP31, ADLHLP31, WLKLIM31, ACTLIM31, DFSEE42, and DFHEAR42. If any of these components was coded “Yes”, then ANYLMI19 was coded “Yes” (1). If all components were coded “No”, then ANYLMI19 was coded “No” (2). If all the components were “Inapplicable” (-1), then ANYLMI19 was coded as “Inapplicable” (-1). If all the components had missing value codes (i.e., -7, -8, or -1), ANYLMI19 was coded as “Cannot be Computed” (-15). If some components were “No” and others had missing value codes, ANYLMI19 was coded as “Cannot be Computed” (-15). The exception to this latter rule was for children younger than five years old, who were not asked questions that are the basis for ACTLIM31; for these RU members, if all other components were “No”, then ANYLMI19 was coded as “No” (2). The variable label for ANYLMI19 departs slightly from conventions. Typically, variables that end in “19” refer only to 2019. However, some of the variables used to construct ANYLMI19 were assessed in 2020, so some information from early 2020 is incorporated into this variable. Child Health Questions were asked about each child (under the age of 18 excluding deceased children) in the applicable age subgroups to which they pertained. For the Child Supplement variables, a code of “Inapplicable” (-1) was assigned if a person was deceased, was not in the appropriate Round 2 or 4, or was not in the applicable age subgroup as of the interview date. This public use dataset contains variables and frequency distributions from the Child Preventive Health (CS) Section associated with 7,529 children who were eligible for the CS section. Children were eligible for this section when PSTATS42 was not equal to 23, 24, 31 (Deceased) and 0 <= AGE42X <= 17. Of these children, 6,357 were assigned a positive person-level weight for 2019 (PERWT19F > 0). Cases not eligible for the CS section should be excluded from estimates made with the CS section. Starting in 2018, the Consumer Assessment of Healthcare Providers and Systems (CAHPS) and Columbia Impairment Scale (CIS) series of questions will be administered every other year. CAPI will administer the CAHPS and CIS series as follows:
Therefore, since Panel 24 Round 1 collection started in 2019 and Panel 23 started in 2018, the CAHPS and CIS questions were asked, and these variables are included in the 2019 dataset. In addition, the child preventive care series will be administered every other year beginning in 2018. CAPI will administer the child preventive care series in Round 2 for panels whose Round 1 collection occurred in an odd year, and in Round 4 for panels whose Round 1 collection occurred in an even year. Therefore, the child preventive care questions were not asked in 2019 and are not included in the 2019 dataset, but will be included in the 2020 dataset.
Children with Special Health Care Needs Screener (ages 0 - 17) The Children with Special Health Care Needs (CSHCN) Screener instrument was developed through a national collaborative process as part of the Child and Adolescent Health Measurement Initiative (CAHMI) coordinated by the Foundation for Accountability. A key reference for this screener instrument is Bethel et al (2002). These questions are asked about children ages 0-17. In general, the CSHCN screener identifies children with activity limitation or need or use of more health care or other services than is usual for most children of the same age. When a response to a gate question was set to “No” (2), “Refused” (-7), “Don’t Know” (-8), or “Cannot be Computed” (-15), follow-up variables based on the gate question were coded as “Inapplicable” (-1). The variable CSHCN42 identifies children with special health care needs, and was created using the CSHCN screener questions according to the specifications in the reference above. The CSHCN screener questions consist of a series of question sequences about the following five health consequences: the need or use of medicines prescribed by a doctor; the need or use of more medical care, mental health, or education services than is usual for most children; being limited or prevented in doing things most children can do; the need or use of special therapy such as physical, occupational, or speech therapy; and the need or use of treatment or counseling for emotional, developmental, or behavioral problems. Parents who responded “yes” to any of the “initial” questions in the five question sequences were then asked to respond to up to two follow-up questions about whether the health consequence was attributable to a medical, behavioral, or other health condition lasting or expected to last at least 12 months. Children with positive responses to at least one of the five health consequences along with all of the follow-up questions were identified as having a Special Health Care Need. Children with a “no” response for all five question sequences were considered NOT to have a Special Health Care Need. Those children whose “special health care need” status could not be determined (due to missing data for any of the questions) were coded as “Unknown” for CSHCN42. More information about the CSHCN screener questions can be obtained from the website for the Child and Adolescent Health Measurement Initiative. The CSHCN screener questions were: CHPMED42 – child needs or uses prescribed medicines CHPMHB42 – prescribed medicines were because of a medical, behavioral, or other health condition CHPMCN42 – health condition that causes a person to need prescribed medicines has lasted or is expected to last for at least 12 months CHSERV42 – child needs or uses more medical care, mental health, or education services than is usual for most children of the same age CHSRHB42 – child needs or uses more medical and other service because of a medical, behavioral, or other health condition CHSRCN42 – health condition that causes a person to need or use more medical and other services has lasted or is expected to last for at least 12 months CHLIMI42 – child is limited or prevented in any way in ability to do the things most children of the same age can do CHLIHB42 – child is limited in the ability to do the things most children can do because of a medical, behavioral, or other health condition CHLICO42 – health condition that causes a person to be limited in the ability to do the things most children can do has lasted or is expected to last for at least 12 months CHTHER42 – child needs or gets special therapy such as physical, occupational, or speech therapy CHTHHB42 – child needs or gets special therapy because of a medical, behavioral, or other health condition CHTHCO42 – health condition that causes a person to need or get special therapy has lasted or is expected to last for at least 12 months CHCOUN42 – child has an emotional, developmental, or behavioral problem for which he or she needs or gets treatment or counseling CHEMPB42 – problem for which a person needs or gets treatment or counseling is a condition that has lasted or is expected to last for at least 12 months CSHCN42 – identifies children with special health care needs Columbia Impairment Scale (ages 5 - 17) (included in alternating years only) These questions inquired about possible child behavioral problems and were asked in previous years. Respondents were asked to rate on a scale from 0 to 4, where “0” indicates “No Problem” and “4” indicates “A Very Big Problem”, how much of a problem the child has with thirteen specified activities. A key reference for the Columbia Impairment Scale is Bird et al (1996). Certain questions in this series were coded to “Asked, but Inapplicable” (99) when the question was not applicable for a specific child. For example, if a child’s mother was deceased, a question about how much of a problem a child has getting along with his/her mother would be set to “Asked, but Inapplicable” (99). Similarly, the question about problems getting along with siblings would be set to “Asked, but Inapplicable” (99) for children with no siblings. Variables in this set include: GETTRB42 – problem with getting into trouble MOMPRO42 – getting along with mother DADPRO42 – getting along with father UNHAP42 – feeling unhappy or sad SCHLBH42 – (his/her) behavior at school HAVFUN42 – having fun ADUPRO42 – getting along with adults NERVAF42 – feeling nervous or afraid SIBPRO42 – along with brothers and sisters KIDPRO42 – getting along with other kids SPRPRO42 – getting involved in activities like sports or hobbies SCHPRO42 – (his/her) schoolwork HOMEBH42 – (his/her) behavior at home CAHPS® (Consumer Assessment of Healthcare Providers and Systems) ages 0 – 17 (included in alternating years only) The health care quality measures were taken from the health plan version of CAHPS®, an AHRQ-sponsored family of survey instruments designed to measure quality of care from the consumer’s perspective. All of the CAHPS® variables refer to events experienced in the last 12 months. The variables included from the CAHPS® are: CHILCR42 – whether a person had an illness, injury, or condition that needed care right away from a clinic, emergency room, or doctor’s office CHILWW42 – how often a person got care as soon as was needed (coded as “-1 Inapplicable” when CHILCR42 = 2, -7, -8, or -15) CHRTCR42 – whether any appointments were made CHRTWW42 – how often a person got an appointment for health care as soon as was needed (coded as “-1 Inapplicable” when CHRTCR42 = 2, -7, -8, or -15) CHAPPT42 – how many times a person went to a doctor’s office or clinic for health care CHEXPL42 – how often a person’s doctors or other health providers explained things in a way the parent could understand (coded as “-1 Inapplicable” when CHAPPT42 = 0, -7, -8, or -15) CHLIST42 – how often a person’s doctors or other health providers listened carefully to the parent (coded as “-1 Inapplicable” when CHAPPT42 = 0, -7, -8, or -15) CHRESP42 – how often a person’s doctors or other health providers showed respect for what the parent had to say (coded as “-1 Inapplicable” when CHAPPT42 = 0, -7, -8, or -15) CHPRTM42 – how often doctors or other health providers spent enough time with a person (coded as “-1 Inapplicable” when CHAPPT42 = 0, -7, -8, or -15) CHHECR42 – rating of health care from 0 to 10 where 0 = Worst health care possible and 10 = Best health care possible (coded as “-1 Inapplicable” when CHAPPT42 = 0, -7, -8, or -15) CHSPEC42_M18 – whether a person made an appointment to see a specialist CHEYRE42_M18 – how often did a person get appointments to see a specialist (coded as “-1 Inapplicable” when CHSPEC42 = 2, -7, -8, or -15) Additional Health Variables In 2018, the CAPI Preventive Care (AP) section was dropped, and some preventive care questions were added to the Self-Administered Questionnaire (SAQ) (see 2.5.5.8). Two questions from the dropped CAPI Preventive Care section, LSTETH53 (has person lost all natural (permanent) teeth) and PHYEXE53 (currently spends half hour or more in moderate to vigorous physical activity at least five times a week) were retained in the new section Additional Healthcare Questions (AH). Additionally, the health variable OFTSMK53 (how often smoke cigarettes), was added to AH in 2018. These questions are asked every year of each person 18 years or older. A code of “Inapplicable” (-1) was assigned if the person was deceased or less than 18 years old. 2019 Self-Administered Questionnaires The MEPS distributes several hard-copy, self-administered questionnaires (SAQs) to collect health-related information from different subpopulations of MEPS participants. The Diabetes Care Survey is distributed every year, while other SAQs are distributed only in select years.
Self-Administered Questionnaire (SAQ) The Self-Administered Questionnaire (SAQ) is a paper-and-pencil questionnaire that includes core questions about health status that are asked every year. In 2018, preventive health questions were added to the SAQ. These are asked in alternating years and will be included next in the 2020 SAQ. In 2019, questions regarding quality of health care, general health questions, and questions about health-related attitudes were included in the SAQ and will be included in alternating years. The quality of health care variables, general health variables, and variables about health-related attitudes are included in this 2019 SAQ release and will be included next in the 2021 SAQ. The 2019 SAQ was fielded during Panel 23 Round 4 and Panel 24 Round 2 of the 2019 MEPS. All adults age 18 and older as of the Round 2 or 4 interview date (AGE42X >= 18) in MEPS households were asked to complete an SAQ. The questionnaires were administered in late 2019 and early 2020. The variable SAQELIG indicates the person’s eligibility status for the SAQ. SAQELIG was used to construct the variables based on the SAQ data. SAQELIG was coded “0” (Not Eligible for SAQ) if there was no record for the person in the round, if the person was deceased or institutionalized, moved out of the U.S., moved to a military facility, if the person’s disposition status was inapplicable, or if the person was less than 18 years old. SAQELIG was coded “1” (Eligible for SAQ and Has SAQ Data) if an SAQ record existed for the person in Round 2 (for Panel 24) or Round 4 (for Panel 23). SAQELIG was coded “2” (Eligible for SAQ, but No SAQ Data) if no SAQ record existed for the person in the round. This variable was used as a building block for all other constructed SAQ variables. A question on the form asked if the respondent was the person represented in the form. If a person was unable to respond to the SAQ, the questionnaire was completed by a proxy. The relationship of the proxy to the adult represented in the questionnaire is indicated by the variable ADPROX42. Prior to 2015, the variable ADPRX42 indicated the relationship of the proxy to the adult. Starting in 2015, the response categories for proxy relationship were collapsed in a new variable ADPRXY42. In 2019, ADPROX42 was coded “1” (Self-administered) if the respondent was the person represented in the questionnaire. A code of “-1” (Inapplicable) was assigned if a person was not eligible or was eligible but no data existed (SAQELIG = 0 or 2). If a person was not assigned a positive SAQ weight, all SAQ variables except SAQELIG were coded “Inapplicable” (-1). When a gate question answer was set to “No” (2), follow-up variables based on the gate question were coded as “Inapplicable” (-1). When a gate question answer was set to “Refused” (-7) or “Don’t Know” (-8), follow-up variable answers were left as reported. A special weight variable (SAQWT19F) has been designed to be used with the SAQ for persons who were age 18 and older at the interview date. This weight adjusts for non-response and weights to the U.S. civilian noninstitutionalized population (see Section 3.0 “Survey Sample Information” for details). The variables created from the SAQ begin with “AD,” again excepting SAQELIG. Health Care Quality (included in alternating years only) The health care quality measures in the SAQ were taken from the health plan version of CAHPS®, an AHRQ-sponsored family of survey instruments designed to measure quality of care from the consumer’s perspective. All of the variables refer to events experienced in the last 12 months and were asked of adults age 18 and older. The variables included from the CAHPS® are: ADILCR42 – Had an illness, injury or condition needing care right away from a clinic, emergency room or doctor’s office ADILWW42 – If ADILCR42 = 1, how often got care right away ADRTCR42 – Any appointment was made with a doctor or clinic for health care ADRTWW42 – If ADRTCR42 = 1, how often got an appointment for health care as soon as he or she thought it was needed ADAPPT42 – Number of times went to doctor’s office or clinic to get care ADLIST42 – If ADAPPT42 > 0, how often health providers listened carefully to you ADEXPL42 – If ADAPPT42 > 0, how often health providers explained things in a way that was easy to understand ADRESP42 – If ADAPPT42 > 0, how often providers showed respect for what you had to say ADPRTM42 – If ADAPPT42 > 0, how often health providers spent enough time with you ADINST42 – If ADAPPT42 > 0, whether doctors or other health providers gave instructions about what to do about a specific illness or health condition ADEZUN42 – If ADINST42 = 1, how often the advice given by doctors or other health providers was easy to understand ADTLHW42 – If ADINST42 = 1, how often doctors or other health providers asked you to describe how you are going to follow their instructions ADFFRM42 – If ADAPPT42 > 0, whether had to fill out or sign any forms at the doctor’s office or other health provider’s office ADFHLP42 – If ADFFRM42 = 1, how often you were offered help with filling out forms at the office ADHECR42 – If ADAPPT42 > 0, rating of healthcare from all doctors and other health providers, from 0 (worst health care possible) to 10 (best health care possible) ADSPCL42 – Needed to see a specialist ADSNSP42 – If ADSPCL42 = 1, how easy to see a specialist General Health (included in alternating years only) ADSMOK42 – Currently smoke ADNSMK42 – If ADSMOK42 = 1, doctor advised you to quit smoking Health Status The SAQ contained three measures of health status: the Veteran RAND (VR-12), a registered trademark, the Kessler Index (K6) of non-specific psychological distress, and the Patient Health Questionnaire (PHQ-2). More information about the VR-12 is available through the Boston University School of Public Health website. Key references for these three measures are Kessler et al (2002), Kroenke et al (2003), Selim et al (2018) and Selim et al (2009). Veterans RAND 12 Version (VR-12) The Veterans RAND 12 Item Health Survey (VR-12©) is a self-administered health survey comprising 12 items used to measure health related quality of life, to estimate disease burden and to evaluate disease-specific impact on general and selected populations. The VR instrument uses five-point ordinal response choices for four items in the VR-12©. Response choices are five-point response choices: “no, none of the time”, “yes, a little of the time”, “yes, some of the time”, “yes, most of the time” and “yes, all of the time.” These answers then contribute to the scales for role limitations due to physical and emotional problems (PCS) and the physical and mental summary scores (MCS). In analyzing data from the VR-12, the standard approach is to form two summary scores based on responses to the 12 questions. The standard scoring algorithms for both the Physical Component Summary (PCS) and the Mental Component Summary (MCS) incorporate information from all 12 questions. However, the PCS weights more heavily responses to the following questions: ADGENH42, ADDAYA42, ADCLIM42, ADACLS42, ADWKLM42, and ADPAIN42. The MCS weights more heavily responses to the following questions: ADPRST42, ADPCFL42, ADEMLS42, ADMWDF42, and ADSOCA42. The computer programs to create VR scales and PCS/MCS summaries are copyrighted (all rights reserved) by the Trustees of Boston University to ensure the integrity of the assessments. The comparability of the 2017 MEPS VR-12 PCS and MCS summary scores from the standard scoring algorithm and the SF-12v2 PCS and MCS summary scores obtained from prior years of MEPS was assessed, and it was determined that the scores were misaligned. A bridging algorithm specific to MEPS was developed by a team at the Boston University School of Public Health. The goal of this bridging algorithm was to align the VR-12 PCS and MCS scores from the 2017 MEPS as closely as possible with the SF-12v2 PCS and MCS scores from prior MEPS years across a wide range of MEPS subpopulations. This bridging algorithm was applied to the VR-12 PCS and MCS score variables (VPCS42 and VMCS42) available on this data file. The PCS and MCS cannot be computed directly if a person has missing data for any of the twelve items. A proprietary method was used for imputing the PCS and MCS scores if some data are missing. The bridging algorithm used for these measures was developed to be tolerant of missing data in item responses when computing PCS and MCS scores. Therefore, the variables VPCS42 and VMCS42 include some cases in which the scores have been imputed. Some cases were unable to be scored in the bridging algorithm due to the amount of missing data in item responses; these cases have VRFLAG42 = 0 (No). VRFLAG42 indicates whether the physical component summary, VPCS42, or the mental component, VMCS42, was imputed for a respondent. Persons who were not eligible for the SAQ, or who were eligible but for whom no data existed based on SAQELIG, or who did not have a positive SAQ weight, were set to “Inapplicable” (-1) for VRFLAG42, VPCS42 and VMCS42. Any remaining persons who could not be scored were set to “Cannot be Computed” (-15) for VPCS42 and VMCS42. Additionally, beginning in 2017, there are no negative score values of VPCS42 and VMCS42 because they are both top- and bottom-coded. More information on the VR-12 can be found on the Boston University website VR-12 page. The report containing information on the methodology used for the bridging algorithm can be requested from mepsprojectdirector@ahrq.hhs.gov. The VR-12 questions are as follows: ADGENH42 – General health today ADDAYA42 – During a typical day, limitations in moderate activities ADCLIM42 – During a typical day, limitations in climbing several flights of stairs ADACLS42 – During past 4 weeks, as result of physical health, accomplished less than would like ADWKLM42 – During past 4 weeks, as result of physical health, limited in kind of work or other activities ADEMLS42 – During past 4 weeks, as result of emotional problems, accomplished less than you would like ADMWDF42 – During past 4 weeks, as result of emotional problems, did work or other activities less carefully than usual ADPAIN42 – During past 4 weeks, pain interfered with normal work outside the home and housework ADPCFL42 – During the past 4 weeks, felt calm and peaceful ADENGY42 – During the past 4 weeks, had a lot of energy ADPRST42 – During the past 4 weeks, felt downhearted and blue ADSOCA42 – During the past 4 weeks, physical health or emotional problems interfered with social activities Non-Specific Psychological Distress The 2019 SAQ includes six mental health-related questions, using the “K-6” scale developed by R.C. Kessler and colleagues. These questions assess the person’s non-specific psychological distress during the past 30 days. The non-specific psychological distress variables are as follows: ADNERV42 – During the past 30 days, how often felt nervous ADHOPE42 – During the past 30 days, how often felt hopeless ADREST42 – During the past 30 days, how often felt restless or fidgety ADSAD42 – During the past 30 days, how often felt so sad that nothing could cheer the person up ADEFRT42 – During the past 30 days, how often felt that everything was an effort ADWRTH42 – During the past 30 days, how often felt worthless Kessler Index (K6) A summary of the six variables above provides an index to measure non-specific, rather than disorder-specific, psychological distress, using the following values:
The index, called K6SUM42, is a summation of the values of the six variables above. The higher the value of K6SUM42, the greater the person’s tendency towards mental disability. Patient Health Questionnaire (PHQ-2) The 2019 SAQ includes two additional mental health questions. These questions assess the frequency of the person’s depressed mood and decreased interest in usual activities. ADINTR42 – During the past two weeks, bothered by having little interest or pleasure in doing things ADDPRS42 – During the past two weeks, bothered by feeling down, depressed, or hopeless PHQ242 is a summation of the values of the two variables above, with scores ranging from 0 through 6. The higher the value of PHQ242, the greater the person’s tendency towards depression. Kroenke et al. (2004) suggest a score of 3 as the optimal cut point for screening purposes. Note that these items are intended as a screening measure for depression and are not equivalent to a DSM-V diagnosis of depression. When using the SAQ variables in analysis, weights specific to these questions should be used (SAQWT19F). For persons who are not assigned a positive SAQ weight, the SAQ variables are recoded to “Inapplicable” (-1). Please see Section 3.0 “Survey Sample Information” for details. Veteran Self-Administered Questionnaire (VSAQ) The Veteran Self-Administered Questionnaire (VSAQ), a self-administered paper-and-pencil questionnaire, was fielded during Panel 23 Round 3 and Panel 24 Round 1. Prior to 2019, the VSAQ was fielded in Rounds 3 and 5 instead of Rounds 1 and 3. To reflect this change, the variable names have been changed to include “31” instead of “53”. Households received a VSAQ based on their response in the Renumeration (RE) section of the CAPI instrument whether there was someone on active duty in the past but not now. The VSAQ is only available in the English language. The variable VSAQELIG indicates the person’s eligibility status for the VSAQ. VSAQELIG was used to construct the variables based on the VSAQ data. VSAQELIG was coded “0” (Not Eligible For VSAQ) if there was no record for the person in the round, if the person was deceased or institutionalized, moved out of the U.S., moved to a military facility, if the person’s disposition status was inapplicable, or if the person was less than 18 years old. VSAQELIG was coded “1” (Eligible For VSAQ and Has VSAQ Data) if a VSAQ record existed for the person in Round 3 (for Panel 23) or Round 1 (for Panel 24). VSAQELIG was coded “2” (Eligible For VSAQ, But No VSAQ Data) if no VSAQ record existed for the person in the round. This variable was used as a building block for all other constructed VSAQ variables. The completion of the VSAQ is determined by the answer provided by VACTDY31. For confidentiality reasons, variables indicating when the veteran was in active duty, whether or not received a disability rating, was a POW, and discharge information are not included on this file. The variable VAPRHT31 indicates whether the veteran is a Purple Heart recipient. Veteran Health and Health Care Services This section of the VSAQ collects information related to the veteran’s health conditions and whether any health care services were used from the VA, outside of the VA, or neither. In addition, it collects information related to the veteran’s choice of care, such as cost or location. VACOPD31 – Diagnosed with COPD VADERM31 – Diagnosed with Dermatol Conditions VAGERD31 – Diagnosed with GERD VAHRLS31 – Diagnosed with Hearing Loss VABACK31 – Diagnosed with Back Pain VAJTPN31 – Ever Diagnosed with Joint Pain VARTHR31 – Ever Diagnosed with Osteoarthritis VAGOUT31 – Ever Diagnosed with Gout VANECK31 – Ever Diagnosed with Neck Pain VATMD31 – Ever Diagnosed with TMD VAPTSD31 – Ever Diagnosed with PTSD VALCOH31 – Ever Diagnosed with Alcohol Abuse VABIPL31 – Ever Diagnosed with Bipolar Disorder VADEPR31 – Ever Diagnosed with Depression VAMOOD31 – Ever Diagnosed with Mood Disorder VAPROS31 – Receive Prosthesis VARHAB31 – Receive Rehabilitation Services VAMNHC31 – Receive Individual Mental Health Care VAGCNS31 – Receive Mental Health Group Counseling VARXMD31 – Receive Prescription Medications VACRGV31 – Receive Caregiver Support VAMOBL31 – Receive Assistive Mobility Device VACOST31 – Cost of Care VARECM31 – Recommendation of Another Doctor VAREP31 – Reputation of Doctor Providing Care VAWAIT31 – Short Wait Time VALOCT31 – Location of Doctor’s Practice VANTWK31 – In Network Provider VANEED31 – Understands Needs of Veterans Health Care from Outside the VA This section of the VSAQ collects information related to the veteran’s care (except dental) outside of the VA. Questions include whether the veteran visited a non-VA provider in the last 12 months, if the non-VA provider was knowledgeable about the veteran’s conditions, medical records keeping and if it was difficult to coordinate care with VA providers. VAOUT31 – Visit Provider Outside VA VAPAST31 – Non-VA Provider Know Past Health Problems VACOMP31 – Non-VA Provider Health Information Complete VAMREC31 – Ask Non-VA Provider for Medical Records VAGTRC31 – Non-VA Provider Get Medical Records VACARC31 – Non-VA Provider Aware VA Services VAPROB31 – Problem with Non-VA Provider Not Aware of VA Services Health Care at the VA This section of the VSAQ collects information related to the veteran’s care (except dental) within the VA. Questions include whether the veteran visited a VA provider in the last 12 months, if they have visited a primary care provider (PCP) or Patient Aligned Care Team (PACT), if the VA provider was knowledgeable about the veteran’s conditions, how often the VA provider ordered testing, and the quality of medical records keeping. In addition, it collects information on coordination of care with non-VA providers. VACARE31 – Received Care from VA Provider VAPACT31 – Visit PACT or PCP VAPCPR31 – VA PCP/PACT Know Past Health Problems VAPROV31 – See VA Provider Other Than PCP/PACT VAPCOT31 – VA PCP Know Results of Other VA Provider VAPCCO31 – VA PCP/PACT Health Information Complete VAPCRC31 – Ask VA PCP/PACT for Medical Records VAPCSN31 – VA PCP/PACT Get Medical Records VAPCRF31 – Need Referral to Non-VA Provider VAPCSO31 – Get Referral to Non-VA Provider VAPCOU31 – VA PCP/PACT Aware of Non-VA Services VAPCUN31 – VA PCP/PACT Unaware of Non-VA Services Health Care from Specialists This section of the VSAQ collects information for the last 12 months related to the veteran’s need for specialist care, such as whether a specialist was used, if the specialist was knowledgeable of the veteran’s medical history, and the quality of coordination of care to non-VA providers. VASPCL31 – Receive Care from VA Specialist VASPMH31 – VA Specialist Had Medical History VASPOU31 – VA Specialist Aware of Non-VA Services VASPUN31 – VA Specialist Unaware of Non-VA Services If a person was unable to respond to the VSAQ, the questionnaire was completed by a proxy (VAPROX31). A special weight variable (VSAQW19F) has been designed to be used with VSAQ data. This weight adjusts for VSAQ nonresponse and weights to the number of veterans in the U.S. civilian noninstitutionalized population in 2019 (see Section 3.0 “Survey Sample Information” for details). For persons who are not assigned a positive VSAQ weight, the VSAQ variables are recoded to “Inapplicable” (-1). Diabetes Care Survey (DCS) The Diabetes Care Survey (DCS), a self-administered paper-and-pencil questionnaire, was fielded during Panel 23, Round 5 and Panel 24, Round 3. Households received a DCS based on their response to DIABDX_M18 in the Priority Conditions Enumeration (PE) section of the CAPI instrument, which asks whether the person was ever told by a doctor or health professional that he/she had diabetes. Note that only those 18 years or older were asked to complete a DCS questionnaire. Prior to 2017, the variable REFDIAB, collected at PC02A, allowed the respondent to indicate that diabetes was reported in the PE section in error (REFDIAB = 2). In 2017, REFDIAB (denial by the respondent of a diabetes diagnosis) was dropped from CAPI. The DCS asks the same question as DIABDX_M18 with responses summarized in the variable DSDIA53. DSDIA53 confirms that the person has ever been told by a health professional that he/she had diabetes or sugar diabetes. Every year, a small number (55) of people answer no to the diabetes diagnosis question (DCS.DIABDIAG) on the DCS. These people have DSDIA53 initially set to “2” (No). DCS.DIABDIAG is used in the development of the diabetes weight (DIABWyyF); if the person has DCS.DIABDIAG = “2” (No) they do not receive a diabetes weight (DIABWyyF = 0). In the final stage of DCS variable construction, DCS constructed variables, excluding the eligibility variable (DCSELIG) were recoded to “-1” where DIABWyyF = 0. For these cases, DIABDX_M18 =YES (1) but DSDIA53 = NO (2). The DCS data are unedited, and, therefore, these and other data inconsistencies remain in the data. For all persons 17 years of age or younger, all the DCS variables are set to “-1” (Inapplicable) because there is not an appropriate weight included on the file to make national estimates for this population. DSA1C53 indicates the number of times the respondent reported having a hemoglobin A1c blood test in 2019. Note that, prior to 2005, DSA1C53 did not reflect whether the person had a hemoglobin A1c blood test, only whether the person had a hemoglobin A1c test. DSFT2053, DSFT1953, DSFT1853, DSFB1853, and DSFTNV53 indicate whether the respondent reported having his or her feet checked for sores or irritations: in 2020, in 2019, in 2018, before 2018, or never, respectively. DSEY2053, DSEY1953, DSEY1853, DSEB1853 and DSEYNV53 indicate whether the respondent reported having an eye exam in which the pupils were dilated: in 2020, in 2019, in 2018, before 2018, or never, respectively. DSCH2053, DSCH1953, DSCH1853, DSCB1853, and DSCHNV53 indicate the last time the respondent reported having his or her blood cholesterol checked: in 2020, in 2019, in 2018, before 2018, or never, respectively. DSFL2053, DSFL1953, DSFL1853, DSVB1853, and DSFLNV53 indicate when the person got a flu vaccination including the flu vaccine nasal spray: in 2020, in 2019, in 2018, before 2018, or never, respectively. DSKIDN53 and DSEYPR53 ascertain whether the diabetes has caused kidney or eye problems, respectively. DSDIET53, DSMED53, and DSINSU53 indicate if the respondent reported being treated for his/her diabetes by the following methods: diet, oral medications, or insulin, respectively. The five variables that assess different ways the person with diabetes can learn about diabetes care are: DSCPCP53 (learned care from a primary care provider), DSCNPC53 (learned care from a provider not in the person’s primary care practice), DSCPHN53 (learned care from a phone call with a provider), DSCINT53 (learned care from reading about it on the internet), and DSCGRP53 (learned care by taking a group class). Creation of these variables is based on the answer to a gate question, which asks, “During the last 12 months, have you learned how to take care of your diabetes?” Please note that there is no variable listed in the codebook to indicate the answer to that question, since it is only used for creation of the follow-up variables DSCPCP53, DSCNPC53, DSCPHN53, DSCINT53, and DSCGRP53. These follow-up variables are set to Inapplicable (-1) for persons who report not having learned how to take care of their diabetes during the last 12 months. The variable DSCONF53 indicates how confident the person is in treating his or her diabetes. Those variables that indicate a range of care outside the data year may represent persons with additional information included on the 2018 or the 2020 Full Year Consolidated PUF. Additional data for the second-year panel may be available on the 2018 PUF. If a person was unable to respond to the DCS, the questionnaire was completed by a proxy (DSPRX53 = 1). A special weight variable (DIABW19F) has been designed to be used with DCS data. This weight adjusts for DCS nonresponse and weights to the number of diabetics in the U.S. civilian noninstitutionalized population in 2019 (see Section 3.0 “Survey Sample Information” for details). When using these variables in analysis, weights specific to each of these sets of questions should be used (SAQWT19F, VSAQW19F, DIABW19F). For persons who are not assigned a positive DCS weight, the DCS variables are recoded to “Inapplicable” (-1). Please see Section 3.0 “Survey Sample Information” for details. 2.5.7 Disability Days Indicator Variables (DDNWRK19-OTHNDD19)The Disability Days (DD) section of the core interview contains questions about time lost from work because of a physical illness or injury, or a mental or emotional problem. Data were collected on each individual in the household. These questions were repeated in each round of interviews; this file contains data from Rounds 3, 4, and 5 of the MEPS Panel 23, initiated in 2018, and Rounds 1, 2, and 3 of the MEPS Panel 24, initiated in 2019. Beginning in FY 2015, annualized versions of these variables are constructed for release rather than the previously released versions, which were round- and panel-specific. The number at the end of the variable name (19) identifies the variable as representing data from 2019. Due to confidentiality concerns, the annual Disability Days variables, which represent the number of days a person missed work (DDNWRK19 and OTHNDD19), are top-coded to mask values that exceed the top one-half of one percent of the population. These annual variables use building block variables for construction, which represent an individual panel within the data year. The reference period for the Disability Days questions is the time period between the beginning of the panel or the previous interview date and the current interview date. Analysts should be aware that Round 3 is conducted across years. The Disability Days variables reflect only the data pertinent to the calendar year (i.e., the current delivery year of 2019). Analysts who are interested in examining Disability Days data across years can link to other person-level PUFs using the DUPERSID. The flow of the Disability Days section relies on the person’s age as of the interview date. Therefore, the round-specific constructed age variables (AGE31X, AGE42X, and AGE53X) are used to construct the comparable round-specific Disability Days building block variables. Due to the age-specific nature of the Disability Days section, age data from other rounds are not used should the person’s age for the round be missing. The variable DDNWRK19 represents the number of times the person lost a half-day or more from work because of illness, injury, or mental or emotional problems during the calendar year. A response of “no work days lost” was coded zero; if the person did not work, this variable was coded -1 (Inapplicable). The analyst should note that there are cases where EMPST## = 1 or 2 (has current job or job to return to) where DDNWRK19 contains a positive value, indicating the number of times the person lost a half-day or more from work. This is because the responses to the Disability Days questions are independent of the responses to the employment questions. Persons who were less than 16 years old or whose age is missing (AGE##X is set to -1) were not asked about work days lost, thus this variable is coded -1 (Inapplicable) for these persons. Beginning with Panel 22 Round 3, the CAPI questions about time lost from school are no longer asked and the related variable DDNSCLyy is no longer delivered. A final set of variables indicates if an individual took a half-day or more off from work to care for the health problems of another individual in the family and the number of days missed. OTHDYS19 indicates if a person missed work because of someone else’s illness, injury, or health care needs, for example to take care of a sick child or relative. This variable has three possible answers: yes - missed work to care for another (coded 1); no - did not miss work to care for another (coded 2); or the person does not work (coded -1), based on the setting of DDNWRK19. Persons younger than 16 and persons whose age is missing were not asked this question and are also coded as -1 (in a small number of cases this was not done for the 1996 data, the analyst will need to make this edit when doing longitudinal analyses). OTHNDD19 indicates the number of days in which work was lost because of another’s health problem. Persons younger than 16, those whose age is missing, those who do not work, and those who answer “no” to OTHDYS19 are skipped out of OTHNDD19 and receive a code of -1. Note that, because Disability Days variables use only those Round 3 data pertinent to the data year, it is possible to have a person report missing work to care for the health problems of another individual (OTHDYS19 = 1) but report no days missed (OTHNDD19 = 0). This combination indicates that the person did not miss those workdays during the data year. Editing was done on these variables to preserve the skip patterns. No imputation was done for those with missing data. 2.5.8 Access to Care Variables (ACCELI42-AFRDPM42)The variables ACCELI42 through AFRDPM42 describe data from the Access to Care (AC) section of the MEPS HC questionnaire, which was administered in Panel 23 Round 4 and Panel 24 Round 2. This supplement gathers information on family members’ usual source of health care; characteristics of usual source of health care providers; access to and satisfaction with the usual source of health care provider; and affordability of medical treatment, dental treatment, and prescription medicines. The variable ACCELI42 indicates whether persons were eligible to receive the Access to Care questions. Persons with ACCELI42 set to ‘-1’ (Inapplicable) should be excluded from estimates made with the Access to Care data. Family Members’ Usual Source of Health Care For each individual family member, the AC section ascertains whether there is a particular doctor’s office, clinic, health center, or other place that the individual usually goes to if he/she is sick or needs advice about his/her health (HAVEUS42). PRACTP42 indicates whether a usual source of care (USC) provider has his or her own practice that is not part of a group practice, health center, clinic, or other facility. For those family members who have a USC provider, AC30 ascertains the type of practice:
YNOUSC42_M18 indicates the main reason why a person does not have a USC provider. For those family members who do not have a USC provider, question AC40 ascertains the main reason why:
In 2018, YNOUSC42 was renamed to YNOUSC42_M18 because the list of answer categories changed. Characteristics of Usual Source of Health Care Providers The AC section collects information about the different characteristics of each unique USC provider for a given family. If a person does not have a USC provider (HAVEUS42 is set to ‘2’ (No), ‘-7’ (Refused), ‘-8’ (Don’t Know) or ‘-15’ (Cannot be Computed)), then these variables are set to ‘-1’ (Inapplicable). The basis for the AC provider questions is PROVTY42_M18. This variable indicates whether the person’s provider is a facility (‘1’), a person (‘2’), or a person-in-facility (‘3’). PROVTY42_M18 is a copy of PROVTYPE_M18 (Provider Type) for persons who have a USC provider. Depending on how PROVTYPE_M18 is set, persons are asked about the provider’s location, the provider’s personal characteristics (e.g., race), the provider’s accessibility, and the person’s satisfaction with the provider. In 2018, PROVTY42 was renamed PROVTY42_M18 because of changes to CAPI. Provider Location Two variables indicate the location of the provider. For facility or person-in-facility type providers, PLCTYP42 indicates whether the person’s facility is a Hospital Clinic or Outpatient Department (‘1’), Hospital Emergency Room (‘2’), or Other Kind of Place (‘3’). According to CAPI flow, persons do not report the type of facility for person-type providers; therefore, if PROVTY42_M18 is set to ‘2’ (Person), PLCTYP42 is set to ‘-1’ (Inapplicable). For all provider types, including person-type, LOCATN42 indicates whether the person’s provider is located in an Office (‘1’), a Hospital but Not the Emergency Room (‘2’), or a Hospital Emergency Room (‘3’). Personal Characteristics of Providers For person and person-in-facility type providers, TYPEPE42 indicates what type of doctor or other medical provider the person’s provider is. The possible values include:
TYPEPE42 is constructed using variables collected at several questions: AC70 “Is provider a medical doctor?” (PROV.MEDTYPE_M18); AC80 “Is provider a nurse, nurse practitioner, physician’s assistant, midwife, or some other kind of person?” (PROV.OTHTYPE_M18); and AC90 “What is provider’s specialty?” (PROV.MDSPECLT_M18). If respondents choose ‘91’ (Other) at AC80 or AC90, they are asked at AC80OS or AC90OS, respectively, to provide a verbal explanation of the type of provider or medical doctor. These text strings can be recoded to one of the existing categorical values listed above or, if the frequency of the response warrants it, additional categorical values. Recoding is described in greater detail below. The AC section also collects demographic information about person and person-in-facility type providers (PROVTY42 = 2 or 3). Six variables indicate the provider’s race: WHITPR42 (White), BLCKPR42 (Black/African American), ASIANP42 (Asian), NATAMP42 (Indian/Native American/Alaska Native), PACISP42 (Other Pacific Islander) and OTHRCP42 (Other Race). The respondent may choose more than one race for a single provider. These variables reflect the answer categories given at AC110. In addition to the race variables, two other demographic variables are created: HSPLAP42 indicates whether or not the provider is Hispanic or Latino, and GENDRP42 indicates whether the provider is Male (‘1’) or Female (‘2’). Using Constructed Variables to Describe the Usual Source of Care Provider These variables describing a person’s USC provider can be used in combination to present a broader picture of the provider. For example, a person-in-facility provider with a particular person named who is a white, Hispanic, female pediatrician, with no other race specified, and whose location is in a hospital is coded as: PROVTY42_M18 = 3 PLCTYP42 = 1 TYPEPE42 = 3 HSPLAP42 = 1 WHITPR42 = 1 BLCKPR42 = 2 ASIANP42 = 2 NATAMP42 = 2 PACISP42 = 2 OTHRCP42 = 2 GENDRP42 = 2 LOCATN42 = 2 Access to and Satisfaction with the Provider The AC section collects information regarding the person’s ability to access the USC provider as well as the person’s satisfaction with the USC provider. Access to the Provider TMTKUS42 indicates how long it takes the person to travel to the USC provider: Less Than 15 Minutes (‘1’), 15 to 30 Minutes (‘2’), 31 to 60 Minutes (‘3’), 61 to 90 Minutes (‘4’), 91 Minutes to 120 Minutes (‘5’), or More than 120 Minutes (‘6’). OFFHOU42, PHNREG42, and AFTHOU42 assess aspects of the provider that may make it difficult for the person to get in contact with the USC provider. OFFHOU42 indicates whether the provider has office hours at night or on the weekend. The remaining two variables reflect the person’s rating of the difficulty of accessing the USC provider by phone (PHNREG42), and after hours (AFTHOU42). The person has the following choices: Very Difficult (‘1’), Somewhat Difficult (‘2’), Not Too Difficult (‘3’), or Not at All Difficult (‘4’). Satisfaction with the Provider These variables reflect the person’s satisfaction with the USC provider. The person’s level of satisfaction with the USC provider is examined in four ways: Does the USC provider: usually ask about prescription medications and treatments other doctors may give them (TREATM42), ask the person to help make decisions between a choice of treatments (DECIDE42), present and explain all options to the person (EXPLOP42), and speak the person’s language or provide translator services (PRVSPK42). PRVSPK42 is set to a value other than ‘-1’ (Inapplicable) for persons eligible for the Access to Care supplement, who had a usual source of care, were identified as speaking a language other than English at home (OTHLGSPK = ‘1’) and speaking English either “Not Well” or “Not at All” (HWELLSPK = ‘3’ or ‘4’). PRVSPK42 is set to ‘-1’ (Inapplicable) for all persons not meeting these criteria or who were deceased, institutionalized, or younger than 5 years of age. If the person was under 5 years old in Round 1 and age 5 in Round 2 of the first year panel or Round 4 of the second year panel, and the source data are missing, PRVSPK42 was set to ‘-1’ (Inapplicable); if the source data are available, PRVSPK42 was set per specifications. Affordability of Medical Treatment, Dental Treatment, and Prescription Medicines Prior to 2018, the Access to Care supplement gathered information on family members’ abilities to receive treatment and receive it without delay. The supplement has been redesigned to gather information on whether treatment was not used or was delayed because of cost. These questions are split into three sections inquiring about medical, dental, and prescription medicine treatments. Each section inquires whether the person did not receive treatment because they could not afford it (AFRDCA42, AFRDDN42, AFRDPM42) or delayed receiving treatment because of cost (DLAYCA42, DLAYDN42, DLAYPM42). A value of ‘1’ (Yes) for these two sets of variables indicates that the person needed treatment but was unable to afford it or was delayed in receiving it because of the cost. A value of ‘2’ (No) for these two sets of variables indicates that either the person did not have an issue affording treatment or the person did not delay treatment because of the cost. Editing the Access to Care Variables Editing consisted primarily of logical editing for consistency with skip patterns. Other editing included the construction of new response values and new variables describing the recoding of “other specify” text items into existing or new categorical values, which are described below. Not all variables or categories that appear in the Access to Care section of the HC questionnaire are included on the file, as some small cell sizes have been suppressed to maintain confidentiality. Recoding of Additional Other Specify Text Items For Access to Care items AC80 and AC90, the “other specify” text responses were reviewed and coded as an existing or new value for the related categorical variable (AC80 and AC90). OTHTYPE_M18 and MDSPECLT_M18 are used to construct the variable TYPEPE42. These variables’ text strings can be recoded to each other’s categories. For example, for persons who indicate that their USC provider is not a medical doctor (PROV.MEDTYPE = 2), the other type of USC provider is other (PROV.OTHTYPE = 91), and the text string collected is “GYNECOLOGIST,” TYPEPE42 would be set to ‘4’ (MD – OB/GYN) instead of ‘11’ (OTHER NON-MD PROVIDER.) 2.5.9 Employment Variables (EMPST31-RTPLN53H)Employment questions were asked of all persons 16 years and older at the time of the interview. Employment variables consist of person-level indicators such as employment status and job-related variables such as hourly wage. All job-specific variables refer to a person’s current main job. The current main job, defined by the respondent, indicates the main source of employment. Most employment variables pertain to the round interview date. The round dates are indicated by two numbers following the variable name; the first number representing the round for Panel 23 persons, the second number representing the round for Panel 24 persons. For example, EMPST31 refers to employment status on the Round 3 interview date for Panel 23 persons and employment status on the Round 1 interview date for Panel 24 persons. With the exception of some health insurance and wage variables, no attempt has been made to logically edit any employment variables. When missing, values were imputed for certain persons’ hourly wages. Due to confidentiality concerns, hourly wages greater than or equal to $96.15 were top-coded to -10 and the number of employees variable was top-coded at 500. With the exception of a variable indicating whether the employer has more than one location (MORE31, MORE42, MORE53), all employer-specific variables refer to the specific establishment that is the location of a person’s current main job. However, a person must have a current main job in order to have information reflected in MORE31, MORE42, and MORE53. The MEPS employment section used dependent interviewing in Rounds 2 through 5. If employment status and certain job characteristics did not change from the previous round, as identified in the Review of Employment (RJ) section, the respondent was skipped through the main employment section. A code of “-2” is used to indicate that the information in question was obtained in a previous round. For example, if the HRWG42X (Round 4 interview date hourly wage for Panel 23 persons or Round 2 interview date hourly wage for Panel 24 persons) is coded as “-2”, it means that hourly wage was collected in a previous round. In this case, users would need to refer to HRWG31X (Round 3 interview date hourly wage for Panel 23 persons or Round 1 interview date hourly wage for Panel 24 persons) to obtain the value for HRWG42X. Note that there may be a value for the Round 3/1 hourly wage or there may be an “Inapplicable” code (-1). The “-2” value for HRWG42X indicates that the person was skipped past the hourly wage question at the time of the Round 4/2 interview. To determine who should be skipped through various employment questions, certain information, such as employment status, had to be asked in every round. Note that “-2” codes do not apply to questions asked in every round, like employment status. Additionally, information on whether the person currently worked at more than one job (MORJOB) or whether the person held health insurance from a current main employer (HELD) was asked in every round, and, therefore, those variables also have no “-2” codes. For Panel 23 persons who have a current main job in Round 3 that continued from Round 1 or 2 of the prior year (2018), the “-2” code is not used. This is because Panel 23 Round 1 and 2 employment variables reside on the Full Year 2018 Public Use release file, not on the current 2019 Full Year Release file, and are therefore not easily accessible for users (and in some cases, the data could be impossible to obtain). For such persons, the values for the variables resulting from skipped questions are copied from the Round 1 or 2 constructed variable on the 2018 Full Year Public Use Release to the 2019 Full Year Public Use Release Round 3 variable, depending on the round in which the job first became the current main job. The accompanying variable RNDFLG31 indicates the round from which these data were collected. For example, if the person has a Round 3 current main job that continues from Round 2 and was first reported as the current main job in Round 2, HRWG31X in the 2019 Full Year Public Use Release will be a copy of the HRWG42X variable from the 2018 Full Year Public Use Release, and RNDFLG31 in the 2019 Full Year Public Use Release will be “2”, indicating the round in which the job was first reported as the current main job. Employment Status (EMPST31, EMPST42, and EMPST53) Employment status was asked for all persons age 16 or older. Allowable responses to the employment status questions were as follows:
These responses were mutually exclusive. A current main job was defined for persons who either reported that they were currently employed and identified a current main job or who reported and identified a job to return to. Therefore, job-specific information such as hourly wage exists for persons not presently working at the interview date but who have a job to return to as of the interview date. The analyst should note that there are cases where EMPST## = 1 or 2 (has current job or job to return to) where DDNWRK19 contains a positive value, indicating the number of times the person lost a half-day or more from work. This is because the responses to the Disability Days questions are independent of the responses to the employment questions. Data Collection Round for Round 3/1 CMJ (RNDFLG31) As mentioned above, for Panel 23, if a person’s Round 3 current main job (CMJ) is a continuation CMJ from Round 2 or Round 1, the value for most “31” variables will be copied forward from the 2018 Full Year Public Use Release from the variable representing the round in which the job was first reported as the CMJ. For persons in Panel 23, RNDFLG31 indicates the 2018 round in which the Round 3 CMJ was first reported as the CMJ and provides a timeframe for the reported wage information and other job details. RNDFLG31 is used with many “31” variables to indicate the round on which the reported information is based. RNDFLG31 is set to “Inapplicable” (-1) for persons in either panel who are under age 16 or who do not have a CMJ in Panel 23 Round 3 or Panel 24 Round 1. For persons who are part of Panel 23, RNDFLG31 is also set to “Inapplicable” (-1) if the person is out-of-scope in the 2019 portion of Round 3. For persons who are part of Panel 24, RNDFLG31 is also set to “Inapplicable” (-1) if the person is out-of-scope in Round 1. For persons who are part of Panel 23, other values for RNDFLG31 are set as follows: 1 continuing Round 3 CMJ reported first in Round 1; 2 continuing Round 3 CMJ reported first in Round 2; 3 job newly reported as current main in Round 3; -15 Round 3 CMJ is a continuation CMJ (wage information and other details were not collected in Round 3) but the Round 2 CMJ record either does not exist or is not the same job. This setting applies even in cases where there is a corresponding Round 1 CMJ. This can occur in rare instances because corrections made to a person’s record in a current file cannot be made to that record in an earlier file due to database processing constraints. Corrections are made based on respondent comments in subsequent rounds that affect employment information previously reported. Users may refer to the Full Year 2018 Jobs file to review the Panel 23 Round 1 through Round 3 rosters for these persons. For persons who are part of Panel 24 and reported a Round 1 CMJ, RNDFLG31 is set to “1” indicating that the job information represented in the “31” variables was collected in Round 1. Self-Employed (SELFCM31, SELFCM42, and SELFCM53) Information on whether an individual was self-employed at the current main job was obtained for all persons who reported a current main job. If an individual reports that they are self-employed at their current main job, they are also asked to identify whether the self-employed business was incorporated, a proprietorship, or a partnership (BSNTY31, BSNTY42, BSNTY53). These questions are not asked of individuals who were not self-employed and, as a result, individuals who are not self-employed are coded with “Inapplicable” (-1). Alternatively, there are several variables that are only constructed for wage earners (not self-employed). These include benefits, employment characteristics, and hourly wage variables (covered in the following two sections). As noted below, self-employed individuals are coded with “Inapplicable” (-1) for benefits, employment characteristics, and hourly wage variables. Benefits and Employment Characteristics (PAYDR31/42/53, SICPAY31/42/53, PAYVAC31/42/53, RETPLN31/42/53, MORE31/42/53, JOBORG31/42/53) Several variables are constructed only for individuals who report not being self-employed at their current main job. These individuals are asked questions to indicate whether the establishment reported as the main source of employment offered any of the following benefits:
They are also asked information on whether the firm had more than one business location (MORE31, MORE42, MORE53) and whether the establishment was a private for-profit, nonprofit, or a government entity (JOBORG31, JOBORG42, JOBORG53). For persons who were self-employed at their current main job, all of the variables detailed in this section were coded as “Inapplicable” (-1). Hourly Wage (HRWG31X, HRWG42X, HRWG53X), Wage Update Variable (DIFFWG31, DIFFWG42, DIFFWG53), and Updated Hourly Wage (NHRWG31, NHRWG42, NHRWG53) Hourly wage was constructed for all persons who reported a current main job that was not self-employment (SELFCM). HRWG31X, HRWG42X, and HRWG53X provide the wage amount reported initially for a person’s current main job. If a current main job continues into subsequent rounds DIFFWG31, DIFFWG42, and DIFFWG53 indicate if the wage has changed since the previous round. If the job continues and there is a different wage at that job, NHRWG31, NHRWG42, and NHRWG53 indicate the new wage amount. The initial hourly wage variables (HRWG31X, HRWG42X, HRWG53X) on this file should be considered along with their accompanying variables – HRHOW31, HRHOW42, and HRHOW53 – which indicate how the respective round hourly wage was constructed. Hourly wage could be derived, as applicable, from a large number of source variables. In the simplest case, hourly wage was reported directly by the respondent. For other persons, construction of the hourly wage was based upon salary, the time period on which the salary was based, and the number of hours worked per time period. If the number of hours worked per time period was not available, a value of 40 hours per week was assumed, as identified in the HRHOW variable. To assist interviewers during collection of wage amounts, CAPI prompts the respondent to confirm wages reported in the Employment Wage section if a wage amount falls outside a specified wage range.
Where there was insufficient information available for calculating the initial hourly wage, the initial hourly wage variables HRWG31X, HRWG42X, and HRWG53X were imputed using a weighted sequential hot-deck procedure for individuals who reported a current main job (and were not self-employed) but did not know their wage or refused to report a wage. Hourly wage for persons for whom employment status was not known was coded as “Cannot be Computed” (-15). Additionally, wages were imputed for wage earners who reported a wage range instead of a specific wage value. For each of these persons, a value was imputed from other persons on the file who did report a specific value that fell within the reported range. The variables HRWGIM31, HRWGIM42, and HRWGIM53 identify persons whose wages were imputed. Note that wages were imputed only for persons with a positive person and/or positive family weight. The variables DIFFWG31, DIFFWG42, and DIFFWG53 indicate whether a person’s wage amount was different in the current round (from the previous round) at a continuing, current main job (CMJ). NHRWG31, NHRWG42, and NHRWG53 contain the updated wage amount in cases where a person indicates a change in wages (DIFFWG = 1). While the question regarding wage changes pertains to the primary wage at the main job, occasionally respondents update a person’s supplemental wage at the main job. In these cases, users should note that the HRWG31X, HRWG42X, HRWG53X variable may contain the same value as the NHRWG31, NHRWG42, NHRWG53 variable. For all Panel 24 Round 1 persons, DIFFWG31 and NHRWG31 are set to “Inapplicable” (-1) because this was the first round that wages could be reported for those persons. In Rounds 2 through 5, no imputation was performed on NHRWG31, NHRWG42, and NHRWG53. Instead, where an updated wage amount is “Don’t Know” (-8) or is “Refused” (-7), NHRWG31, NHRWG42, and/or NHRWG53 is set to “Cannot be Computed” (-15). For persons whose hourly wage variable HRWG31X, HRWG42X, and/or HRWG53X was imputed and the respondent provides an updated wage amount in a subsequent round, the new wage, NHRWG31, NHRWG42, and/or NHRWG53, is not presented. Instead, NHRWG31, NHRWG42, and/or NHRWG53 is set to “Initial Wage Imputed” (-13) to indicate that the initial HRWG31X, HRWG42X, and/or HRWG53X was imputed. Users can refer to the 2019 Full-Year Jobs PUF to obtain updated wage amounts as reported for these jobs. Wage outlier editing was performed using established processes. In these processes, some wage information was logically edited for consistency. Edits were performed under two main circumstances:
In all cases that result in an edit, a complete review of wage and employment history is performed; in some cases, comparisons are made to employment at similar establishments within the MEPS as well as to data reported and summarized by the Bureau of Labor Statistics. Wages were edited for 31 persons in Panel 24 and 21 persons in Panel 23. For reasons of confidentiality, the hourly wage variables were top-coded. A value of –10 indicates that the hourly wage was greater than or equal to $96.15. The wage top-code process uses the highest calculated wage for an individual regardless of whether it was reported in the HRWG31X, HRWG42X, and HRWG53X or NHRWG31, NHRWG42, and NHRWG53 variable. All wages for a person were top-coded if any wage variable was at or above the top-code amount. In order to protect the confidentiality of persons across deliveries, the same top-code amount used in this 2019 Full-Year Consolidated file was also applied to the 2019 Jobs file. Because a person can have other jobs besides a current main job which are included in the corresponding 2019 Jobs file, wages at these other jobs were reviewed in the top-coding process. In some cases for these persons, wages reported at the current main job were below the top-code amount while the wage at another job had to be top-coded. To further protect the confidentiality of such persons across deliveries, wages reported at all jobs in the 2019 Jobs file were top-coded and the wages at their current main job (HRWG31X, HRWG42X, HRWG53X,NHRWG31, NHRWG42, and NHRWG53) included in this 2019 Full-Year Consolidated file were also top-coded. Health Insurance (HELD31X, HELD42X, HELD53X, OFFER31X, OFFER42X, OFFER53X, CHOIC31, CHOIC42, CHOIC53, DISVW31X, DISVW42X, DISVW53X, OFREMP31, OFREMP42, OFREMP53) There are several employment-related health insurance measures included in this release: health insurance held at a current main job (HELD31X, HELD42X, HELD53X), health insurance offered through a current main job (OFFER31X, OFFER42X, OFFER53X), health insurance offered to anyone through the employer (OFREMP31, OFREMP42, OFREMP53), and choice of health plans available through the current main job (CHOIC31, CHOIC42, CHOIC53). This collection of variables reflects the insurance status in the current round. The variables are logically edited for consistency for each round. MEPS asks if the person holds health insurance through the current main job (HELD) in the first round in which a person is reported as having that job. If the person does not hold health insurance at the job, then a follow-up question is asked as to whether the person was offered insurance but declined coverage (OFFER). If the person neither holds nor was offered health insurance at the job, then an additional question is asked to determine whether any other employees at the current main job were offered health insurance (OFREMP). If the person either holds or was offered insurance at the job, then an additional question is asked to determine whether a choice of health plans is available at the job (CHOIC). In the rounds after the job is first reported, the Review of Jobs (RJ) section has the same series of questions with one exception, it does not ask whether there is a choice of health insurance plans at an employer. Choice of health insurance plan is only asked in the round the job was first reported (in the Employment section). In rounds after the job is first reported, a “held” question (whether a person now holds health insurance through the employer) is asked in the Review of Jobs section. This is to determine if there has been any change in coverage. RJ70 (HELD) is asked if insurance was offered, but not taken by the employee when the job was first reported and no coverage has been reported since the initial round. RJ80 (HELD) is asked where:
MEPS then includes several clarifying questions regarding health insurance status and availability to the jobholder through an employer. Where the person does not report, does not know, or refuses to indicate the insurance status at RJ70, or reports no coverage at RJ80, the respondent is asked a series of OFFER questions to determine if the jobholder was offered insurance and, if not, whether the employer offers health insurance to anyone at the firm. Lastly, when a respondent indicates that the jobholder of a reviewed job neither holds nor was offered health insurance at the job, the respondent is asked if any other employees at the job were offered health insurance (OFREMP). If a person does hold insurance through their job, then that person is not asked the offer question and the OFFER variable is automatically set to “Yes” (1). Data users should note that OFREMP is automatically set to 1 in cases where the jobholder has health insurance coverage through the job (HELD=1) or in cases where health insurance is offered to the employee at their job (OFFER=1). Responses in the Employment and Review of Jobs sections for health insurance held were recoded to be consistent with the variables in the Health Insurance section of the survey. For persons who responded in the Employment section or Review of Jobs section that they held health insurance coverage through the employer and then disavowed the coverage in the Health Insurance section, MEPS now includes follow-up questions regarding whether health insurance is offered (either to the employee or any other employee depending on responses to questions) and whether more than one plan is available. This information is used in an edit process whereby responses to these variables in the Health Insurance section are transferred into the Employment section or Review of Jobs section. Consequently, more information is now available on OFFER, OFREMP, and CHOIC. Consistent with prior years, the round-specific flag variable DISVW continues to be constructed and reflects the disavowal at the current main job in the round. Hours (HOUR31, HOUR42, HOUR53) The hours variables refer to usual hours worked per week at the current main job. Note that, in cases where the respondent estimated hours worked per week at 35 hours or more, HOUR31, HOUR42, and HOUR53 were set to ‘40.’ Temporary (TEMPJB31, TEMPJB42, TEMPJB53) and Seasonal (SSNLJB31, SSNLJB42, SSNLJB53) Jobs The temporary job variables (TEMPJB31, TEMPJB42, TEMPJB53) indicate whether a newly reported current main job lasts for only a limited amount of time or until the completion of a project. The seasonal job variables (SSNLJB31, SSNLJB42, SSNLJB53) indicate whether the newly reported current main job is only available during certain times of the year. SSNLJB is “Yes” (1) if the job is only available during certain times of the year; SSNLJB is “No” (2) if the job is year round. Teachers and other school personnel who work only during the school year are considered to work year round. Both variables are set on current main jobs whether a person is self-employed or not. These questions are asked only in the round the job is newly reported. Consequently, in rounds following the initial report, a code of “Determined In Previous Round” (-2), is used to indicate that the information in the question was obtained in a previous round. This differs from some previous files where both questions were asked in each round and -2 was not an allowed value. Analysts using either of these variables over multiple years of MEPS should refer to documentation for each year to assure consistency for the variable. Number of Employees (NUMEMP31, NUMEMP42, NUMEMP53) NUMEMP indicates the number of employees at the location of the person’s current main job. Due to confidentiality concerns, this variable has been top-coded at 500 or more employees. For respondents who do not know the specific number of employees at the establishment, a categorical question is offered as an alternative. In these cases, a numerical value for NUMEMP is constructed using a median estimated size calculated from donors within the reported categorical range. CAPI does not accept an establishment size value of 0 to indicate the total number of employees working at a self-employed business. Where a person is not self-employed at a job, an establishment size of 0 is allowed. NUMEMP is set to “Cannot be Computed” (-15) for these cases. Beginning in Panel 24 Round 3 and Panel 23 Round 5, categorical estimates of establishment size at question EM440 changed slightly. Range boundaries for values between 4 and 9 reflect those used prior to 2017. This information is used when calculating medians used when setting NUMEMP31, NUMEMP42, and NUMEMP53. For continuity purposes, however, ranges used in calculating medians were not revised from previous years; they continue to conform to prior categories. Categorical Estimates of Establishment Size
Other Employment Variables Information about industry and occupation types for a person’s current main job at the interview date is also contained in this release. Based on verbatim text fields collected during the interview, numeric industry and occupation codes are assigned by trained coders at the Census Bureau. The coders used 2007 Census Industry and 2010 Census Occupation Coding schemes, which were developed for the Bureau’s Current Population Survey and American Community Survey. Users should note that coding schemes are comparable for the FY 2010 through FY 2019 data files. Earlier versions of Census coding schemes were used on files prior to FY 2010. Current main jobs were initially coded at the 4-digit level for both industry and occupation. Then, for confidentiality reasons, these codes were condensed into broader groups for release on the file. INDCAT31, INDCAT42, and INDCAT53 represent the condensed industry codes for a person’s current main job at the interview date. OCCCAT31, OCCCAT42, and OCCCAT53 represent the condensed occupation codes for a person’s current main job at the interview date. This release incorporates crosswalks showing how the detailed 2007 Census industry codes (Appendix 1) and 2010 Census occupation codes (Appendix 2) were collapsed into the condensed codes on the file. The schemes used in this file can be linked directly to the 2007 North American Industry Code System (NAICS) and the 2010 Standard Occupation Code scheme (SOC) by going to the U.S. Census Bureau website where a variety of additional crosswalks is also available. Information indicating whether a person belonged to a labor union (UNION31, UNION42, and UNION53) is also contained in this release. The month and year that the current main job started for Rounds 3, 4, and 5 of Panel 23 and Rounds 1, 2, and 3 of Panel 24 are provided in this release (STJBMM31, STJBYY31, STJBMM42, STJBYY42, STJBMM53, and STJBYY53). In FY 2019, STJBYY31, STJBYY42, and STJBYY53 are bottom coded to a value of ‘1949’ to preserve age confidentiality. This value is calculated by taking the delivery year of 2019 and subtracting the age top code value of 85, then adding back 15, the age of a person in the year before entering the work force as defined in MEPS. Thus, the bottom code value will be different in each delivery year. For Panel 23 Round 3 jobs that were first reported in Round 1 or Round 2, the bottom code continues to be set to the value calculated in the FY 2018 delivery year, 1948. There are two measures included in this release that relate to a person’s work history over a lifetime. One indicates whether a person ever retired from a job as of the Round 5 interview date for Panel 23 persons or the Round 3 interview date for Panel 24 persons (EVRETIRE). The other indicates whether a person ever worked for pay as of the Round 5 interview date for Panel 23 persons or the Round 3 interview date for Panel 24 persons (EVRWRK). The latter was asked of everyone who indicated that they were not working as of the round interview date. Therefore, anyone who indicated current employment or who had a job during any of the previous or current rounds was skipped past the question identifying whether the person ever worked for pay. These individuals were coded as “Inapplicable” (-1). All persons who ever reported a job and were 55 years or older as of the round interview date were asked if they “ever retired”. Since both of these variables are not round specific, there are no “Determined in Previous Round” (-2) codes. This release contains variables indicating the main reason a person did not work since the start of the reference period (NWK31, NWK42, and NWK53). If a person was not employed at all during the reference period (at the interview date or at any time during the reference period) but was employed some time prior to the reference period, the person was asked to choose from a list the main reason he or she did not work during the reference period. The “Inapplicable” (-1) category for the NWK variables includes:
A measure of whether an individual had more than one job on the round interview date (MORJOB31, MORJOB42, and MORJOB53) is provided on this release. In addition to those under 16 and those individuals who were out-of-scope, the “Inapplicable” (-1) category includes those who did not report having a current main job. Because this is not a job-specific variable, there are no “Determined in Previous Rounds” (-2) codes. This release contains variables indicating if a current main job changed between the third and fourth rounds for Panel 23 persons or between the first and second rounds for Panel 24 persons (CHGJ3142) and between the fourth and fifth rounds for Panel 23 persons or between the second and third rounds for Panel 24 persons (CHGJ4253). In addition to the “Inapplicable” (-1), “Refused” (-7), “Don’t Know” (-8), and “Cannot be Computed” (-15) categories, the change job variables were coded to represent the following: 1 person left previous round current main job and now has a new current main job; 2 person still working at the previous round’s current main job but, as of the new round, no longer considers this job to be the current main job and defines a new current main job (previous round’s current main job is now a current miscellaneous job); 3 person left previous round’s current main job and does not have a new job; 4 person did not change current main job. Finally, this release contains the reason given by the respondent for the job change (YCHJ3142 and YCHJ4253). The reasons for a job change were listed in the CAPI questionnaire and a respondent was asked to choose the main reason from this list. In addition to those out-of-scope, those under 16, and those not having a current main job, the “Inapplicable” category for YCHJ3142 and YCHJ4253 includes workers who did not change jobs. Employment Variables Imputed for Missing Values (EMPST31H – RTPLN53H) To further assist analysts, a series of fully-imputed employment variables is available on the Full Year Consolidated Data File (FY PUF). For the years 2000 to 2013 these variables can be found on MEPS HC-131 (MEPS Employment Variables 2000-2013). For the years 2014 and beyond, these variables can be found in the FY PUF for each data year. The fully-imputed variables in this file are developed from the constructed Employment variables in the 2019 FY PUF. Observations for these employment variables with values of -7 (“Refused”), -8 (“Don’t Know”) or -15 (“Cannot be Computed”) were imputed using weighted sequential hot-decking. The imputations were performed separately for each MEPS HC panel across the five survey rounds of the MEPS. First, all missing values of a given variable were imputed for Round 1. If a person remained in the same job in Round 2, and the MEPS questionnaire did not ask for updated job information (i.e., if the variable on the FY PUF was coded as -2), then the value for that variable was pulled forward from Round 1 to Round 2 (including values that had been imputed in Round 1). After pulling values forward from Round 1, any remaining missing values were imputed for Round 2. This process was repeated for Rounds 3-5. For Panel 24, the imputed employment variables use constructed employment variables from Round 1, 2 and 3 data on this file. For Panel 23, Rounds 3, 4, and 5 data from the current file are used as well as data from Rounds 1 and 2 from the 2018 Full-Year PUF. Users who want to combine data on all five rounds for an individual in Panel 23 should use 2018 data for Rounds 1 and 2 from MEPS HC-209, and 2019 data for Rounds 3, 4 and 5 from the current file. (Note that MEPS HC-209 also has Round 3 information for Panel 23, but the 2019 PUF has the most up-to-date version of Round 3 information and is the most consistent with 2019 Round 4 and 5 variables.) Following imputation, no values of -2, -7, -8, or -15 remain on any variable. Due to skip patterns, the majority of -1s (question was not asked due to skip pattern) remain. For reasons of confidentiality, values of -10 (hourly wage was top-coded at $96.15) also remain and employer size (number of employees in establishment) is top-coded at 500. Variable Naming The names of the imputed variables are similar to the names of the corresponding constructed variables in this file. An ‘H’ suffix is added and the resulting name is shortened to 8 characters when necessary (e.g., the imputed version of SELFCM31 is SLFCM31H). The variables CMJHLD31/42/53 differ from this naming convention because they are not imputed (they contain no missing values) but were constructed using information from the Person Round Plan (PRPL) File (MEPS HC-215). CMJHLD31/42/53 may be compared with the constructed Employment variables HELD31X/42X/53X. Both of these sets of variables provide information on the insurance coverage individuals obtain through their current main jobs. However, these variables may differ since they are constructed from two different data files and because the CMJHLD31/42/53 variables capture information on some additional sources of employment-related insurance that were identified in the insurance section of the instrument while the HELD31X/42X/53X variables only contain information on sources of coverage identified in the employment section. In addition, the values of CMJHLD31 for Panel 23 observations reflect coverage in Round 3 in the 2019 PRPL file as well as in the 2018 PRPL file. Note that the variables CMJHLD31/42/53 are included on this file because they were used to perform logical edits on the OFFER31H/42H/53H and OFEMP31H/42H/53H variables (edits are described below). The CMJHLD31H/42H/53H variables were used to edit the OFFER31H/42H/53H and OFEMP31H/42H/53H variables (rather than the HELD31X/42X/53X variables) because they were more consistent with the other health insurance variables on the FY PUF for each year. The following table provides the name of the constructed Employment variables that correspond with each imputed Employment variable.
* Both CMJHLD and HELDX reflect the insurance status at a current main job but are constructed from different sources of data. See the text for a description of possible differences in these variables. CMJHLD is not an imputed version of HELDX. Imputation Strategy The first variables to be imputed were the employment status variables (EMPST31H/42H/53H) which identify all persons (EMPST31H/42H/53H = 1 or 2) who should have valid information related to their current main job. EMPST31H/42H/53H are created from EMPST31/42/53. The EMPST31/42/53 variables have separate response categories for individuals who were “employed during the reference period” and those who were “not employed with no job to return to.” In the imputed variables EMPST31H/42H/53H these responses are collapsed into a single category for analytic purposes.
Respondents with EMPST31H/42H/53H equal to 1 or 2 go through the imputation process. Respondents with EMPST31H/42H/53H equal to -1 or 34 have values of -1 for all remaining imputed employment variables. The next set of variables to be imputed were the self-employment/wage-earner variables (SLFCM31H/42H/53H) which determine skip patterns for the remaining variables (e.g., self-employed persons are not asked about wages). Many of the remaining variables were imputed separately for wage-earners and the self-employed for the following reasons: 1) self-employed and wage-earners were asked different sets of questions about their current main jobs; 2) even when variables were asked for both groups, the quality of the imputations was improved by specifying separate sets of class variables tailored to the wage-earner and self-employed populations. The weighted sequential hot decking process requires class variables to impute missing values. These class variables were identified with regression models in order to identify the predictive quality of a set of variables for each variable to be imputed. The set of possible class variables, includes age, sex, region, educational attainment, industry and occupation code, and the set of variables have been consistently used to impute a given variable across panels. As mentioned above, self-employed and wage-earners were asked different sets of questions about their current main job. These variables can be categorized into the following sets: Variables with Valid Data for Wage-Earners but Not for Self-Employed Individuals
Variables with Valid Data for Self-Employed Individuals but Not for Wage-Earners
Variables with Valid Data for All Workers
Variables with Valid Data for All Workers Except for Self-Employed Individuals with No Employees (i.e., persons for whom SLFCM31H/42H/53H = 1 and NMEMP31H/42H/53H = 1 within each round)
Additional Detail on Specific Variables Hourly Wage (HRWG31H, HRWG42H, HRWG53H) Valid data for imputed hourly wages is available for all wage-earners (SLFCM31H/42H/53H equal to 2). The values for the imputed hourly wage variables (HRWG31H/42H/53H) reflect the most up-to-date version of hourly wages for the wage-earner in each round. By contrast, the constructed hourly wage variables (HRWG31X/42X/53X) identify the wage reported in the round a current main job is first reported. Information on any wage changes after that round are contained in the variables DIFFWG31/42/53 and NHRWG31/42/53. These variables, as well as HRWG31X/42X/53X are used in the construction of the imputed hourly wage variables. For reasons of confidentiality, the hourly wage variables are top-coded. Like the constructed hourly wage variables, imputed hourly wages greater than or equal to $96.15 are top-coded to a value of -10. Union Membership (UNION31H/42H/53H) In addition to using weighted sequential hot-decking techniques, individuals who were identified as being employed by the military had their union membership status logically edited to -1 (inapplicable). Health Insurance (CMJHLD31, CMJHLD42, CMJHLD53, OFFER31H, OFFER42H, OFFER53H, OFEMP31H, OFEMP42H, OFEMP53H) This file includes several employment-related health insurance variables, CMJHLD31/42/53, OFFER31H/42H/53H, and OFEMP31H/42H/53H. These variables are valid for wage-earners (SLFCM31H/42H/53H = 2) and self-employed individuals with employees (SLFCM31H/42H/53H = 1 and NMEMP31H/42H/53H > 1). The variables CMJHLD31/42/53 are constructed from the Person-Round-Plan (PRPL) public use file and indicate whether the person held insurance coverage from his/her current main job at some point during the round. This is primarily defined using the PRPL public use file variable CMJINS which identifies insurance obtained through a current main job, and STATUS1-24, which indicates whether the coverage is in effect during the round. Since Round 3 crosses two calendar years, CMJHLD31 for Panel 23 respondents indicates that the person held coverage during the portion of Round 3 in either the 2018 or 2019 PRPL public use file for the individual. The variables OFFER31H/42H/53H indicate whether the person was offered (was eligible for) insurance at their current main job at some point during the round. For records that had a value of -15, valid reported values for OFFER31H/42H/53H were brought forward from a previous round (including imputed values from that round) if the person did not change jobs before any further imputations were performed. The variables OFEMP31H/42H/53H indicate whether an employer offered health insurance to any employees in the establishment and rely on OFFER31H/42H/53H during their construction. OFFER31H/42H/53H and the related variable OFEMP31H/42H/53H were logically edited as follows. If a person indicates that they held insurance from their current main job (CMJHLD31/42/53 = 1) then OFFER31H/42H/53H was set equal to 1. For Round 3, OFFER31H/53H was set to 1 if the person held coverage at any point in Round 3 in either calendar year. If a person indicated that they held insurance (CMJHLD31/42/53 = 1) or were offered insurance (OFFER31H/42H/53H = 1) at their current main job, then OFEMP31H/42H/53H, the variable indicating that the employer offered insurance to at least one employee, was set equal to 1. Number of Employees (NMEMP31H, NMEMP42H, NMEMP53H) Like the corresponding constructed NUMEMP31/42/53, NMEMP31H/42H/53H indicate the number of employees at the location of the person’s current main job. Due to confidentiality concerns, this variable has been top-coded at 500. Missing value imputation is done using weighted sequential hot-decking techniques. Note that the definition of NMEMP31H/42H/53H, like that for NUMPEMP31/42/53, differs for wage-earners and self-employed individuals. For wage-earners, it represents the size of the worker’s establishment. For self-employed individuals, it represents the size of the self-employed individual’s entire business. 2.5.10 Health Insurance Variables (TRIJAyyX-PMEDPY53)Throughout Section 2.5.10 references to yy represent the year (19), references to mm indicate the month (JA through DE), and references to rr indicate a combination of rounds (31/42/53, where the first r denotes the interview round for Panel 23 and the second r denotes the round for Panel 24) or the end of the calendar year (19). Beginning Panel 22 Round 3/Panel 23 Round 1, design changes to the health insurance section may impact trend analyses. Analysts should note that a series of questions were added to the HX section of the questionnaire to confirm whether a person who did not initially report any comprehensive coverage during a round has insurance. Starting at HX210, questions were presented to respondents who at that point in the instrument had not yet reported any sources of health insurance coverage, or only reported a source of health insurance without hospital and physician benefits, to determine whether they had coverage that included hospital and physician benefits. If the respondent answered affirmatively at HX210, subsequent questions identified the specific type of coverage (e.g. Medicaid, Private, etc.). This may cause analysts to see changes to the insurance variables–particularly, changes to the monthly health insurance coverage indicators PUBmmyyX, PRImmyyX, INSmmyyX; and the summary health insurance coverage indicators UNINSyy, INSCOVyy, INSURCyy, PUBrrX, PUBATrrX, PRIVrr, PRIVATrr, INSrrX, and INSATrrX. Secondly, respondents were allowed to report both Medicaid and other public hospital/physician coverage. Previously, these types of coverage were mutually exclusive. Beginning FY 2018, the variables previously constructed to identify other public coverage (OTPUBArr, OTPAATrr, OTPUBBrr, OTPBATrr; OPAmmyy, OPBmmyy, OPAEVyy, and OPBEVyy) will no longer be included in this file. Instead, the constructed variables GOVTArr, GOVTBrr, GOVTCrr, GOVAATrr, GOVBATrr, GOVCATrr, GVAmmyy, GVBmmyy, GVCmmyy, GVAEVyy, GVBEVyy, and GVCEVyy have been added to this file to identify any report of other public coverage (variables denoted with an “A”), other public coverage that is an HMO (variables denoted with a “B”), and other public coverage where a premium is paid (variables denoted with a “C”). These variables are not mutually exclusive. Analysts should be aware that they might see changes in coverage trends in the constructed variables relating to Medicaid, edited Medicaid, or Other Public coverage as well as respondents reporting both after FY 2018. These variables include the monthly insurance coverage indicators MCDmmyy, MCDmmyyX, GVAmmyy, GVBmmyy, and GVCmmyy; the summary health insurance coverage indicators MCDEVyy, GVAEVyy, GVBEVyy, and GVCEVyy; and the other health insurance coverage variables MCAIDrr, MCAIDrrX, MCDATrrX, GOVTArr, GOVTBrr, GOVTCrr, GOVAATrr, GOVBATrr, and GOVCATrr. Beginning FY 2018, the variables VERFLG31, VERFLG42, and VERFLGyy were constructed to indicate the round in which comprehensive health insurance coverage was first reported through the verification series of questions collected in the loop that starts at HX210 (HXLoop_40). These values will be carried through to subsequent rounds (e.g., from VERFLG31 to VERFLG42) if the coverage initially added through the verification loop continues, and no other comprehensive source of coverage is reported for that person outside of the verification loop. If previously reported coverage through the verification series ends and, in a future round, new comprehensive coverage is reported through the verification loop, then the VERFLG31/42/yy variable will reflect the corresponding round of the newly reported coverage. The VERFLG variables were set to ‘95’ to indicate that: 1) coverage was reported outside verification; 2) the person did not have coverage; or 3) the person would have been assigned edited coverage even though they may have reported coverage in the verification loop. As an example of the latter, a person who is age 65 or older and reports Medicare coverage through verification but also reports receipt of social security would have MCAREX set to ‘1’ because of the report of social security so the report of coverage in the verification module would not have changed their coverage status in the MEPS. In FY 2019, the construction of the VERFLG variables was modified such that all persons ages 65 and older who gained edited Medicare through the Medicare coverage of their spouse also have a value of 95 in the verification variables, provided that the coverage of the spouse was added outside of the verification series. In addition to the new verification module, other changes were made beginning FY 2018 to the health insurance questions that may affect the continuity of estimates. These changes include modifications to the Medicaid/SCHIP, and TRICARE/CHAMPVA questions to ask if each person in the household is covered using the person’s name in the question text (e.g. “Was Person 1 covered?” “What about Person 2?” etc.). Additionally, in Rounds 2 and 3, respondents are now required to answer “Yes” or “No” for each person individually when reviewing coverage from a previous round for these insurance sources. Changes to the Medicare Round 1 series were also made to probe separately for persons in the RU who were 65 years of age or older versus RU members who were under 65 years of age. Similar to the Medicaid and TRICARE series, Medicare coverage questions were asked for each RU member who was at least 65 years old. The aforementioned changes to the administration of the insurance section may also be evident in the Managed Care Variables (TRISTyyX–PRVHMOyy) because more respondents are now more likely to be asked about managed care. Beginning FY 2018, persons who report coverage under Indian Health Service (IHS) will be identified in the constructed variables IHSrr, IHSATrr, and IHSmmyy. Persons reporting only IHS coverage will not be considered covered for the summary insurance measures PUBmmyyX, PUByyX, INSmmyyX, INSCOVyy, and INSURCyy. Persons who report coverage under Veteran’s Administration (VA) can be identified in this file in the constructed variables VAPROGrr, VAPRATrr, VAEVyy, as well as the monthly variables VAPRmmyy. Lastly, respondents were no longer asked about state-specific program participation in non-comprehensive coverage, so variables related to this type of coverage were no longer constructed (STAPRrr, STPRATrr, and STAmmyy). Monthly Health Insurance Indicators (TRIJAyyX-INSDEyyX) Constructed and edited variables are provided that indicate any coverage in each month of 2019 for the sources of health insurance coverage collected during the MEPS interviews (Panel 23 Rounds 3 through 5 and Panel 24 Rounds 1 through 3). In Rounds 2, 3, 4, and 5, insurance that was in effect at the previous round’s interview date was reviewed with the respondent. Most of the insurance variables have been logically edited to address issues that arose during such reviews in Rounds 2, 3, 4, and 5. One edit to the private insurance variables corrects for a problem concerning covered benefits that occurred when respondents reported a change in any of their private health insurance plan names. Additional edits address issues of missing data on the time period of coverage for both public and private coverage that was either reviewed or initially reported in a given round. Additional edits, described below, were performed on the Medicare and Medicaid or State Children’s Health Insurance Program (SCHIP) variables to assign persons to coverage from these sources. Observations that contain edits assigning persons to Medicare or Medicaid/SCHIP coverage can be identified by comparing the edited and unedited versions of the Medicare and Medicaid/SCHIP variables. Starting October 1, 2001, persons 65 years and older have been able to retain TRICARE coverage in addition to Medicare. Therefore, unlike in earlier MEPS public use files, persons 65 years and older do not have their reported TRICARE coverage (TRIJAyyX – TRIDEyyX) overturned. TRICARE acts as a supplemental insurance for Medicare, similar to Medigap insurance. Public sources include Medicare, TRICARE/CHAMPVA, Medicaid, SCHIP, and other public hospital/physician coverage. IHS is not included as a public source of coverage. Medicare Medicare (MCRJAyy – MCRDEyy) coverage was edited (MCRJAyyX – MCRDEyyX) for persons age 65 or over. Within this age group, individuals were assigned Medicare coverage if:
Note that age (AGErrX) is checked for edited Medicare, however date of birth is not considered. Edited Medicare is somewhat imprecise with regard to a person’s 65th birthday. Medicaid/SCHIP and Other Public Hospital/Physician Coverage Questions about other public hospital/physician coverage were asked in an attempt to identify Medicaid or SCHIP recipients who may not have recognized their coverage as such. Beginning Panel 22 Round 3/Panel 23 Round 1, these questions were asked even if a respondent reported Medicaid or SCHIP directly. (Previously, other public hospital/physician coverage was only asked for respondents who did not report Medicaid or SCHIP.) Respondents reporting other public hospital/physician coverage were asked follow-up questions to determine if the coverage was through a specific Medicaid HMO or if it included some other managed care characteristics. Respondents who identified managed care from either source were asked if the recipient paid anything for the coverage and/or if a government source paid for the coverage. The Medicaid/SCHIP variables (MCDJAyy – MCDDEyy) have been edited (MCDJAyyX – MCDDEyyX) to include persons who paid nothing for their other public hospital/physician insurance when such coverage was through a Medicaid HMO or reported to include some other managed care characteristics. To assist users in further editing sources of insurance, this file contains variables constructed from the other public hospital/physician series that indicate:
The variables GVAJAyy – GVADEyy, GVBJAyy – GVBDEyy, and GVCJAyy – GVCDEyy are provided only to assist in editing and should not be used to make separate insurance estimates for these types of insurance categories. Any Public Insurance in Month The file also includes summary measures that indicate whether or not a sample person has any public insurance in a month (PUBJAyyX – PUBDEyyX). Persons identified as covered by public insurance are those reporting coverage under TRICARE, Medicare, Medicaid or SCHIP, other public hospital/physician programs, or Veteran’s Administration (VA). IHS is not included as a public source of coverage. Note that further edits may be made to the public insurance variables in later MEPS data releases to address cases where private coverage through a federally-facilitated, state-based or state partnership exchange/marketplace may have been originally reported as public insurance. These potential edits could affect the variables MCAIDyyX, GOVTAyy, GOVTByy, GOVTCyy, and PUByyX. Private Insurance Variables identifying private insurance in general (PRIJAyy – PRIDEyy) and specific private insurance sources [such as employer/union group insurance (PEGJAyy – PEGDEyy); non-group (PNGJAyy – PNGDEyy); other group (POGJAyy – POGDEyy)]; and private insurance through a federally-facilitated, state-based or state partnership exchange/marketplace (PRXJAyy – PRXDEyy) were constructed. Private insurance sources identify coverage in effect at any time during each month of 2019. Separate variables identify covered persons and policyholders (policyholder variables begin with the letter “H”, e.g., HPEJAyy – HPEDEyy). These variables indicate coverage or policyholder status within a source and do not distinguish between persons who are covered or are policyholders on one or more than one policy within a given source. In some cases, the policyholder was unable to characterize the source of insurance (PDKJAyy – PDKDEyy). Prior to FY 2018, persons covered under policyholders living outside the RU were identified in POUJAyy – POUDEyy and PROUTrr. Beginning FY 2018, the constructed variables PRIEUOrr and PRINEOrr are included. PRIEUOrr indicates coverage from a policyholder living outside the RU where the source is through an employer, and PRINEOrr indicates coverage from a policyholder living outside the RU where the source is not through an employer. These variables are based on responses to a follow-up question for respondents who indicate coverage from a policyholder outside the household. The question HP130 asks “Is the {INSURANCE SOURCE NAME} health coverage {POLICYHOLDER} has through an employer or previous employer?” If the respondent’s answer to HP130 was unknown, the person’s coverage is now included in PRIDKrr. An individual was considered to have private health insurance coverage if, at a minimum, that coverage provided benefits for hospital and physician services (including Medicare supplemental coverage). Note, however, that persons covered by private insurance through an exchange/marketplace (PRSTXrr and PRXJAyy – PRXDEyy) were considered to have private health coverage if that coverage provided hospital/physician services, but excluded coverage that was explicitly identified as Medicare supplemental coverage (HX620/OE130=5). If a person reported Medicare supplemental coverage through the exchange/marketplace, then the source of the insurance purchased was edited to reflect coverage “from a professional association” (HP40=1) or coverage “from a group or association” (HX200/HX300=1). Further descriptions of the exchange variables are detailed below. Sources of insurance with missing information regarding the type of coverage were assumed to contain hospital/physician coverage. Persons who reported private insurance that did not provide hospital/physician insurance were not counted as privately insured. Coverage indicated by these variables may be from any type of job whereas the employment section insurance variables delivered on this file reflect only coverage through a current main job. Health insurance through a job or union (PEGJAyy – PEGDEyy) was initially asked about in the Employment section of the interview and later confirmed in the Health Insurance section. Beginning FY 2018, the constructed variables that were used to identify insurance reported through a job classified as self-employed with firm size of 1 (PRSJAyy – PRSDEyy; HPSJAyy – HPSDEyy; PRISrr) will no longer be included in this file. Insurance that was reported in the employment section through a job classified as self-employed with firm size of 1 is now included in the other private insurance variables: PEGJAyy – PEGDEyy; PNGJAyy – PNGDEyy; POGJAyy – POGDEyy; PDKJAyy-PDKDEyy; HPEJAyy-HPEDEyy; HPNJAyy-HPNDEyy; HPOJAyy-HPODEyy; HPDJAyy-HPDDEyy; and PRIEUrr, PRINGrr, PRIOGrr, and PRIDKrr based on responses at HP40. Private insurance that was not employment-related (POGJAyy – POGDEyy, PNGJAyy – PNGDEyy, PDKJAyy – PDKDEyy, PNEJAyy – PNEDEyy, and PRXJAyy – PRXDEyy) was reported in the Health Insurance section only. Beginning in Panel 14 Round 5/Panel 15 Round 3, “High Risk Pool” was added to the list of categories (HX03 =10 and HX23 =13). Beginning FY 2010, High Risk Pool was included in all Other Group insurance categories. Beginning in Panel 22 Round 3/Panel 23 Round 1, the response category “High Risk Pool” was removed from HP40, HX200, and HX300. “Federal/State Exchange” is included in the list of private insurance categories (HP40=8 and HX200/HX300 =11). Information on federal/state exchanges is also collected at question HP50 (“Is this coverage through {state exchange name}?”) for respondents reporting insurance from a group, directly from an insurance company or HMO, from an insurance agent or from an “other” unspecified source and at OE40 in Round 3 only (“Is this coverage through {state exchange name}?”) for respondents who previously reported private insurance coverage from an insurance company or HMO, or from an insurance agent that was not through an exchange/marketplace. Note that the state-specific name for the exchange/marketplace was used when asking these questions and was also used on the list of private insurance categories at HP40, HX200, and HX300. The variables PRSTXrr have been constructed to include persons less than 65 years old who report private insurance through a federally-facilitated, state-based or state partnership exchange/marketplace at HP40, HX200, or HX300, or persons 65 years old or older who report private insurance through a federally-facilitated, state-based or state partnership exchange/marketplace at HP40, HX200, or HX300 and who were not covered by Medicare. In addition, persons who reported a source of insurance at HX200 or HX300 that was not through an exchange/marketplace (e.g. through a group or directly from an insurance company) but who answered yes to HP50 or OE40 were also classified as having exchange/marketplace coverage instead of being assigned to the category they originally reported. In addition to reporting coverage through an exchange/marketplace, coverage needed to have been identified as hospital/physician coverage at HX620/OE130 (=1 or missing ( -7, -8)), but not identified as having Medicare supplemental coverage (HX620/OE130=5). The variables PRSTXrr contain information on private coverage that was reported as obtained through a federally-facilitated, state-based or state partnership marketplace. Consistent with the approach used in the Current Population Survey and the National Health Interview Survey, MEPS respondents reporting public coverage were asked whether the public coverage was obtained through a federal or state marketplace in case respondents were confused about whether the source of coverage was public or private. Responses to these questions were not used to edit the PRSTXrr variables. Any Insurance in Month The file also includes summary measures that indicate whether or not a person has any insurance in a month (INSJAyyX – INSDEyyX). Persons identified as insured are those reporting coverage under TRICARE, Medicare, Medicaid, SCHIP, other public hospital/physician or private hospital/physician insurance (including Medigap plans), or Veteran’s Administration (VA). A person is considered uninsured if not covered by one of these insurance sources. IHS is not included as a source of coverage. Summary Insurance Coverage Indicators (PRVEVyy-INSURCyy) The variables PRVEVyy-UNINSyy summarize health insurance coverage for the person in 2019 for the following types of insurance: private (PRVEVyy); TRICARE/CHAMPVA (TRIEVyy); Medicaid or SCHIP (MCDEVyy); Medicare (MCREVyy); other public coverage (GVAEVyy); other public coverage that is an HMO (GVBEVyy); other public coverage where a premium is paid (GVCEVyy). Each variable was constructed based on the values of the corresponding 12 month-by-month health insurance variables described above. For persons not in scope for the full year, these summary variables are based on the period of eligibility. If the person was not in scope for all 12 months throughout the year, the values are based on the months the person was eligible. A value of 1 indicates that the person was covered for at least one day of at least one month during 2019. A value of 2 indicates that the person was not covered for a given type of insurance for all of 2019. The variable UNINSyy summarizes PRVEVyy-GVAEVyy. Where PRVEVyy-GVAEVyy are all equal to 2, then UNINSyy equals 1, person was uninsured for all of 2019. Otherwise, UNINSyy is set to 2, insured for all or part of 2019. For user convenience this file contains a constructed variable INSCOVyy that summarizes health insurance coverage for the person in 2019, with the following three values: 1 = ANY PRIVATE (Person had any private insurance coverage [including TRICARE/CHAMPVA] any time during 2019) 2 = PUBLIC ONLY (Person had only public insurance coverage [excluding TRICARE/CHAMPVA] during 2019) 3 = UNINSURED (Person was uninsured during all of 2019) INSURCyy summarizes health insurance coverage for the person in 2019 using eight categories of insurance separated by age using the person’s age on December 31st, 2019: 1 = ANY PRIVATE (0-64) (Person is between 0 and 64 years old and is covered by private insurance or TRICARE/CHAMPVA in 2019) 2 = PUBLIC ONLY (0-64) (Person is between 0 and 64 years old and is covered by public insurance only (excluding TRICARE/CHAMPVA) in 2019) 3 = UNINSURED (0-64) (Person is between 0 and 64 years old and is uninsured for all of 2019) 4 = EDITED MEDICARE ONLY (65+) (Person is 65 years old or more and is covered by edited Medicare only in 2019) 5 = EDITED MEDICARE & PRIV (65+) (Person is 65 years old or more and is covered by edited Medicare and private insurance or TRICARE/CHAMPVA in 2019) 6 = EDITED MEDICARE & OTH PUB ONLY (65+) (Person is 65 years old or more and is covered by edited Medicare and public insurance including edited Medicaid/SCHIP or other public coverage but excluding TRICARE/CHAMPVA in 2019) 7 = UNINSURED (65+) (Person is 65 years old or more and is uninsured for all of 2019) 8 = NO MEDICARE BUT ANY PUBLIC/PRIVATE (65+) (Person is 65 years old or more and is not covered by Medicare but is covered by private insurance, Medicaid, TRICARE/CHAMPVA, Veteran’s Administration, or other public coverage in 2019) Please note, beginning in 2012, Category 7 was revised to categorize persons who are 65 years or older and uninsured, and Category 8 was added to include persons 65 years or older who do not have Medicare, but are covered by public or private insurance. Please note that IHS is not included as a source of coverage for either INSCOVyy or INSURCyy. Please note that both INSCOVyy and INSURCyy categorize TRICARE as private coverage. All other health insurance indicators included in this data release categorize TRICARE as public coverage. If an analyst wishes to consider TRICARE public coverage, the variable can easily be reconstructed using the PRVEVyy and TRIEVyy variables. Also note that these categories are mutually exclusive, with preference given to private insurance and TRICARE. Persons with both private insurance/TRICARE and public insurance will be coded as “1” for INSCOVyy and INSURCyy. Users wishing to compare INSCOVyy and INSURCyy across years should note at least two changes beginning in 2018 that may affect the continuity of estimates: 1) increased reports of coverage due to the inclusion of the coverage verification series; and 2) the inclusion of Veteran’s Administration coverage as a public coverage source. FY 2019 PUF Managed Care Variables (TRIST31X- PRVHMOyy) In addition to the month-by-month indicators of coverage, there are round-specific health insurance variables indicating coverage by an HMO or managed care plan. Managed care variables have been constructed from information on health insurance coverage at any time in a reference period and the characteristics of the plan. A separate set of managed care variables has been constructed for private insurance, Medicaid/SCHIP, and Medicare coverage. The purpose of these variables is to provide information on managed care participation during the portion of the three rounds (i.e., reference periods) that fall within the same calendar year. Managed care variables for calendar year 2019 are based on responses to health insurance questions asked during the Round 3, 4, and 5 interviews of Panel 23, and the Round 1, 2, and 3 interviews of Panel 24. Each managed care variable ends in “rr” where the first r denotes the interview round for Panel 23 and the second r denotes the round for Panel 24. The variables ending in “31” and “42” correspond to the first two interviews of each panel in the calendar year. Because Round 3 interviews typically overlap the final months of one year and the beginning months of the next year, the “31” managed care variables for Panel 23 indicate whether or not a person has coverage from a managed care plan in the 2019 calendar year. Similarly, the Panel 23 Round 5 and Panel 24 Round 3 managed care variables indicate whether or not a person has coverage from a managed care plan in the 2019 calendar year, and the variables have been given the suffix “yy” (as opposed to “53”) to emphasize the restricted time frame. Further descriptions of the implications to managed care plan coverage due to the overlapping calendar year in Round 3 are detailed below. Construction of the managed care variables is straightforward, but three caveats are appropriate. First, MEPS estimates of the number of persons in HMOs are higher than figures reported by other sources, particularly those based on HMO industry data. The differences stem from the use of household-reported information, which may include respondent error, to determine HMO coverage in MEPS. Second, the managed care questions are asked about the last plan held by a person through his or her establishment (employer or insurer) even though the person could have had a different plan through the establishment at an earlier point during the interview period. As a result, in instances where a person changed his or her establishment-related insurance, the managed care variables describe the characteristics of the last plan held through the establishment. Third, the “yy” versions of the managed care variables for Panel 24 are developed from Round 3 variables that cover different time frames. The health insurance variable for Round 3 is restricted to the same calendar year as the Round 1 and 2 data. The Round 3 variables describing plan type, on the other hand, overlap the next calendar year. As a consequence, the Round 3 managed care variables may not describe the characteristics of the last plan held in the calendar year if the person changed plans after the first of the year. The variables PRVHMOrr indicate coverage by a private HMO in Panel 24 Rounds 1 - 3, and Panel 23 Rounds 3 - 5. The variables MCRPHOrr indicate coverage by a Medicare managed care plan (or “Medicare Advantage” plan) in Panel 24 Rounds 1 - 3, and Panel 23 Rounds 3 - 5. The variables MCRPDrr indicate coverage by Medicare prescription drug benefit, also known as Part D, in Panel 24 Rounds 1 - 3, and Panel 23 Rounds 3 - 5. The edited version of the Medicare prescription drug coverage variables (MCRPDrrX) include persons who are covered by both edited Medicare and edited Medicaid. The variables MCDHMOrr and MCDMCrr indicate coverage by a Medicaid or SCHIP HMO or managed care plan in Panel 24 Rounds 1 - 3, and Panel 23 Rounds 3 - 5. For Panel 24, the “31” version indicates coverage at any time in Round 1, the “42” version indicates coverage at any time in Round 2, and the “yy” version represents coverage at any time during the 2019 portion of Round 3. For Panel 23, the “31” version indicates coverage at any time during the 2019 portion of Round 3, the “42” version indicates coverage at any time in Round 4, and the “yy” version represents coverage at any time during Round 5 (because Round 5 ends on 12/31/19). In the health insurance section of the questionnaire, respondents reporting private health insurance were asked to identify what types of coverage a person had via a checklist. If the respondent selected prescription drug or dental coverage from this checklist, variables were constructed to indicate prescription drug or dental coverage respectively. It should be noted, however, that in some cases respondents may have failed to identify prescription drug or dental coverage that was included as part of a hospital and physician plan. TRICARE Plan Variables Round-specific variables are provided that indicate which TRICARE plan the person was covered by for each round of 2019. These variables indicate whether the person was covered by TRICARE Standard (TRISTrrX), TRICARE Prime (TRIPRrrX), TRICARE Extra (TRIEXrrX), and TRICARE for Life (TRILIrrX). Beginning in Panel 9 Rounds 4 and 5/Panel 10 Rounds 1 through 3, CHAMPVA was added to the list of TRICARE/CHAMPVA Plans collected in the instrument. Therefore, the variables TRICH42/yyX were created. The “31” version of this variable was constructed starting in 2006. It should be noted that the TRICARE Plan information was elicited from a pick-list, code-all-that-apply question that asked which type of TRICARE plan the person obtained. Beginning Panel 22 Round 3/Panel 23 Round 1, questions related to military health coverage were asked at the person-level. If it was reported that someone in the RU had coverage through military health care, a follow-up question was asked to determine who in the RU was covered; then, the pick-list, code-all-that-apply question described above was asked to determine which type of military coverage the person obtained. VA (Veteran’s Administration) was added to this list beginning Panel 22 Round 3/Panel 23 Round 1. In each round, each TRICARE Plan variable has four possible values: 1 The person was covered by the applicable TRICARE plan [Standard, Prime, Extra, For Life, or CHAMPVA]. 2 The person was covered by TRICARE, but it was not through that particular plan [Standard, Prime, Extra, For Life, or CHAMPVA]. 3 The person was not covered by TRICARE. -1 The person was out-of-scope. Medicare Managed Care Plans, Part B, and Prescription Drug Benefit Persons were assigned Medicare coverage based on their responses to the health insurance questions or through logical editing of the survey data. A small number of persons were edited to have Medicare. For this group, coverage through a managed care plan, Part B, and coverage by prescription drug plan questions were not asked. Since no Medicare establishment-person pair exists for this group, the persons’ Medicare managed care, Part B, and prescription drug benefit statuses are set to -15 (Cannot be Computed). For those persons who reported Medicare coverage based on their responses to the health insurance questions, the Medicare managed care plan, Part B, and prescription drug benefit questions were asked. Medicare managed care plan and prescription drug benefit questions were asked for each round a person indicates Medicare coverage. Medicare Part B questions were asked during the first report of Medicare only. The Medicare Part B indicator for those persons who indicated not having a Medicare card available was introduced for Panel 14 Round 2 and Panel 13 Round 4. For those persons who reported having Medicare coverage in Round 1, but did not have a Medicare card available, Medicare Part B coverage was set to -15 (Cannot be Computed). The Medicare prescription drug benefit variables (MCRPDrr) have been edited (MCRPDrrX) to turn on coverage for all persons who are covered by both edited Medicare and edited Medicaid regardless of the status on their unedited Medicare prescription drug benefit variable. In each round, the variables MCRPHOrr have five possible values: 1 The person was covered by Medicare and covered through a Medicare Managed Care or Medicare Advantage Plan. 2 The person was covered by Medicare but not covered through a Medicare Managed Care or Medicare Advantage Plan. 3 The person was not covered by Medicare. -15 The person was covered by Medicare but whether the coverage is through a Medicare Managed Care or Medicare Advantage Plan cannot be computed. -1 The person was out-of-scope. In each round, the variables MCRPDrr/MCRPDrrX have five possible values: 1 The person was covered by Medicare and covered by prescription drug benefit. 2 The person was covered by Medicare but not covered by prescription drug benefit. 3 The person was not covered by Medicare. -15 The person was covered by Medicare but prescription drug benefit coverage cannot be computed. -1 The person was out-of-scope. In each round, the variables MCRPBrr have five possible values: 1 The person was covered by Medicare and covered by Part B. 2 The person was covered by Medicare but not covered by Part B. 3 The person was not covered by Medicare. -15 The person was covered by Medicare but Part B cannot be computed. -1 The person was out-of-scope. Medicaid/SCHIP Managed Care Plans Persons were assigned Medicaid or SCHIP coverage based on their responses to the health insurance questions or through logical editing of the survey data. The number of persons who were edited to have Medicaid or SCHIP coverage is small. These persons indicated coverage through an Other Government program that was identified as being in a Medicaid HMO or gatekeeper plan that did not require premium payment from the insured party. By definition, respondents were asked about the managed care characteristics of this insurance coverage. Medicaid/SCHIP HMOs If Medicaid/SCHIP or Other Government programs were identified as the source of hospital/physician insurance coverage, the respondent was asked about the characteristics of the plan. The variables MCDHMOrr were set to “Yes” if an affirmative response was provided to the following question: Under {{Medicaid/{STATE NAME FOR MEDICAID}} or {STATE CHIP NAME}/{PROGRAM NAME FROM HX160/HX270}, the program sponsored by a state or local government agency which provides hospital and physician benefits,} {{are/is}/{were/was}} {PERSON 1}, {PERSON 2}, {PERSON 3}, {PERSON 4}, {PERSON N} enrolled in an HMO, that is a Health Maintenance Organization {between {START DATE} and {END DATE}}? [With an HMO, you must generally receive care from HMO physicians. If another doctor is seen, the expense is not covered unless you were referred by the HMO, or there was a medical emergency.] In subsequent rounds, for persons who had been previously identified as covered by Medicaid, the respondent was asked whether the name of the person’s insurance plan had changed since the previous interview. An affirmative response triggered the previous set of questions about managed care (name on list of Medicaid HMOs or signed up with an HMO). In each round, the variables MCDHMOrr have five possible values: 1 The person was covered by a Medicaid/SCHIP HMO. 2 The person was covered by Medicaid/SCHIP but the plan was not an HMO. 3 The person was not covered by Medicaid/SCHIP. -15 The person was covered by Medicaid/SCHIP but the plan type cannot be computed. -1 The person was out-of-scope. Medicaid/SCHIP Gatekeeper Plans If a person did not belong to a Medicaid/SCHIP HMO, a third question was used to determine whether the person was in a gatekeeper plan. The variables MCDMCrr were set to “Yes” if the respondent provided an affirmative response to the following question: {Does/Between {START DATE} and {END DATE}, did} {{Medicaid/{STATE NAME FOR MEDICAID}} or {STATE CHIP NAME}/{PROGRAM NAME FROM HX160/HX270}, the program sponsored by a state or localgovernment agency which provides hospital and physician benefits,} require {PERSON 1}, {PERSON 2}, {PERSON 3}, {PERSON 4}, {PERSON N} to sign up with a certain primary care doctor, group of doctors, or with a certain clinic which they must go to for all of their routine care? Probe: Do not include emergency care or care from a specialist they were referred to. In each round, the variables MCDMCrr have five possible values: 1 The person was covered by a Medicaid/SCHIP gatekeeper plan. 2 The person was covered by Medicaid/SCHIP, but it was not a gatekeeper plan. 3 The person was not covered by Medicaid/SCHIP. -15 The person was covered by Medicaid/SCHIP but the plan type cannot be computed. -1 The person was out-of-scope. Private Managed Care Plans Persons with private insurance were identified from their responses to questions in the health insurance section of the MEPS questionnaire. In some cases, persons were assigned private insurance as a result of comments collected during the interview, but data editing was minimal. As a consequence, most persons with private insurance were asked about the characteristics of their plan, and their responses were used to identify HMO and gatekeeper plans. Private HMOs Persons with private insurance were classified as being covered by an HMO if they met any of the three following conditions:
In subsequent rounds, policyholders were asked whether the name of their insurance plan had changed since the previous interview. An affirmative response triggered the detailed question about managed care (i.e., was the insurer an HMO). Some insured persons have more than one private plan. In these cases, if the policyholder identified any plan as an HMO, the variables PRVHMOrr were set to “Yes.” If a person had multiple plans and one or more were identified as not being an HMO and the other(s) had missing plan type information, the person-level variable was set to missing. Additionally, if a person had multiple plans and none were identified as an HMO, the person-level variable was set to “No.” In each round, the variables PRVHMOrr have five possible values: 1 The person was covered by a private HMO. 2 The person was covered by private insurance, but it was not an HMO. 3 The person was not covered by private insurance. -15 The person was covered by private insurance, but the plan type cannot be computed. -1 The person was out-of-scope. Flexible Spending Accounts (FSAGT31-PFSAMT31) Respondents in Round 1 or Round 3 were asked if any RU members set aside pre-tax dollars of their own money to pay for out-of-pocket health care expenses. If an RU has a Flexible Spending Account (FSA), then FSAGT31 was set to 1 (Yes), and two follow-up questions were asked – HASFSA31 and PFSAMT31. HASFSA31 was set for each RU member to indicate which RU member has an FSA. Previously, FSAAMT31 was asked at the RU level and collected the total amount contributed to all FSAs belonging to an RU. Beginning Panel 22 Round 3/Panel 23 Round 1, the question asking the amount contributed to the FSA is asked at the person-level, and the variable FSAAMT31 is no longer constructed. Instead, the constructed variable PFSAMT31 indicates the total amount the individual RU member contributed to his or her FSA. If no RU member has an FSA, then both HASFSA31 and PFSAMT31 are set to -1 (Inapplicable). Unedited Health Insurance Variables (PREVCOVR-MORECOVR) Duration of Uninsurance If a person was identified as being without insurance as of January 1st in the MEPS Round 1 interview, two follow-up questions were asked to determine the duration of uninsurance prior to the start of the MEPS survey. Persons who were insured as of January 1st, and persons with a date of birth on or after December 31, 2019 or whose age category was less than 1 year old were skipped past this loop of questions. These questions are asked in Round 1 only. PREVCOVR indicates if the person was covered by insurance in the two years prior to the MEPS Round 1 interview. For persons who reported only non-comprehensive coverage as of January 1st, a question was asked to determine if they had been covered by more comprehensive coverage that paid for medical and doctors’ bills in the previous two years (MORECOVR). Beginning Panel 23 Round 1, the follow-up questions to PREVCOVR and MORECOVR that collected information on the most recent month and year of coverage (COVRMM, COVRYY, INSENDMM, INSENDYY) and type of coverage (Employer-sponsored (WASESTB), Medicare (WASMCARE), Medicaid/SCHIP (WASMCAID), TRICARE/CHAMPVA (WASCHAMP), VA/Military Care (WASVA), Other public (WASOTGOV, WASAFDC, WASSSI, WASSTAT1-4, WASOTHER), private coverage purchased through a group, association or insurance company (WASPRIV)) are no longer asked. Therefore, these variables will no longer be constructed. Note that these variables are unedited and have been taken directly as they were recorded from the raw data. There may be inconsistencies with the health insurance variables released on public use files that indicate that an individual is uninsured in January. Out-of-scope persons in both panels have been set to “Inapplicable” (-1) for PREVCOVR and MORECOVR. All other persons have PREVCOVR and MORECOVR copied directly from the value of the unedited source variable. Persons whose January 1st insurance coverage status could not be determined due to their reference period beginning after January 1st were also asked the follow-up questions described above. In these cases, persons who reported comprehensive coverage were asked if they were ever without insurance. Those who were uninsured were asked to determine the duration of uninsurance prior to the start of their reference period. Those who reported only non-comprehensive coverage were asked if they had been covered by comprehensive coverage that paid for medical and doctors’ bills in the previous two years. Coverage is determined by health insurance status during the whole reference period or the month of January and ignores that these persons were not in the household on January 1st. Health Insurance Coverage Variables – At Any Time/At Interview Date/At 12-31 Variables (TRICR31X-INSATyyX) Constructed and edited variables are provided that indicate health insurance coverage at any time in a given round, as well as at the MEPS interview dates and on December 31, 2019. Note that for persons who left the RU before the MEPS interview date or before December 31st, the variables measuring coverage at the interview date or on December 31st represent coverage at the date the person left the RU. In addition, since Round 5 only covers the time period from the Round 4 interview date up to December 31st, values for the December 31st variables are equivalent to those for Round 5 variables for Panel 23 members. Variables indicating coverage for Panel 23 members for any time in the round that end in “31” indicate coverage for the portion of Round 3 that occurred in calendar year 2019, unless noted otherwise (see “Dental and Prescription Drug Private Insurance” section). Variables indicating coverage for Panel 24 members ending in “53” indicate coverage at any time in Round 3, including the portion of the round that occurred in calendar year 2020. For Round 3 coverage for Panel 24 members that occurred in calendar year 2019, users should use variables ending in “yy”. The health insurance variables are constructed for the sources of health insurance coverage collected during the MEPS interviews (Panel 23 Rounds 3 through 5, and Panel 24 Rounds 1 through 3). Note that the Medicare variables on this file as well as the private insurance variables that indicate the particular source of private coverage (rather than any private coverage) only measure coverage at the interview date and on December 31st. Users should also note that the same general editing rules were followed for the month-by-month health insurance variables released on this public use file (see Section 2.5.10 “Monthly Health Insurance Indicators” for details). Editing programs checking for consistencies between these sets of variables were developed in order to provide as much consistency as possible between the round-specific indicators and the month-by-month indicators of insurance. Public sources include Medicare, TRICARE, Veteran’s Administration (VA), Medicaid/SCHIP, and other public hospital/physician coverage. IHS was not considered a public coverage source. Medicare Medicare coverage variables (MCARErr) and the edited versions of these variables (MCARErrX) were constructed similarly to the month-by-month Medicare variables. Since Medicare coverage is logically edited to continue for a person once it has been reported in MEPS, the Medicare coverage variables can be considered as either “coverage at any time in the round” or “coverage at the interview date” variables, with the same caveats as noted above regarding persons who left the RU prior to the interview date or regarding coverage on December 31st variables and restrictions on Round 3 coverage to reflect coverage in 2019. Medicaid/SCHIP and Other Public Hospital/Physician Coverage Medicaid/SCHIP variables (MCAIDrr) and the edited versions of these variables (MCAIDrrX and MCDATrrX) were constructed similarly to the month-by-month Medicaid/SCHIP variables. Other public coverage variables indicating coverage through other public hospital/physician insurance (GOVTArr and GOVAATrr); other public coverage that is an HMO (GOVTBrr and GOVBATrr); and other public coverage that pays a premium (GOVTCrr and GOVCATrr) were constructed similarly to the month-by-month Other Public variables. Any Public Insurance Any public insurance variables (PUBrrX and PUBATrrX) were constructed similarly to the month-by-month any public insurance variables. Beginning FY 2017, the state-specific constructed variables on previous public use files (STAPRrr and STPRATrr) will no longer be constructed. Beginning FY 2018, the variables indicating coverage through Veteran’s Administration (VAPROGrr and VAPRATrr) were included in this file and constructed similarly to the Veteran’s Administration month-by-month variables. Private Insurance Variables identifying private insurance in general
(PRIVrr and PRIVATrr) and specific private insurance sources (such as
employer/union group insurance [PRIEUrr]; other group coverage [PRIOGrr];
coverage through an unknown private category [PRIDKrr]; coverage from a
policyholder living outside the RU that is employer based coverage [PRIEUOrr];
coverage from a policyholder living outside the RU that is not employer-based
coverage [PRINEOrr];and coverage through an exchange [PRSTXrr]) were constructed
similarly to the month-by-month variables in Section 2.5.10. Variables
indicating any private insurance coverage are available for the following time
periods: at any time in a given round, at the interview date, and on December 31st.
The variables for the specific sources of private coverage are only available
for coverage on the interview dates and on December 31st. Any Insurance in Period Any insurance variables (INSrrX and INSATrrX) were constructed similarly to the month-by-month any insurance program variables. Dental and Prescription Drug Private Insurance Variables (DENTIN31-PMDINSyy) Dental Private Insurance Variables Round-specific variables (DENTINrr) are provided that indicate the person was covered by a private health insurance plan that included at least some dental coverage for each round of 2019. It should be noted that the information was elicited from a pick-list, code-all-that-apply, question that asked what type of health insurance a person obtained through an establishment. The list included: hospital and physician benefits including coverage through an HMO, Medigap coverage, vision coverage, dental, and prescription drugs. It is possible that some dental coverage provided by hospital and physician plans was not independently enumerated in this question. Users should also note that persons with missing information on dental benefits for all reported private plans and those who reported that they did not have dental coverage for one or more plans but had missing information on other plans are coded as not having private dental coverage. Persons with reported dental coverage from at least one reported private plan were coded as having private dental coverage. DENTIN53 reflects coverage for all of Panel 24 Round 3 where the end reference year could extend into 2020. DENTIN31 for Panel 23 Round 3 reflects coverage in 2018 and 2019 since the Round 3 reference period spans both years. A second version of these dental coverage indicators was built to reflect only current year coverage (DNTINSrr). Prescription Drug Private Insurance Variables Round-specific variables (PMEDINrr) are provided that indicate the person was covered by a private health insurance plan that included at least some prescription drug insurance coverage for each round of 2019. It should be noted that the information was elicited from a pick-list, code-all-that-apply, question that asked what type of health insurance a person obtained through an establishment. The list included: hospital and physician benefits including coverage through an HMO, Medigap coverage, vision coverage, dental, and prescription drugs. It is possible some prescription drug coverage provided by hospital and physician plans was not independently enumerated in this question. Persons with reported prescription drug coverage from at least one reported private plan were coded as having private prescription drug coverage. Users should note that persons with missing information on prescription drug benefits for all reported private plans and those who reported that they did not have prescription drug coverage for one or more plans but had missing information on other plans are coded as not having private prescription drug coverage. PMEDIN53 reflects coverage for all of Panel 24 Round 3 where the end reference year could extend into 2020. PMEDIN31 for Panel 23 Round 3 reflects coverage in 2018 and 2019 since the Round 3 reference period spans both years. A second version of these prescription drug coverage indicators was built to reflect only current year coverage (PMDINSrr). Medical Debt Variables (PROBPY42 – PYUNBL42) Questions relating to medical debt were asked in the health insurance section. Respondents in Round 2 or Round 4 were asked questions HX770 (“In the past 12 months did anyone in the family have problems paying or were unable to pay any medical bills?”), HX780 (“Does anyone in your family currently have any medical bills that are being paid off over time?”), and HX790 (“Does anyone in your family currently have any medical bills that you are unable to pay at all?”). The corresponding constructed variables PROBPY42, CRFMPY42, and PYUNBL42 are included in this file. PROBPY42 was set to 1 (Yes) if the respondent indicated that someone in their family had problems paying or were unable to pay any medical bills. Additional questions ascertained if anyone in the family currently had medical bills that were being paid off over time (CRFMPY42), and if anyone in the family currently had any medical bills that were unable to be paid at all (PYUNBL42). If the respondent indicated that someone in their family currently has any medical bills that are being paid off over time, then CRFMPY42 was set to 1 (Yes). Note that if the respondent indicates that no one in their family had problems paying medical bills, then PYUNBL42 is set to -1 (Inapplicable). Prescription Drug Usual Third Party Payer Variables (PMEDUP31-PMEDPY53) Round-specific variables are provided that indicate whether the sample member had a usual third party payer for prescription medications (PMEDUPrr), and if so, what type of payer (PMEDPYrr). These questions were asked only of sample members who reportedly had at least one prescription medication purchase in the round. In each interview, if the sample member reportedly had a third party payer, then the respondent was asked the name of the sample member’s usual third party payer. These responses were coded into the following source of payment categories in PMEDPYrr: Private Insurance, Medicare, Medicaid, VA/CHAMPVA, TRICARE, State/Local Government, and Other. Users should note that these questions were asked in the Prescribed Medicines (PM) section of the questionnaire, and that no attempt was made to reconcile the responses with information collected in the health insurance section of the questionnaire. 2.5.11 Utilization, Expenditures, and Sources of Payment Variables (TOTTCH19-RXOSR19)The MEPS Household Component (HC) collects data in each round on use and expenditures for office- and hospital-based care, home health care, dental services, vision aids, and prescribed medicines. Data were collected for each sample person at the event level (e.g., doctor visit, hospital stay) and summed across Rounds 3 - 5 for Panel 23 (excluding 2018 events covered in Round 3) and across Rounds 1 - 3 for Panel 24 (excluding 2020 events covered in Round 3) to produce the annual utilization and expenditure data for 2019. In addition, the MEPS Medical Provider Component (MPC) is a follow-back survey that collected data from a sample of medical providers and pharmacies that were used by sample persons in 2019. Expenditure data collected in the MPC are generally regarded as more accurate than information collected in the HC and were used to improve the overall quality of MEPS expenditure data in this file (see below for description of methodology used to develop expenditure data). This file contains utilization and expenditure variables for several categories of health care services. In general, there is one utilization variable (based on HC responses only), 11 expenditure variables (derived from both HC and MPC responses), and one charge variable for each category of health care service. The utilization variable is typically a count of the number of medical events reported for the category. The 11 expenditure variables consist of an aggregate total payments variable and 10 main component source of payment category variables (see below for description of source of payment categories). Expenditure variables for all categories of health care combined are also provided. These variables generally represent a full year of use and expenditures. However, for persons who were not inscope for the entire year, these variables reflect only the period of eligibility. The table in Appendix 3 provides an overview of the utilization and expenditure variables included in this file. For each health service category, the table lists the corresponding utilization variable(s) and provides a general key to the expenditure variable names (11 per service category). The first three characters of the expenditure variable names reflect the service category (except only two characters for prescription medicines) while the subsequent three characters (*** in table) reflect the naming convention for the source of payment categories described below (except only two characters for Veterans Administration). The last two positions of all utilization and expenditure variable names reflect the survey year (i.e., 19). More details are provided on the utilization and expenditure variables in sections 2.5.11 below. Expenditures Definition Expenditures on this file refer to what is paid for health care services. More specifically, expenditures in MEPS are defined as the sum of direct payments for care provided during the year, including out-of-pocket payments and payments by private insurance, Medicaid, Medicare, and other sources. Payments for over-the-counter drugs are not collected in MEPS. Indirect payments not related to specific medical events, such as Medicaid Disproportionate Share and Medicare Direct Medical Education subsidies, are also not included. The definition of expenditures used in MEPS is somewhat different from the 1987 NMES and 1977 NMCES surveys where charges rather than sum of payments were used to measure expenditures. This change was adopted because charges became a less appropriate proxy for medical expenditures during the 1990s due to the increasingly common practice of discounting charges. Another change from the two prior surveys is that charges associated with uncollected liability, bad debt, and charitable care (unless provided by a public clinic or hospital) are not counted as expenditures because there are no payments associated with those classifications. While the concept of expenditures in MEPS has been operationalized as payments for health care services, variables reflecting charges for services received are also provided on the file (see below). Analysts should use caution when working with the charge variables because they do not typically represent actual dollars exchanged for services or the resource costs of those services. Data Sources on Expenditures The expenditure data included on this file were derived from the MEPS Household and Medical Provider Components. Only HC data were collected for non-physician visits, dental and vision services, other medical equipment and services, and home health care not provided by an agency. Data on expenditures for care provided by home health agencies were only collected in the MPC. In addition to HC data, MPC data were collected for a sample of office-based visits to physicians (or medical providers supervised by physicians), hospital-based events (e.g., inpatient stays, emergency room visits, and outpatient department visits), and prescribed medicines. For these types of events, MPC data were used if complete; otherwise, HC data were used if complete. Missing data for events where HC data were not complete and MPC data were not collected or complete were derived through an imputation process (see below). A series of logical edits were applied to both the HC and MPC data to correct for several problems including, but not limited to, outliers, copayments or charges reported as total payments, and reimbursed amounts that were reported as out-of-pocket payments. In addition, edits were implemented to correct for misclassifications between Medicare and Medicaid and between Medicare HMOs and private HMOs as payment sources. Data were not edited to ensure complete consistency between the health insurance and source of payment variables on the file. Imputation for Missing Expenditures and Data Adjustments Expenditure data were imputed to 1) replace missing data, 2) provide estimates for care delivered under capitated reimbursement arrangements, and 3) to adjust household-reported insurance payments because respondents were often unaware that their insurer paid a discounted amount to the provider. This section contains a general description of the approaches used for these three situations. A more detailed description of the editing and imputation procedures is provided in the documentation for the MEPS event-level files. The predictive mean matching (PMM) imputation method was used to impute missing expenditures. This procedure uses regression models (based on events with completely reported expenditure data) to predict total expenses for each event. Then, for each event with missing payment information, a donor event with the closest predicted payment with the same pattern of expected payment sources as the event with missing payment was used to impute the missing payment value. The general approach that was used to impute missing expenditure data on prescribed medicines is described in section 2.5.11 below. Payments under capitated arrangement and public clinics including VA healthcare are not tied to individual episodes of medical care. Therefore, expenditures for medical care covered under capitated arrangement or received in such public settings were imputed. Using a weighted sequential hot-deck procedure, events covered under capitated arrangements were imputed using donor events covered by a managed care organization but paid on a fee-for-service basis. For other events, including public clinic and VA, expenditures were imputed using the PMM method where selected predictor variables were used to predict expenditures and match recipient and donor events. An adjustment was also applied to some HC-reported expenditure data because an evaluation of matched HC/MPC data showed that respondents who reported that charges and payments were equal were often unaware that insurance payments for the care had been based on a discounted charge. To compensate for this systematic reporting error, a weighted sequential hot-deck imputation procedure was implemented to determine an adjustment factor for HC-reported insurance payments when charges and payments were reported to be equal. As for the other imputations, selected predictor variables were used to form groups of donor and recipient events for the imputation process. Methodology for Flat Fee Expenditures Most of the expenditures for medical care reported by MEPS participants are associated with single medical events. However, in some situations one charge covers multiple contacts between a medical provider and patient (e.g., obstetrician services, orthodontia). In these situations (generally called flat or global fees), total payments for the flat or global fee were included if the initial service was provided in 2019. For example, all payments for an orthodontist’s fee that covered multiple visits over three years were included if the initial visit occurred in 2019. However, if a visit in 2019 to an orthodontist was part of a flat fee in which the initial visit occurred in 2018, then none of the payments for the flat fee were included. The approach used to count expenditures for flat fees may create what appear to be inconsistencies between utilization and expenditure variables. For example, if several visits under a flat fee arrangement occurred in 2019 but the first visit occurred in 2018, then none of the expenditures were included, resulting in low expenditures relative to utilization for that person. Conversely, the flat fee methodology may result in high expenditures for some persons relative to their utilization. For example, all of the expenditures for an expensive flat fee were included even if only the first visit covered by the fee had occurred in 2019. On average, the methodology used for flat fees should result in a balance between overestimation and underestimation of expenditures in a particular year. Zero Expenditures There are some medical events reported by respondents where the payments were zero. This could occur for several reasons including (1) free care was provided, (2) bad debt was incurred, (3) care was covered under a flat fee arrangement and it was not the initial event of the bundle (see prior section on Methodology for Flat Fee Expenditures), or (4) follow-up visits were provided without a separate charge (e.g., after a surgical procedure). In summary, these types of events have no impact on totals for the person-level expenditure variables contained in this file. Source of Payment Categories In addition to total expenditures, variables are provided that itemize expenditures according to the major source of payment categories. These categories are:
Prior to 2019, for cases where reported insurance coverage and sources of payment appear inconsistent, the positive amount from a source inconsistent with reported insurance coverage was moved to one or both of the source categories Other Private and Other Public. Beginning in 2019, this step is removed and the apparent inconsistency between the payment sources and insurance coverage is allowed to remain - the amounts are not moved to Other Private and Other Public categories any more. The two source of payment categories, Other Private and Other Public, are no longer available. Some inconsistencies arise from either misreporting of health insurance coverage or sources of payment. However, apparent inconsistencies may also have logical explanations. For example, private insurance coverage in MEPS is defined as having a major medical plan covering hospital and physician services. If a MEPS sample person did not have such coverage but had a single service type insurance plan (e.g., dental insurance) that paid for a particular episode of care, those payments may be classified as “other private.” Some of the “other public” payments may stem from confusion between Medicaid and other state and local programs or may be for persons who were not enrolled in Medicaid, but were presumed eligible by a provider who ultimately received payments from the program. The naming conventions used for the source of payment expenditure variables are shown in parentheses in the list of categories above and in the key to the attached table in Appendix 3. In addition, total expenditure variables (EXP in key) based on the sum of the 10 source of payment variables above are provided. Charge Variables In addition to the expenditure variables described above, a variable reflecting total charges is provided for each type of service category (except prescribed medicines). This variable represents the sum of all fully established charges for care received and usually does not reflect actual payments made for services, which can be substantially lower due to factors such as negotiated discounts, bad debt, and free care (see above). The weighted sequential hot-deck procedure was used to impute the missing total charges. The naming convention used for the charge variables (TCH) is also included in the key to the attached table in Appendix 3. The total charge variable across services (TOTTCH19) excludes prescribed medicines. Utilization and Expenditure Variables by Type of Medical Service The following sections summarize definitional, conceptual, and analytic considerations when using the utilization and expenditure variables in this file. Separate discussions are provided for each MEPS medical service category. There is also a discussion in the section dealing with analyses of trends using MEPS data (section 3.11). Medical Provider Visits (i.e., Office-Based Visits) Medical provider visits consist of encounters that took place primarily in office-based settings and clinics. Care provided in other settings such as a hospital, nursing home, or a person’s home are not included in this category. The total number of office-based visits reported for 2019 (OBTOTV19) as well as the number of such visits to physicians (OBDRV19) are contained in this file. Expenditure variables associated with all medical provider visits and physician visits can be identified using the attached table in Appendix 3. Hospital Events Separate utilization variables for hospital care are provided for each type of setting (outpatient department, emergency room, and inpatient stays) along with three expense variables per setting: one for basic hospital facility expenses, one for payments to physicians who billed separately for services provided at the hospital (referred to as “separately billing doctor” or SBD expenses) and one that aggregates the facility and SBD expenses (aggregated variable not included in files prior to 2007). Hospital facility expenses include all expenses for direct hospital care, including room and board, diagnostic and laboratory work, x-rays, and similar charges, as well as any physician services included in the hospital charge. SBD expenses typically cover services provided to patients in hospital settings by providers like radiologists, anesthesiologists, and pathologists, whose charges are often not included in hospital bills. Hospital Outpatient Visits Variables for the total number of reported visits to hospital outpatient departments in 2019 (OPTOTV19) as well as the number of outpatient department visits to physicians (OPDRV19) are contained in this file. Expenditure variables (both facility and SBD) associated with all medical provider visits and physician visits can be identified using the attached table in Appendix 3. Hospital Emergency Room Visits The variable ERTOT19 represents a count of all emergency room visits reported for the survey year. Expenditure variables associated with ERTOT19 are identified in the attached table in Appendix 3. It should be noted that for emergency room visits that immediately preceded an inpatient stay, the facility expenditures associated with the emergency room visits are included in the inpatient expenditures. To avoid double counting, these emergency room visits resulted in $0 facility expenditures (but there still may be associated SBD expenses). However, these $0 emergency room visits are still counted as separate visits in the utilization variable ERTOT19. Hospital Inpatient Stays Two measures of total inpatient utilization are provided on the file:
Expenditure variables associated with hospital inpatient stays are identified in the attached table in Appendix 3. As described in the previous section, payments associated with emergency room visits that immediately preceded an inpatient stay are included with the inpatient expenditures. In addition, payments associated with healthy newborns are included with expenditures for the mother. Specifically, data used to construct the inpatient utilization and expenditure variables for newborns were edited to exclude stays where the newborn left the hospital on the same day as the mother. This edit was applied because discharges for infants without complications after birth were not consistently reported in the survey, and charges for newborns without complications are typically included in the mother’s hospital bill. However, if the newborn was discharged at a later date than the mother was discharged, then the discharge was considered a separate stay for the newborn when constructing the utilization and expenditure variables. Dental Care Visits The total number of dental care visits variable (DVTOT19) includes those to any person(s) for dental care including general dentists, dental hygienists, dental technicians, dental surgeons, orthodontists, endodontists, and periodontists. Home Health Care In contrast to other types of medical events where data were collected on a per visit basis, information on home health care utilization is collected in MEPS on a per month basis. Variables are provided that indicate the total number of days in 2019 where home health care was received from the following: from any type of paid or unpaid caregiver (HHTOTD19), from agencies, hospitals, or nursing homes (HHAGD19), from self-employed persons (HHINDD19), and from unpaid informal caregivers not living with the sample person (HHINFD19). The number of provider days represents the sum across months of the number of days on which home health care was received, with days summed across all providers seen. For example, if a person received care in one month from one provider on two different days, then the number of provider days would equal two. The number of provider days would also equal two if a person received care from two different providers on the same day. However, if a person received care from one provider two times on the same day, then the provider days would equal one. These variables were assigned missing values if the number of provider days could not be computed for any month in which the specific type of home health care was received. Separate expenditure variables are provided for agency-sponsored home health care (includes care provided by home health agencies, hospitals, and nursing homes) and care provided by self-employed persons. The attached table in Appendix 3 identifies the home health care utilization and expenditure variables contained in the file. Other Medical Equipment and Services The new CAPI instrument collects round-specific Other Medical (OM) expenditures for all OM types (glasses/contact lenses, ambulance, disposable supplies, and long-term equipment). Please note for disposable supplies, the total charge and out-of-pocket expenditures are collected in a range format. The ranges were replaced with mean dollar amounts of respective expenditures reported in each range in prior years. Prescribed Medicines There is one total utilization variable (RXTOT19) and 11 expenditure variables included on the 2019 full-year file relating to prescribed medicines. These 11 expenditure variables include an annual total expenditure variable (RXEXP19) and 10 corresponding annual source of payment variables (RXSLF19, RXMCR19, RXMCD19, RXPRV19, RXVA19, RXTRI19, RXOFD19, RXSTL19, RXWCP19, and RXOSR19). The total utilization variable is a count of all fills and refills of prescribed medications obtained during 2019. The total expenditure variable sums all amounts paid out-of-pocket and by third party payers for each prescription obtained in 2019. No variables reflecting charges for prescription medicines are included because a large proportion of respondents to the MEPS pharmacy component survey did not provide charge data (see below). Prescribed Medicines Data Collected Data regarding prescription drugs were obtained through the household questionnaire and a pharmacy component survey. During each round of the MEPS HC, all respondents were asked to supply the name of any prescribed medication they or their family members purchased or otherwise obtained during that round. For each medication and in each round, the following information was collected: the name(s) of any health conditions the medication was prescribed for; the number of times the prescription drug was obtained or purchased; the year and month which the person first used the medication; and a list of the names, addresses, and types of pharmacies that filled the household’s prescriptions. Payment information was collected in the pharmacy component survey. Pharmacy providers identified by the household were contacted by telephone in the pharmacy component if permission to release their pharmacy records was obtained in writing from the person with the prescription. The signed permission forms were provided to the various establishments prior to making any requests for information. Each establishment was informed of all persons participating in the survey that had prescriptions filled there in 2019 and a computerized printout containing information about these prescriptions was sought. For each medication listed, the following information was requested: national drug code (NDC), medication name, strength of medicine (amount and unit), quantity (package size and amount dispensed), and payments by source. Information about diabetic supplies and equipment, such as syringes and test strips, were reported in the prescription drug section of MEPS and use of and expenditures for these items are included in the person-level prescribed medicine variables. Prescribed Medicines Data Editing and Imputation The general approach to preparing the household prescription data for this file was to utilize the pharmacy component prescription data to assign expenditure values to the household drug mentions. For those with Pharmacy Component data, a matching program was adopted to link pharmacy component drugs and the corresponding drug information to household drug mentions. To improve the quality of these matches, all drugs on the household and pharmacy files were coded based on the medication names provided by the household and pharmacy, and when available, the national drug code (NDC) provided in the pharmacy survey. Considerable editing was done prior to the matching to correct data inconsistencies in both data sets, fill in missing data, and correct outliers on the pharmacy file. Drug price per unit outliers were analyzed on the pharmacy file by first identifying the average wholesale unit price (AWUP) of the drug by linkage through the NDC to a proprietary database. In general, prescription drug unit prices were deemed to be outliers by comparing unit prices reported in the pharmacy database to the AWUP and were edited, as necessary. Beginning with the 2007 data, the rules used to identify outlier prices for prescription medications in the PC changed. New outlier thresholds were established based on the distribution of the ratio of retail unit prices relative to the AWUP in the 2006 MarketScan Outpatient Pharmaceutical Claims database. Starting with the 2008 Prescribed Medicine file, improvements in the data editing changed the distribution of payments by source: (1) more spending on Medicare beneficiaries is by private insurance, rather than Medicare, and (2) there are less out-of-pocket payments and more Medicaid payments among Medicaid enrollees. Beginning with the 2009 data, another change affected the data for Medicare beneficiaries with both Part D and Medicaid coverage: reported Medicaid and other state and local program payments were no longer edited to be Medicare payments. Beginning with the 2017 data, changes in the price imputation procedures for specialty drugs with missing payment information resulted in higher total prescribed medicines expenditures. For Round 3, which spans two years, drug mentions in that round were allocated between the years based on the following information: the number of times the respondent said the drug was purchased in the respective year, the year the person started taking the drug, the length of the person’s round, the dates of the person’s round, and the number of fills of that drug for that person in the round. Collapsed Source of Payment Variables Two additional source of payment variables are included for each health care service category as a convenience to data users since they are common analytic groupings of the payment sources. The first (***PTR19 series) is the sum of the private and Tricare payer categories (i.e., ***PTR19=***PRV19+***TRI19). The second (***OTH19 series) is the sum of the least common source of payment categories including: 1) other federal (***OFD19), 2) state and local (***STL19), and 3) other sources (***OSR19). Since the ***PTR19 and ***OTH19 variable series represent combined totals of existing individual source of payment variables, analysts should exercise caution to avoid inappropriate double counting of expenditures when working with these variables. 2.5.12 Changes in Variable ListFollowing is a list of changes to the variable list for the 2019 full-year consolidated data file. Added VAFIBR31 Added (included in alternating years only, will not be included in 2020):
Deleted
Deleted (included in alternating years only, will be included in 2020):
Variables Renamed The round number in the VSAQ variable names was updated from 53 to 31. See Section 2.5.6 for more information. Label Changes IPFEXP19 From TOT HOSP IP FACILITY EXP-INC 0 NITES 19 2.6 Linking to Other Files2.6.1 Event and Condition FilesRecords on this file can be linked to 2019 MEPS HC public use event and conditions files by the sample person identifier (DUPERSID). The Panel 23 cases on this file (PANEL=23) can also be linked back to the 2018 MEPS HC public use event and condition files. 2.6.2 National Health Interview SurveyThe set of households selected for MEPS is a subsample of those participating in the National Health Interview Survey (NHIS), thus, each MEPS panel can also be linked back to the previous year’s NHIS public use data files. For information on obtaining MEPS/NHIS link files please see the AHRQ website. 2.6.3 Longitudinal AnalysisPanel-specific longitudinal files are available for downloading in the data section of the MEPS website. For each panel, the longitudinal file comprises MEPS survey data obtained in Rounds 1 through 5 of the panel and can be used to analyze changes over a two-year period. Variables in the file pertaining to survey administration, demographics, employment, health status, disability days, quality of care, patient satisfaction, health insurance, and medical care use and expenditures were obtained from the MEPS full-year Consolidated files from the two years covered by that panel. For more details or to download the data files, please see Longitudinal Weight Files at the AHRQ website. 3.0 Survey Sample Information3.1 Background on Sample Design and Response RatesThe MEPS is designed to produce estimates at the national and regional level over time for the civilian, noninstitutionalized population of the United States and some subpopulations of interest. The data in this public use file pertain to calendar year 2019. The data were collected in Rounds 1, 2, and 3 for MEPS Panel 24 and Rounds 3, 4, and 5 for MEPS Panel 23. (Note that Round 3 for a MEPS panel is designed to overlap two calendar years, as illustrated below.)
Variables convey the same information for this full year consolidated file that has been provided for the full year consolidated files associated with years 1996 - 2018 of MEPS. The only utilization data that appear on this file are those associated with health care events reported by MEPS respondents and occurring in calendar year 2019. These data were obtained from both MEPS panels for those rounds (or portions of rounds) associated with calendar year 2019. A sample design feature shared by both Panel 23 and Panel 24 involved the partitioning of the sample domain “Other” (serving as the catchall stratum and consisting mainly of households with “White” members) into two sample domains. This was done for the first time in Panel 16. The two domains distinguished between those households characterized as “complete” respondents to the NHIS and those characterized as “partial completes.” NHIS “partial completes” typically have a lower response rate to MEPS and for both MEPS panels the “partial” domain was sampled at a lower rate than the “complete” domain. This approach has served to reduce survey costs, since the “partials” tend to have higher costs in gaining survey participation, but has also increased sample variability due to the resulting increased variability in sampling rates. For detailed information on the MEPS sample design, see Chowdhury et al (2019). 3.1.1 MEPS-Linked to the National Health Interview Survey (NHIS)Each responding household found in this 2019 MEPS dataset is associated with one of two separate and overlapping MEPS panels, MEPS Panel 23 and MEPS Panel 24. These panels consist of subsamples of households participating in the 2017 and 2018 NHIS, respectively. The Full Year 2018 PUF was the first one where both MEPS panels reflect the new NHIS sample design first implemented in 2016. Whenever there is a change in sample or study design, it is good survey practice to assess whether such a change could affect the sample estimates. For example, increased coverage of the target populations with an updated sample design based on data from the latest Census can improve the accuracy of the sample estimates. MEPS estimates have been and will continue to be evaluated to determine if an important change in the survey estimates might be associated with a change in design. Background on the two NHIS sample designs of interest is provided next. Background on the NHIS Sample Redesign Implemented in 2016 Beginning in 2016, NCHS implemented another new sample design for the NHIS, which differed substantially from the prior design. Each of the 50 states as well as the District of Columbia served as explicit strata for sample selection purposes with the intent of providing the capability of state-level NHIS estimates obtained through pooling across years if the sample size for a single year would result in unreliable estimates. In contrast to the previous design, households in areas with relatively high concentrations of minorities are not oversampled. PSUs are still formed at the county level. However, within sampled PSUs, the clusters of addresses that have been sampled for each year of the NHIS are not in the form of segments (consisting of one or more census blocks) as was done for the previous NHIS designs. For the 2016 NHIS, each such cluster consisted of roughly 25 subclusters selected using random systematic sampling across the full geography of the PSU. Each subcluster is made up of, generally, four nearby addresses, or roughly 100 addresses in all. The number of subclusters per cluster can vary from year to year. Another major change is that the list of DUs (addresses) was obtained from the Computerized Delivery Sequence File (CDSF) of the U.S. Postal Service, which is a different approach than the standard listing process for area probability samples used in the pre-2016 designs. While addresses in the CDSF provide very high coverage of most areas of the country, coverage in rural areas can be somewhat lower. For rural areas where this was a concern, address lists were created through the conventional listing process. A description of the NHIS sample design is provided by NCHS on the NHIS website. Panel 23 Household Sample Size A subsample of 9,700 households (occupied DUs) selected for MEPS Panel 23 from NHIS responding households in 2017, of which 9,694 were fielded for MEPS after the elimination of any units characterized as ineligible for fielding. Panel 24 Household Sample Size A subsample of 9,700 households was randomly selected for MEPS Panel 24 from the households responding to the 2018 NHIS, of which 9,684 were fielded for MEPS after the elimination of any units characterized as ineligible for fielding. Implications of the New Design on MEPS Estimates Under the new design, MEPS sampled households reflect the clustering of the NHIS, as described above but to a somewhat lesser degree due to the sampling from NHIS responding households. Due to the spreading of the NHIS sample in small subclusters across the PSU and the sampling limited to only NHIS respondents, the impact of clustering on the variance of MEPS estimates may be more limited. Also, in contrast to the previous design, the NHIS sampling rates at the address level currently do not vary due to oversampling of minorities (although this could change in subsequent years). On balance, the overall variation in sampling rates/weights at the national level for the NHIS is expected to be lower with a corresponding positive impact on the precision of MEPS estimates. However, with a reduction in the sample sizes of minority households, precision levels of MEPS estimates for Blacks, Hispanics, and Asians may be reduced to some extent. 3.1.2 Sample Weights and Variance EstimationIn the dataset “MEPS HC-216: 2019 Full Year Consolidated Data File,” weight variables are provided for generating MEPS estimates of totals, means, percentages, and rates for persons and families in the civilian noninstitutionalized population. The person-level weight variable PERWT19F provided in this file supersedes the corresponding person-level weight variable provided in the 2019 Full Year Population Characteristic File (HC-212). Procedures and considerations associated with the construction and interpretation of person and family-level estimates using these and other variables are discussed below. 3.2 The MEPS Sampling Process and Response Rates: An OverviewFor most MEPS panels, a sample representing about three-eighths of the NHIS responding households is made available for use in MEPS. This was the case for both MEPS Panel 23 and Panel 24. Because the MEPS subsampling has to be done soon after NHIS responding households are identified, a small percentage of the NHIS households initially characterized as NHIS respondents are later classified as nonrespondents for the purposes of NHIS data analysis. This actually serves to increase the overall MEPS response rate slightly since the percentage of NHIS households designated for use in MEPS (all those characterized initially as respondents from the NHIS panels and quarters used by MEPS for a given year) is slightly larger than the final NHIS household-level response rate and some NHIS nonresponding households do participate in MEPS. However, as a result, these NHIS nonrespondents who are MEPS participants have no NHIS data available to link with MEPS data. Once the MEPS sample is selected from among the NHIS responding households, households consisting entirely of military personnel are deleted from the sample. Military personnel not living in the same RU as civilians are ineligible for MEPS. After excluding such households, the remaining MEPS sampled households are then fielded in the first round of MEPS. Table 3.1 shows in Rows A, B, and C the three informational components just discussed. Row A indicates the percentage of NHIS households eligible for MEPS. Row B indicates the number of NHIS households sampled for MEPS. Row C indicates the number of sampled households actually fielded for MEPS (after dropping the students and military members discussed above). Note that all response rates discussed here are unweighted.
*Among the panels and quarters of the NHIS allocated to MEPS, the percentage of households that were considered to be NHIS respondents at the time the MEPS sample was selected. 3.2.1 Response RatesIn order to produce annual health care estimates for calendar year 2019 based on the full MEPS sample data from the MEPS Panel 23 and Panel 24, the two panels are combined. More specifically, full calendar year 2019 data collected in Rounds 3 through 5 for the MEPS Panel 23 sample are pooled with data from the first three rounds of data collection for the MEPS Panel 24 sample (the general approach is described below). As mentioned above, all response rates discussed here are unweighted. To understand the calculation of MEPS response rates, some features related to MEPS data collection should be noted. When an RU is visited for a round of data collection, changes in RU membership are identified. Such changes include the formation of student RUs as well as other new RUs created when RU members from a previous round have moved to another location in the U.S. Thus, the number of RUs eligible for MEPS interviewing in a given round is determined after data collection is fully completed. The ratio of the number of RUs completing the MEPS interview in a given round to the number of RUs characterized as eligible to complete the interview for that round represents the “conditional” response rate for that round expressed as a proportion. It is “conditional” in that it pertains to the set of RUs characterized as eligible for MEPS for that round and thus is “conditioned” on prior participation rather than representing the overall response rate through that round. For example, in Table 3.1, for Panel 24, Round 2 the ratio of 6,777 (Row G) to 7,323 (Row F) multiplied by 100 represents the response rate for the round (92.5 percent when computed), conditioned on the set of RUs characterized as eligible for MEPS for that round. Taking the product of the percentage of the NHIS sample eligible for MEPS (Row A) with the product of the ratios for a consecutive set of MEPS rounds beginning with Round 1 produces the overall response rate through the last MEPS round specified. The overall unweighted response rate for the combined sample of Panel 23 and Panel 24 for 2019 was obtained by computing the products of the relative sample sizes and the corresponding overall panel response rates and then summing the two products. Panel 23 represents about 50.0 percent of the combined sample size while Panel 24 represents the remaining 50.0 percent. Thus, the combined response rate of 39.5 percent was computed as 0.500 times 40.4, the overall Panel 23 response rate through Round 5 plus 0.500 times 38.6, the overall Panel 24 response rate through Round 3. 3.2.2 Panel 24 Response RatesFor MEPS Panel 24, Round 1, 9,684 households were fielded in 2019 (Row C of Table 3.1), a randomly selected subsample of the households responding to the 2018 National Health Interview Survey (NHIS). Table 3.1 shows the number of RUs eligible for interviewing in each Round of Panel 24 as well as the number of RUs completing the MEPS interview. Computing the individual round “conditional” response rates as described in section 3.2.1 and then taking the product of these three response rates and the factor 64.3 (the percentage of the NHIS sampled households designated for use in selecting a sample of households for MEPS) yields an overall response rate of 38.6 percent for Panel 24 through Round 3. 3.2.3 Panel 23 Response RatesFor MEPS Panel 23, 9,694 households were fielded in 2018 (as indicated in Row C of Table 3.1), a randomly selected subsample of the households responding to the 2017 National Health Interview Survey (NHIS). Table 3.1 shows the number of RUs eligible for interviewing and the number completing the interview for all five rounds of Panel 23. The overall response rate for Panel 23 was computed in a similar fashion to that of Panel 24 but covering all five rounds of MEPS interviewing as well the factor representing the percentage of NHIS sampled households eligible for MEPS. The overall response rate for Panel 23 through Round 5 is 40.4 percent. 3.2.4 Annual (Combined Panel) Response RateA combined panel response rate for the survey respondents in this data set is obtained by taking a weighted average of the panel-specific response rates. The Panel 23 response rate was weighted by a factor of 0.500 and Panel 24 was weighted by a factor of 0.500, reflecting approximately the distribution of the overall sample between the two panels. The resulting combined response rate for the combined panels was computed as (0.500 x 40.4) plus (0.500 x 38.6) or 39.5 percent (as shown in Table 3.1).3.2.5 OversamplingOversampling is a feature of the MEPS sample design, helping to increase the precision of estimates for some subgroups of interest. Before going into details related to MEPS, the concept of oversampling will be discussed. In a sample where all persons in a population are selected with the same probability and survey coverage of the population is high, the sample distribution is expected to be proportionate to the population distribution. For example, if Hispanics represent 15 percent of the general population, one would expect roughly 15 percent of the persons sampled to be Hispanic. However, in order to improve the precision of estimates for specific subgroups of a population, one might decide to select samples from those subgroups at higher rates than the remainder of the population. Thus, one might select Hispanics at twice the rate (i.e., at double the probability) of persons not oversampled. As a result, an oversampled subgroup comprises a higher proportion of the sample than it represents in the general population. Sample weights ensure that population estimates are not distorted by a disproportionate contribution from oversampled subgroups. Base sample weights for oversampled groups will be smaller than for the portion of the population not oversampled. For example, if a subgroup is sampled at roughly twice the rate of sample selection for the remainder of the population not oversampled, members of the oversampled subgroup will receive base or initial sample weights (prior to nonresponse or poststratification adjustments) that are roughly half the size of the group not oversampled. As mentioned above, oversampling is implemented to increase the sample sizes and thus improve the precision of survey estimates for particular subgroups of the population. The “cost” of oversampling is that the precision of estimates for the general population and subgroups not oversampled will be reduced to some extent compared to the precision one could have achieved if the same overall sample size were selected without any oversampling. The NHIS no longer oversamples households with members who are Asian, Black, or Hispanic. Nevertheless, these minority groups are still of analytic interest for MEPS. As a result for both Panel 23 and Panel 24, all households in the Asian, Hispanic, and Black domains were sampled with certainty (i.e., all households assigned to those domains were included in the MEPS). In addition, all households in Panel 24 who had a member who was a veteran were also selected with certainty. Among all remaining households for Panel 23, the “Other, complete” domain was sampled at a rate of about 69 percent while the “Other, partial complete” domain was sampled at a rate of about 43 percent. For Panel 24, the corresponding sampling rates for the “Other, complete” domain and the “Other, partial complete” domain were about 79 percent and 50 percent, respectively. The somewhat lower sampling rates for Panel 23 arose because the number of households to be selected for MEPS in each panel was 9,700. With the oversampling of households with veterans in Panel 23, fewer were needed from the “Other” domains. Within the “noncertainty” strata (the “Other” domains) for both panels, responding NHIS households were selected for MEPS using a systematic sample selection procedure from among those eligible. The selection of the households was with probability proportionate to size (pps) where the size measure was the inverse of the NHIS initial probability of selection. The pps sampling was undertaken to help reduce the variability in the MEPS weights incurred due to the variability of the NHIS sampling rates. A note with respect to the interpretation of MEPS response rates, which are unweighted. Typically, sample allocations across sample domains change from one MEPS panel to another. The sample domains used may also vary by panel as is the case for Panels 23 and 24. When one compares unweighted measures (e.g., response rates) between panels and years, one should take into account such differences. Suppose, for example, members of one domain have a lower propensity to respond than those of another domain. Then if that domain has been allocated a higher proportion of the sample, the corresponding panel may have a lower unweighted response rate because of the differences in sample allocation. 3.3 Person-Level Weight (PERWT19F)3.3.1 OverviewThere is a single full year person-level weight (PERWT19F) assigned to each record for each key, in-scope person who responded to MEPS for the full period of time that he or she was inscope during 2019. A key person was either a member of a responding NHIS household at the time of interview or joined a family associated with such a household after being out-of-scope at the time of the NHIS (the latter circumstance includes newborns as well as those returning from military service, an institution, or residence in a foreign country). A person is inscope whenever he or she is a member of the civilian noninstitutionalized portion of the U.S. population. 3.3.2 Details on Person-Level Weights ConstructionThe person-level weight PERWT19F was developed in several stages. First, person-level weights for Panel 23 and Panel 24 were created separately. The weighting process for each panel included adjustments for nonresponse over time and a calibration to independent population totals. The calibration was initially accomplished separately for each panel by raking the corresponding sample weights to Current Population Survey (CPS) population estimates based on six variables. The six variables used in the establishment of the initial person-level control figures were: education of the reference person (no degree, high school/GED no college, some college, Bachelor’s degree or higher); census region (Northeast, Midwest, South, West); MSA status (MSA, non-MSA); race/ethnicity (Hispanic; Black, non-Hispanic; Asian, non-Hispanic; and other); sex; and age. A 2019 composite weight was then formed by multiplying each individual panel weight by a factor which reflected the relative sample size of the individual panel compared to the sample size for the two panels combined. The individual panel weights from Panel 23 were multiplied by the factor .500 and each weight from Panel 24 by the factor .500. Using such factors to form composite weights serves to limit the variance of estimates obtained from pooling the two samples. The resulting composite weight was raked to the same set of CPS-based control totals. Then, when the poverty status information (derived from the MEPS income variables) became available, another raking was undertaken, using dimensions reflecting poverty status rather than education level in the previously mentioned six variables. Control totals were established using poverty status (five categories: below poverty, from 100 to 125 percent of poverty, from 125 to 200 percent of poverty, from 200 to 400 percent of poverty, and at least 400 percent of poverty) for this purpose. Thus, the raking for the final weight reflected poverty status as well as the other five variables previously used in the weight calibration. 3.3.3 MEPS Panel 23 Weight Development ProcessThe person-level weight for MEPS Panel 23 was developed using the 2018 full year weight for an individual as a “base” weight for survey participants present in 2019. For key, in-scope members who joined an RU some time in 2019 after being out-of-scope in 2018, the initially assigned person-level weight was the corresponding 2018 family weight. The weighting process included an adjustment for nonresponse over Rounds 4 and 5 as well as a raking to population control figures for December 2019. These control figures were derived by projecting forward the population totals obtained from the March 2019 CPS to correspond to a national estimate for the civilian noninstitutionalized population to reflect the December 31, 2019 estimated population total (estimated based on Census projections for January 1, 2020). Variables used in the establishment of person-level control figures included: education of the reference person (no degree, high school/GED no college, some college, Bachelor’s degree or higher); census region (Northeast, Midwest, South, West); MSA status (MSA, non-MSA); race/ethnicity (Hispanic; Black, non-Hispanic; Asian, non-Hispanic; and other); sex; and age. For confidentiality reasons, the MSA status variables are no longer released for public use (this policy began in 2013). The final weight for key, responding persons who were not inscope on December 31, 2019 but were inscope earlier in the year was the weight after the nonresponse adjustment. Note that the 2018 full-year weight that was used as the base weight for Panel 23 was derived using the MEPS Round 1 weight and adjusting it further for nonresponse over the remaining data collection rounds in 2018 and raking to the December 2018 population control figures. It should be noted that rather than projecting the March 2019 CPS population distribution estimates forward, the standard approach for MEPS has been to scale back from the following year’s CPS estimates. In this case it would have been the March 2020 CPS estimates. However, there was evidence that the onset of the Covid-19 pandemic in March 2020 in the U.S. affected estimates associated with income and education (Rothbaum & Bee, 2020). Since education was planned as one of the variables to be used for raking, it was decided to use the 2019 March CPS data to establish the population estimates for the FY 2019 weights. 3.3.4 MEPS Panel 24 Weight Development ProcessThe person-level weight for MEPS Panel 24 was developed using the MEPS Round 1 person-level weight as a “base” weight. The MEPS Round 1 weights incorporated the following components: the original household probability of selection for the NHIS and for the NHIS subsample reserved for MEPS and an adjustment for NHIS nonresponse, the probability of selection for MEPS from NHIS, adjustment for nonresponse at the dwelling unit level for Round 1, and poststratification to figures at the family and person level obtained from the March CPS data base of the corresponding year (i.e., 2018 for Panel 23 and 2019 for Panel 24). For key, in-scope respondents who joined an RU after Round 1, the Round 1 family weight served as a “base” weight. The weighting process also included an adjustment for nonresponse over Round 2 and the 2019 portion of Round 3 as well as raking to the same population control figures for December 2019 used for the MEPS Panel 23 weights. The same six variables employed for Panel 23 raking (education of the reference person, census region, MSA status, race/ethnicity, sex, and age) were also used for Panel 24 raking. Similar to Panel 23, key, responding persons not in-scope on December 31, 2019 but in-scope earlier in the year retained, as their final Panel 24 weight, the weight after the nonresponse adjustment. 3.3.5 The Final Person-Level Weight for 2019The composite weights of two groups of persons who were out-of-scope on December 31, 2019 were adjusted for expected undercoverage. Specifically, the weights of those who were inscope sometime during the year, out-of-scope on December 31, and entered a nursing home during the year were poststratified to an estimate of the number of persons who were residents of Medicare and Medicaid certified nursing homes for part of the year (approximately 3-9 months) during 2014. This estimate was developed from data on the Minimum Data Set (MDS) of the Center for Medicare and Medicaid Services (CMS). The weights of persons who died while inscope during 2019 were poststratified to corresponding estimates derived using data obtained from the Centers for Disease Control and Prevention (CDC), National Center for Health Statistics (NCHS), Underlying Cause of Death, 1999-2018 on WONDER Online Database, released in 2020, the latest available data at the time. Separate decedent control totals were developed for the “65 and older” and “under 65” civilian noninstitutionalized populations. The sum of the person-level weights across all persons assigned a positive person-level weight, (i.e., for the civilian, noninstitutionalized or in-scope population over the course of the year (based on PERWT19F>0) is 327,396,693 (see Table 3.2). The corresponding total for the population that was inscope on December 31, 2019 is 323,833,996.
3.3.6 A Note on MEPS Population EstimatesBeginning with the 2011 Full Year data, MEPS transitioned to 2010 census-based population estimates from the CPS for poststratification and raking. CPS estimates began reflecting 2010 census-based data in 2012, and the March 2019 CPS data serve as the basis for the 2019 MEPS weight calibration efforts. (Typically, the March 2020 CPS estimates would have been used, but due to the pandemic’s effect on the 2020 CPS estimates discussed in Section 3.3.3, 2019 CPS estimates served as the basis instead). An article discussing the impact of the transition to 2019 census-based population estimates for poststratification and raking on CPS estimates can be found at the Bureau of Labor statistics website. Use of the updated population controls will have a noticeable effect on estimated totals for some population subgroups. The article compares some 2011 CPS estimates for those aged 16 and older “as published” with those that would have been generated had the updated population controls been used. Among the more notable increases were for the following subgroups: those aged 55 or older (about 1.3 million more, a 1.7 percent increase); those aged 16-24 (about a half million more, a 1.4 percent increase); Blacks (400 thousand more, a 1.4 percent increase); Hispanics (1.3 million more, a 3.8 percent increase); and Asians (1.2 million more, a 10 percent increase). Corresponding changes can be anticipated for MEPS full year data beginning with the 2011 MEPS PUF. 3.4 CoverageThe target population associated with this MEPS database is the 2019 U.S. civilian, noninstitutionalized population. However, the MEPS sampled households are a subsample of the NHIS households interviewed in 2017 (Panel 23) and 2018 (Panel 24). New households created after the NHIS interviews for the respective panels and consisting exclusively of persons who entered the target population after 2017 (Panel 23) or after 2018 (Panel 24) are not covered by MEPS. Neither are previously out-of-scope persons who join an existing household but are unrelated to the current household residents. Persons not covered by a given MEPS panel thus include some members of the following groups: immigrants, persons leaving the military, U.S. citizens returning from residence in another country, and persons leaving institutions. Those not covered represent only a small proportion of the MEPS target population. 3.5 Background on Family-Level Estimation Using This MEPS Public Use File3.5.1 OverviewThere are two family weight variables provided in this release: FAMWT19F and FAMWT19C. FAMWT19F can be used to make estimates for the cross-section of families in the U.S. civilian noninstitutionalized population on December 31, 2019 where families are identified based on the MEPS definition of a family unit. Estimates can include MEPS families that existed at some time during 2019 but whose members became out-of-scope prior to the end of the year (e.g., all family members moved out of the country, died, etc.) as well as MEPS families in existence on December 31, 2019. FAMWT19C can be used to make estimates for the cross-section of families in the U.S. civilian, noninstitutionalized population on December 31, 2019 where families are identified based on the CPS definition of a family unit. It may be noted that married couples, regardless of sex, are assigned to the same family unit for the CPS. This represents a definitional change in family structure for the CPS with the 2019 CPS ASEC file, associated specifically with March, 2019. It is reflected in MEPS starting with the 2018 Full Year Consolidated PUF. 3.5.2 Definition of “Family” for Estimation PurposesA MEPS family generally consists of two or more persons living together in the same household who are related by blood, marriage, or adoption. MEPS also defines as a family unmarried persons living together who consider themselves a family unit (these are not families under the CPS definition). Single people who live with neither a relative nor a person identified as a “significant other” have also been assigned a family ID value and a family-level weight. Thus, they can be included or excluded from family-level estimates, as desired. Relatives identified as usual residents of the household who were not present at the time of the interview, such as college students living away from their parents’ home during the school year, were considered as members of the family that identified them. To make estimates at the family level, it is necessary to prepare a family-level file containing one record per family (see instructions below), family-level summary characteristics, and the family-level weight variable (FAMWT19F or FAMWT19C). Each MEPS family unit is uniquely identified by the combination of the variables DUID and FAMIDYR while each CPS family unit is uniquely identified by the combination of the variables DUID and CPSFAMID. Only persons with positive nonzero family weight values are candidates for inclusion in family estimates. Two sets of families for whom estimates can be obtained are defined in Table 3.3 below (along with respective sample sizes). Persons with FMRS1231=1 were a member of a MEPS family on 12/31/19. The more expansive definition of families (second row in Table 3.3) includes families and members of families who were not inscope at the end of the year. While MEPS includes individual persons as family units (about one-third of all units), analysts may restrict their analyses to families with two or more members using the family size variables shown in Table 3.3 (for example, to limit consideration to the cross-section of families with two or more members on December 31, 2019, analyze only families where FAMS1231 is 2 or more). Estimates can also be made for the cross-section of CPS families on December 31, 2019 based on the 12,444 sample CPS families in this data file.
3.5.3 Instructions to Create Family EstimatesThe following is a summary of the steps and the variables to be used for family-level estimation based on the MEPS definition of families.
It should be noted that the MEPS families defined above include members who were out-of-scope on December 31, 2019 although they were members of the family immediately prior to going out of scope for the remainder of the year. If an analyst wishes to restrict MEPS family members to those who were a family member on December 31, 2019, the analyst should restrict family members to those with FMRS1231=1. The following is a summary of the steps and the variables to be used for family-level estimation based on the CPS definition of families.
It should be noted that these CPS-families consist solely of those who were family members on December 31, 2019. 3.5.4 Details on Family Weight Construction and Estimated Number of FamiliesBecause health care related decisions are influenced by a family's economic status, poverty status is incorporated into the poststratification component of the weighting process. However, poverty status is defined based on the CPS definition of a family, which differs from the MEPS family definition in that unmarried partners living together are considered separate family units. Since data are collected in MEPS family units (RUs), prior to poststratification MEPS families in existence on December 31, 2019 containing unmarried partners living together were partitioned into units that correspond to CPS families (families with no unmarried partners are defined as family units in both MEPS and CPS). The process of calibrating the family weights to achieve consistency with CPS control figures was carried out in several steps. First, all CPS-like family units were assigned an initial family-level weight based on the person-level weight (PERWT19F) of the family reference person (FAMRFPYR=1) of the MEPS family with which they were associated. These CPS family-level weights (FAMWT19C) were obtained by raking to population control figures derived from CPS estimates for December 2019 (derived by projecting the family population totals for the March 2019 CPS forward to reflect December 31, 2019). In addition to poverty status, the calibration process for the family-level weights incorporated the following variables: Census region; MSA status; race/ethnicity of reference person (Hispanic, Black but non-Hispanic, Asian, and other); family type (reference person married, living with spouse; male reference person, unmarried or spouse not present; female reference person, unmarried or spouse not present); age of reference person; and family size on December 31, 2019. The family-level weight variable for MEPS families (FAMWT19F) was then constructed by putting MEPS families that consisted of more than one CPS-like family back together and assigning the MEPS family-level weight based on the CPS family weight of the MEPS family reference person. The weighted population estimate for CPS families on December 31, 2019 based on 12,444 CPS families in the sample is 145,285,837. Overall, the weighted population estimate for the 11,824 MEPS family units containing at least one member of the U.S. civilian, noninstitutionalized population on December 31, 2019 (those families whose members have FAMWT19F>0 and FMRS1231=1) is 138,747,663. The inclusion of families whose members left the in-scope population prior to December 31, 2019 increases the estimated total number of families represented by the 11,924 MEPS responding families (whose members have FAMWT19F>0) to 139,808,763.
3.6 Analysis Using Health Insurance Eligibility UnitsTo construct a weight for use in analysis using Health Insurance Eligibility Units, as identified by the variable HIEUIDX:
If the weight of the HIEU head is zero, delete the case. 3.7 Weights and Response Rates for the Self-Administered QuestionnaireFor analytic purposes, a single person-level weight variable, SAQWT19F, has been provided for use with the data obtained from the Self-Administered Questionnaire (SAQ). This questionnaire was administered in Panel 24, Round 2 and Panel 23, Round 4 and was to be completed by each adult (person aged 18 or older) in the family. Thus, the target population for the SAQ is adults in the civilian, noninstitutionalized population at the time data were collected for Rounds 2/4 (generally speaking, the fall of the year in question). The final full-year person-level SAQ weight for 2019 was constructed as follows with only those with a 2019 full year person weight (PERWT19F>0) eligible to receive the 2019 SAQ weight. The weighting process was similar to that of the full sample person-level weights: nonresponse adjustments for the weights for each panel separately; raking to CPS control totals; compositing the weights from the two panels; and finally re-raking of the composited weights. Variables used in the nonresponse adjustment process were region, MSA status, family size, marital status, level of education, health status, health insurance status, age, sex, and race/ethnicity. The weights were raked to Current Population Survey (CPS) estimates corresponding to December 2019 (the same source of control figures used for the full year person weights). The variables used to form control figures (education of the reference person, region, MSA status, age, sex, and race/ethnicity) are the same variables that were used for the full year person weights. The only difference was that age categories were developed after excluding ages under 18, since only adults were eligible for the SAQ. The final 2019 SAQ weight for this consolidated data file was then obtained by raking the preliminary weight to CPS estimates that were based on poverty status (replacing education of the reference person) as well as the aforementioned variables. This final weight was assigned the variable name SAQWT19F. In all, there were 17,855 persons assigned an SAQ weight with the sum of the weights being 250,108,964 (an estimate of the civilian, noninstitutionalized population aged 18 or older at the time the SAQ was administered). The Panel 23 unweighted response rate for the 2019 SAQ was 84.5 percent, while the Panel 24 unweighted response rate for the 2019 SAQ was 79.7 percent. Pooled unweighted response rates for the survey respondents have been computed by taking a weighted average of the panel-specific response rates, where the weights were the relative proportion of persons with sample weights associated with each panel (a value of 0.51 was associated with Panel 23, and a value of 0.49 was associated with Panel 24). The pooled unweighted response rate for the combined panels for the 2019 SAQ is 82.1 percent. 3.8 Weights and Response Rates for the Diabetes Care SurveyA person-level weight, DIABW19F, was developed for use with the data obtained from the Diabetes Care Survey (DCS). This weight was assigned to each person aged 18 or over with an SAQ weight who completed the DCS and self-reported as having diabetes. (Although diabetes diagnosis is now asked of all ages, the DCS is only given to participants if they are 18 years of age or older.) The general weighting process was to assign each individual eligible for a DCS weight the SAQ expenditure weight as the initial weight. This weight was adjusted to compensate for RU level nonresponse to the question as to whether or not each RU member had diabetes and then for nonresponse among those receiving the DCS questionnaire. Prior to Panel 12, the identification of people eligible to receive the DCS questionnaire was focused on the Rounds 3/5 interview. During the Rounds 3/5 regular MEPS interview, each RU respondent was asked to complete a “conditions” question to identify all current/deceased/institutionalized RU members of any age who had been diagnosed with diabetes. Each RU member who was identified as having diabetes by the RU respondent was then eligible to receive the DCS questionnaire. To determine which DCS respondents actually had diabetes (and thus were members of the target population), each DCS respondent was asked if s/he was told by a physician that s/he had diabetes. While the DCS questionnaire has been distributed to persons under the age of 18, the constructed DCS variables released in the person-level PUF apply only to adults. Beginning in Panel 12, a different screening process has been employed to identify those eligible to receive the DCS questionnaire. This process involves asking screener questions in each round, but the group of persons about whom these questions asks varies from round to round. In Round 1, the RU respondent is asked to identify all RU members (including those who went out of scope unless they died prior to the date of interview) with diabetes. In Rounds 2/4, the same screening information is gathered but only for new RU members (as long as they did not die during the round). In Round 3 the screening questions are asked of the RU respondent for all RU members who were: (a) inscope sometime during the round but had not died prior to the date of interview; and (b) had not been identified as having diabetes in a previous round (this includes people with missing data, classified as not having diabetes in all previous rounds of MEPS, and all new members of the RU in Round 3). Any RU member who has been identified by the RU respondent as having diabetes at any time during MEPS will be asked to complete a DCS questionnaire. This process has been designed to help ensure that all RU members with diabetes will be given a DCS questionnaire to complete. Note that only those 18 years or older were asked to complete a DCS questionnaire. In all, 1,662 people were assigned a DCS weight (DIABW19F>0). The sum of the DCS weights is 25,983,422, an estimate of the adult population self-reporting as having been diagnosed with diabetes based on the two-step process described above. The Panel 23 unweighted response rate for the 2019 DCS was 69.1 percent after rounding. The Panel 24 unweighted response rate for the 2019 DCS was 62.4 percent. The pooled unweighted response rate for the combined panels for the DCS is 65.8 percent. 3.9 Weights and Response Rates for the Veteran Self-Administered QuestionnaireA person-level weight, VSAQW19F, was developed for use with the data obtained from the Veterans Self-Administered Questionnaire (VSAQ). This weight was assigned to each person with a final person-level weight (PERWT19F>0) who also completed the VSAQ and self-reported as being a veteran. Veterans were oversampled for Panel 23 but not Panel 24. The weighting process paralleled the interviewing process of veterans. To determine veterans eligible for the study, the interviewing process called for first having the RU respondent identify those members of an RU who he or she thought were veterans. Specifically, for Panel 23, this was the Round 3 RU respondent while for Panel 24, it was the Round 1 RU respondent. The criteria for identifying a veteran were the same used for the American Community Survey (ACS). Note that veterans are identified in the ACS by a household respondent and are not asked to confirm whether this identification is correct. All RU members so identified as a veteran were asked to complete the VSAQ. The first question of the VSAQ asked the respondent to self-identify as a veteran. A small percentage of the VSAQ respondents indicated that they were not veterans and thus were ineligible to complete the remainder of the survey. The weighting process was established as follows. Those identified as veterans by the RU respondent were assigned as an initial weight the final 2019 Point-in-Time person-level weight, WGTSP13. The resulting weights were then raked to control totals based on the average of 2018 and 2019 ACS data on veterans to achieve consistency with an ACS estimate that represents approximately the same time period as when the VSAQ was administered. A nonresponse adjustment was then undertaken to account for nonresponse to the VSAQ as well as to account for the fact that some of the individuals identified as veterans indicated that they were not. A final nonresponse adjustment was undertaken to compensate for those persons who were eligible for and completed the VSAQ but later became a MEPS nonrespondent over the course of 2019 data collection. In all, 1,131 people were assigned a VSAQ weight (VSAQW19F>0). The sum of the VSAQ weights is 16,158,443, an estimate of the adult population self-reporting as being veterans based on the three-step process described above. As discussed above, the sum of these weights is, by design, smaller than the estimated number of veterans based on ACS figures. This is consistent with the fact that some VSAQ respondents self-reported as "not a veteran" while this opportunity is not provided in the ACS. The ACS estimate of veterans obtained as described above was about 17.69 million. The corresponding MEPS estimate of veterans based strictly on the reports of the MEPS RU respondent was about 18.18 million. The pooled unweighted response rate for the VSAQ is 73.6 percent. Since veterans were oversampled for Panel 23, a weighted response rate was also computed. The weighted response rate reflects the different sampling rates of veterans depending on the panel in which they appeared. Its value is 73.5 percent, only slightly different from the unweighted response rate. The VSAQ was fielded during Panel 22 Round 5, Panel 23 Round 3, and Panel 24 Round 1. The VSAQ data for Panels 22 and 23 were included in the 2018 FY file with weight VSAQW18F and the data for Panels 23 and 24 were included in the 2019 FY file with weight VSAQW19F. The data for these three panels can be combined to produce more accurate estimates of VSAQ variables. This can be done by pooling 2018 FY and 2019 FY files and dividing each year's VSAQ weight by 2 to derive a VSAQ weight for the pooled file, as done in the usual 2-year pooling of MEPS FY files. However, for variance estimation, when pooling any year with the 2019 FY file, the common variance structure must be obtained from the pooled linkage public use file HC-036, as discussed in Section 3.10.1. 3.10 Variance EstimationThe MEPS is based on a complex sample design. To obtain estimates of variability (such as the standard error of sample estimates or corresponding confidence intervals) for MEPS estimates, analysts need to take into account the complex sample design of MEPS for both person-level and family-level analyses. Several methodologies have been developed for estimating standard errors for surveys with a complex sample design, including the Taylor-series linearization method, balanced repeated replication, and jackknife replication. Various software packages provide analysts with the capability of implementing these methodologies. MEPS analysts most commonly use the Taylor Series approach. Although this data file does not contain replicate weights, the capability of employing replicate weights constructed using the Balanced Repeated Replication (BRR) methodology is also provided if needed to develop variances for more complex estimators (see section 3.10.2). 3.10.1 Taylor-series Linearization MethodThe variables needed to calculate appropriate standard errors based on the Taylor-series linearization method are included on this and all other MEPS public use files. Software packages that permit the use of the Taylor-series linearization method include SUDAAN, R, Stata, SAS (version 8.2 and higher), and SPSS (version 12.0 and higher). For complete information on the capabilities of a package, analysts should refer to the corresponding software user documentation. Using the Taylor-series linearization method, variance estimation strata and the variance estimation PSUs within these strata must be specified. The variables VARSTR and VARPSU on this MEPS data file serve to identify the sampling strata and primary sampling units required by the variance estimation programs. Specifying a “with replacement” design in one of the previously mentioned computer software packages will provide estimated standard errors appropriate for assessing the variability of MEPS survey estimates. It should be noted that the number of degrees of freedom associated with estimates of variability indicated by such a package may not appropriately reflect the number available. For variables of interest distributed throughout the country (and thus the MEPS sample PSUs), one can generally expect to have at least 100 degrees of freedom associated with the estimated standard errors for national estimates based on this MEPS database. Prior to 2002, MEPS variance strata and PSUs were developed independently from year to year, and the last two characters of the strata and PSU variable names denoted the year. Beginning with the 2002 Point-in-Time PUF, the approach changed with the intention that variance strata and PSUs would be developed to be compatible with all future PUFs until the NHIS design changed. Thus, when pooling data across years 2002 through the Panel 11 component of the 2007 files, the variance strata and PSU variables provided can be used without modification for variance estimation purposes for estimates covering multiple years of data. There were 203 variance estimation strata, each stratum with either two or three variance estimation PSUs. From Panel 12 of the 2007 files, a new set of variance strata and PSUs were developed because of the introduction of a new NHIS design. There are 165 variance strata with either two or three variance estimation PSUs per stratum starting from Panel 12. Therefore, there are a total of 368 (203+165) variance strata in the 2007 Full Year file as it consists of two panels that were selected under two independent NHIS sample designs. Since both MEPS panels in the Full Year files from 2008 through 2016 were based on the next NHIS design, there are only 165 variance strata. These variance strata (VARSTR values) have been numbered from 1001 to 1165 so that they can be readily distinguished from those developed under the former NHIS sample design in the event that data are pooled for several years. As discussed, a complete change was made to the NHIS sample design in 2016, effectively changing the MEPS design beginning with calendar year 2017. There were 117 variance strata originally formed under this new design intended for use until the next fully new NHIS design was implemented. In order to make the pooling of data across multiple years of MEPS more straightforward, the numbering system for the variance strata has changed. Those strata associated with the new design (implemented in 2016) were numbered from 2001 to 2117. However, the new NHIS sample design implemented in 2016 was further modified in 2018. With the modification in the 2018 NHIS sample design, the MEPS variance structure for the 2019 Full Year file has also had to be modified, reducing the number of variance strata to 105. Consistency was maintained with the prior structure in that the 2019 Full Year file variance strata were also numbered within the range of values from 2001-2117, although there are now gaps in the values assigned within this range. Some analysts may be interested in pooling data across multiple years of MEPS data. To obtain appropriate standard errors when doing so, it is necessary to specify a common variance structure. Prior to 2002, each annual MEPS public use file was released with a variance structure unique to the particular MEPS sample in that year. Starting in 2002, the annual MEPS public use files were released with a common variance structure that allowed users to pool data from 2002 through 2018. However, with the need to modify the variance structure for 2019, this cannot be routinely done. To ensure that variance strata are identified appropriately for variance estimation purposes when pooling MEPS data across several years, one can proceed as follows:
3.10.2 Balanced Repeated Replication (BRR) MethodBRR replicate weights are not provided on this MEPS PUF for the purposes of variance estimation. However, a file containing a BRR replication structure is made available so that the users can form replicate weights, if desired, from the final MEPS weight to compute variances of MEPS estimates using either BRR or Fay’s modified BRR (Fay 1989) methods. The replicate weights are useful to compute variances of complex non-linear estimators for which a Taylor linear form is not easy to derive and not available in commonly used software. For instance, it is not possible to calculate the variances of a median or the ratio of two medians using the Taylor linearization method. For these types of estimators, users may calculate a variance using BRR or Fay’s modified BRR methods. However, it should be noted that the replicate weights have been derived from the final weight through a shortcut approach. Specifically, the replicate weights are not computed starting with the base weight and all adjustments made in different stages of weighting are not applied independently in each replicate. Thus, the variances computed using this one-step BRR do not capture the effects of all weighting adjustments that would be captured in a set of full developed BRR replicate weights. The Taylor Series approach does not fully capture the effects of the different weighting adjustments either. The dataset HC-036BRR, MEPS 1996-2018 Replicates for Variance Estimation File, contains the information necessary to construct the BRR replicates. It contains a set of 128 flags (BRR1–BRR128) in the form of half sample indicators, each of which is coded 0 or 1 to indicate whether the person should or should not be included in that particular replicate. These flags can be used in conjunction with the full-year weight to construct the BRR replicate weights. For analysis of MEPS data pooled across years, the BRR replicates can be formed in the same way using the HC-036, MEPS 1996-2018 Pooled Linkage Variance Estimation File. For more information about creating BRR replicates, users can refer to the documentation for the HC-036BRR pooled linkage file on the AHRQ website. 3.11 Guidelines for Determining which Weight to Use for Analyses Involving Data/Variables from Multiple Sources and Supplements: MEPS 2019 Full-Year Use FileWhich weight variable to use is decided based on a hierarchy. For person-level analyses not involving variables from the SAQ, VSAQ, or DCS, PERWT19F should always be used. For person-level analysis involving variables from the SAQ but not the DCS, the SAQWT19F should be used. For example, if examining access to care or quality of care variables from the SAQ by socio-demographics, health status, or health insurance status, SAQWT19F is the appropriate weight even though person-level socio-demographic, health status, and health insurance status variables are part of the core person-level questionnaire. Whenever data from the Diabetes Care Survey (DCS) are used, alone or in conjunction with data from other questionnaires, the weight variable DIABW19F should be used for those eligible to provide DCS data. Similarly, whenever data from the VSAQ are used, the weight variable VSAQW19F should be used for those eligible to provide VSAQ data. For all family-level analyses, FAMWT19F or FAMWT19C should be used. 3.12 Using MEPS Data for Trend AnalysisMEPS began in 1996, and the utility of the survey for analyzing health care trends expands with each additional year of data; however, there are a variety of methodological and statistical considerations when examining trends over time using MEPS. Examining changes over longer periods of time can provide a more complete picture of underlying trends. In particular, large shifts in survey estimates over short periods of time (e.g. from one year to the next) that are statistically significant should be interpreted with caution unless they are attributable to known factors such as changes in public policy, economic conditions, or survey methodology. With respect to methodological considerations, in 2013 MEPS introduced an effort focused on field procedure changes such as interviewer training to obtain more complete information about health care utilization from MEPS respondents with full implementation in 2014. This effort likely resulted in improved data quality and a reduction in underreporting starting in the 2014 full year files and have had some impact on analyses involving trends in utilization across years. The aforementioned change in the NHIS sample design in 2016 could also potentially affect trend analyses. The new NHIS sample design is based on more up-to-date information related to the distribution of housing units across the U.S. As a result, it can be expected to better cover the full U.S. civilian, noninstitutionalized population, the target population for MEPS, as well as many of its subpopulations. Better coverage of the target population helps to reduce the potential for bias in both NHIS and MEPS estimates. Another change with the potential to affect trend analysis involved major modifications to the MEPS instrument design and data collection process, particularly in the events section of the instrument. These were introduced in the Spring of 2018 and thus affected data beginning with Round 1 of Panel 23, Round 3 of Panel 22, and Round 5 of Panel 21. Since the Full Year 2017 PUFs were established from data collected in Rounds 1-3 of Panel 22 and Rounds 3-5 of Panel 21, they reflected two different instrument designs. In order to mitigate the effect of such differences within the same full year file, the Panel 22 Round 3 data and the Panel 21 Round 5 data were transformed to make them as consistent as possible with data collected under the previous design. The changes in the instrument were designed to make the data collection effort more efficient and easy to administer. In addition, expectations were that data on some items, such as those related to health care events, would be more complete with the potential of identifying more events. Increases in service use reported since the implementation of these changes are consistent with these expectations. The MEPS instrument design changed beginning in Spring of 2018, affecting Panel 23 Round 1, Panel 22 Round 3, and Panel 21 Round 5. For the Full-Year 2017 PUFs, but not subsequent full-year PUFs, the Panel 22 Round 3 and Panel 21 Round 5 data were transformed to the degree possible to conform to the previous design. Data users should be aware of possible impacts on the data and especially trend analysis for these data years due to the design transition. Process changes, such as data editing and imputation, may also affect trend analyses. For example, users should refer to section 2.5.11 above and, for more detail, the documentation for the prescription drug file (HC-213A) when analyzing prescription drug spending over time. As always, it is recommended that data users review relevant sections of the documentation for descriptions of these types of changes that might affect the interpretation of changes over time before undertaking trend analyses. Analysts may also wish to consider using statistical techniques to smooth or stabilize analyses of trends using MEPS data such as comparing pooled time periods (e.g. 1996-97 versus 2011-12), working with moving averages or using modeling techniques with several consecutive years of MEPS data to test the fit of specified patterns over time. Finally, statistical significance tests should be conducted to assess the likelihood that observed trends are not attributable to sampling variation. In addition, researchers should be aware of the impact of multiple comparisons on Type I error. Without making appropriate allowance for multiple comparisons, undertaking numerous statistical significance tests of trends increases the likelihood of concluding that a change has taken place when one has not. ReferencesBethel CD, Read D, Stein REK, Blumberg SJ, Wells N, Newacheck PW. Identifying Children with Special Health Care Needs: Development and Evaluation of a Short Screening Instrument. Ambulatory Pediatrics Volume 2, No. 1, January-February 2002, pp 38-48. Bird HR, Andrews H, et. al. Global Measures of Impairment for Epidemiologic and Clinical Use with Children and Adolescents. International Journal of Methods in Psychiatric Research, vol. 6, 1996, pp. 295-307. Chowdhury, S.R., Machlin, S.R., Gwet, K.L. Sample Designs of the Medical Expenditure Panel Survey Household Component, 1996–2006 and 2007–2016. Methodology Report #33. January 2019. Agency for Healthcare Research and Quality, Rockville, MD. Fay, R.E. (1989). Theory and Application of Replicate Weighting for Variance Calculations. Proceedings of the Survey Research Methods Sections, ASA, 212-217. Kessler, R.C., Andrews, G., Colpe, L.J., Hiripi, E., Mroczek, D.K., Normand, S.L., Walters, E.E., and Zaslavsky, A.M. (2002). Short screening scales to monitor population prevalence and trends in non-specific psychological distress. Psychological Medicine 32: 959-976. Kroenke, K., Spitzer, R.L., and Williams, J.B. (2003). The Patient Health Questionnaire-2: Validity of a two-item depressive screener. Medical Care 41: 1284-1292. Rothbaum, J. and Bee, A. (2020). Coronavirus Infects Surveys, Too: Nonresponse Bias During the Pandemic in the CPS ASEC (SEHSD Working Paper Number 2020-10). U.S. Census Bureau. Selim A, Rogers W, Qian S, Rothendler JA, Kent EE, Kazis LE. A new algorithm to build bridges between two patient-reported health outcome instruments: the MOS SF-36® and the VR-12 Health Survey. Qual Life Res. 2018 Aug; 27(8):2195-2206. View Related Profiles. DOI: 10.1007/s11136-018-1850-3. Selim AJ, Rogers W, Fleishman JA, Qian SX, Fincke BG, Rothendler JA, Kazis LE. Updated U.S. population standard for the Veterans RAND 12-item Health Survey (VR-12). Qual Life Res. 2009 Feb; 18(1):43-52. View Related Profiles. PMID: 19051059; DOI: 10.1007/s11136-008-9418-2. D. Variable-Source CrosswalkFOR MEPS HC-216: 2019 CONSOLIDATED DATA FILE
Appendix 1
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Condensed Industry Code | Census Industry Code Range | Description |
|---|---|---|
| 1 | 0170 – 0290 | Natural Resources |
| 2 | 0370 – 0490 | Mining |
| 3 | 0770 | Construction |
| 4 | 1070 – 3990 | Manufacturing |
| 5 | 4070 – 5790 | Wholesale and Retail Trade |
| 6 | 0570 – 0690, 6070 – 6390 | Transportation and Utilities |
| 7 | 6470 – 6780 | Information |
| 8 | 6870 – 7190 | Financial Activities |
| 9 | 7270 – 7790 | Professional and Business Services |
| 10 | 7860 – 8470 | Education, Health, and Social Services |
| 11 | 8560 – 8690 | Leisure and Hospitality |
| 12 | 8770 – 9290 | Other Services |
| 13 | 9370 – 9590 | Public Administration |
| 14 | 9890 | Military |
| 15 | 9990 | Unclassifiable Industry |
MEPS uses the 4-digit Census occupation and industry coding systems developed for the Current Population Survey and the American Community Survey.
For industry coding, MEPS uses the 2007 4-digit Census industry codes. Descriptions of the 4-digit Census industry codes can be found at the U.S. Bureau of Labor Statistics website.
For occupation coding, MEPS uses the 2010 4-digit Census occupation codes. Descriptions of the 4-digit Census occupation codes can be found at the U.S. Bureau of Labor Statistics website.
See Census IO Index for more information on the Census coding systems used by MEPS.
| Condensed Occupation Code | Census Occupation Code Range | Description |
|---|---|---|
| 1 | 0010 – 0950 | Management, Business, and Financial Operations Occupations |
| 2 | 1005 – 3540 | Professional and Related Occupations |
| 3 | 3600 – 4650 | Service Occupations |
| 4 | 4700 – 4965 | Sales and Related Occupations |
| 5 | 5000 – 5940 | Office and Administrative Support Occupations |
| 6 | 6005 – 6130 | Farming, Fishing, and Forestry Occupations |
| 7 | 6200 – 7630 | Construction, Extraction, and Maintenance Occupations |
| 8 | 7700 – 9750 | Production, Transportation, and Material Moving Occupations |
| 9 | 9840 | Military Specific Occupations |
| 10 | 9920 | Not in Labor Force |
| 11 | 9990 | Unclassifiable Occupation |
MEPS uses the 4-digit Census occupation and industry coding systems developed for the Current Population Survey and the American Community Survey.
For industry coding, MEPS uses the 2007 4-digit Census industry codes. Descriptions of the 4-digit Census industry codes can be found at the U.S. Bureau of Labor Statistics website.
For occupation coding, MEPS uses the 2010 4-digit Census occupation codes. Descriptions of the 4-digit Census occupation codes can be found at the U.S. Bureau of Labor Statistics website.
See the Census IO Index for more information on the Census coding systems used by MEPS.
| HEALTH SERVICE CATEGORY | UTILIZATION VARIABLE(S) | EXPENDITURE VARIABLE(S) [1] |
|---|---|---|
| All Health Services | -- | TOT***19 |
| Total Office Based Visits (Physician + Non-physician + Unknown) | OBTOTV19 | OBV***19 |
| Office Based Visits to Physicians | OBDRV19 | OBD***19 |
| Total Outpatient Visits (Physician + Non-physician + Unknown) | OPTOTV19 | -- |
| Sum of Facility and SBD Expenses | -- | OPT***19 |
| Facility Expense | -- | OPF***19 |
| SBD Expense | -- | OPD***19 |
| Outpatient Visits to Physicians | OPDRV19 | -- |
| Facility Expense | -- | OPV***19 |
| SBD Expense | -- | OPS***19 |
| Total Emergency Room Visits | ERTOT19 | -- |
| Sum of Facility and SBD Expenses | -- | ERT***19 |
| Facility Expense | -- | ERF***19 |
| SBD Expense | -- | ERD***19 |
| Total Inpatient Stays | IPDIS19, IPNGTD19 | -- |
| Sum of Facility and SBD Expenses | -- | IPT***19 |
| Facility Expense | -- | IPF***19 |
| SBD Expense | -- | IPD***19 |
| Total Prescription Medicines | RXTOT19 | RX***19 |
| Total Dental Visits | DVTOT19 | DVT***19 |
| Total Home Health Care | HHTOTD19 | -- |
| Agency Sponsored | HHAGD19 | HHA***19 |
| Paid Independent Providers | HHINDD19 | HHN***19 |
| Informal | HHINFD19 | -- |
| Vision Aids | -- | VIS***19 |
| Other Medical Supplies and Equipment | -- | OTH***19 |
[1] See key at end of table for specific categories for ***.
| Source of Payment Category | *** |
|---|---|
| Total payments (sum of all sources) | EXP |
| Out of Pocket | SLF |
| Medicare | MCR |
| Medicaid | MCD |
| Private Insurance | PRV |
| Veteran’s Administration/CHAMPVA | VA |
| TRICARE | TRI |
| Other Federal Sources | OFD |
| Other State and Local Sources | STL |
| Workers’ Compensation | WCP |
| Other Unclassified Sources | OSR |
| Collapsed Source of Payment Category | *** |
|---|---|
| Private and TRICARE | PTR |
| Other Federal, Other State and Local, and Other Unclassified Sources | OTH |
| Total charges[2] | TCH |
[2] No charge variables on file for prescription medicines.