The MEPS-IC is an annual survey that collects information about employer-sponsored health insurance offerings in the United States. Collection began with the 1996 survey year.
A nationally representative sample of employers, developed from Census Bureau list frames for the private sector and State and local governments, is the basis for the survey and the posted tables of estimates.
Beginning with the 2008 survey reference year, the MEPS-IC survey’s collection year is the same as the calendar year (current collection). Prior to 2008, collection for a survey reference year was done in the following calendar year (retrospective collection) – i.e., 2005 survey year data were collected in calendar year 2006. The switch to calendar year collection allows the survey to release private sector estimates for a given survey year a full 12 months earlier than was possible for the pre-2008 surveys. For example, 2008 estimates were released in July 2009; without the switch, they would have been released in July 2010. State and local governments’ estimates are released several months after the private sector estimates for the same survey year. (Due to the change to current collection, 2007 estimates are not available.)
The following types of national estimates are available from the MEPS-IC private-sector tables posted on the survey’s website:
- Establishment based (for example, the percent of establishments that offer health insurance)
- Employee based (for example, the percent of employees that enroll in health insurance plans)
- Premiums and employee contributions for enrollees, including averages and percentile distributions
- Deductibles and copayments for enrollees
These estimates are defined for firm size, industry, and other establishment characteristics.
Government tables have estimates similar to those for the private sector, broken out for State governments and local governments by size.
See the Glossary for definitions of terms used in the survey questionnaires and tables of estimates.
(NOTE: Collection for the MEPS-IC Household Link Sample, a sample of employers of persons who responded to the MEPS Household Component (MEPS-HC) survey, was suspended in 2002.)
^top
II. State Estimates
In addition to producing national estimates, the sample allocation and design of the MEPS-IC sample also supports reliable private sector State-level estimates of the same type noted above.
Since 2003, there has been a sufficient MEPS-IC sample each year to support State-level estimates in all 50 States and the District of Columbia. (For survey purposes, the District of Columbia is treated as a State.) When the survey began, cost constraints prevented the fielding of a sufficiently large sample to support State estimates for all States every year. In 1996, estimates were made for the 40 most populous States. From 1997 through 2002, the MEPS-IC rotated the samples in the 20 least populated States to insure that every State received an adequate sample size to make State-level estimates at least once every four years. The 21 States that were not allocated sufficient sample for estimates each year during the years 1996 - 2002 are listed in the following table. An "X" indicates the year(s) for which State estimates are available for that State. A blank indicates that estimates are not available for that State in that year. The State rotation schedule was modified in 2001 to reflect changes in State population rankings based on the 2000 Census.
States with smaller populations for which MEPS-IC estimates are not available each year 1996–2002
| State |
1996 |
1997 |
1998 |
1999 |
2000 |
2001 |
2002 |
| Alaska |
|
X |
|
|
|
X |
|
| Arkansas |
X |
X |
X |
X |
X |
X |
|
| Delaware |
|
|
X |
|
|
X* |
X |
| District of
Columbia |
|
X |
|
|
|
X |
|
| Hawaii |
X |
X |
|
X |
|
X |
X* |
| Idaho |
|
|
X |
|
|
X |
|
| Kansas |
X |
X |
X |
X |
X |
** |
X |
| Maine |
X |
X |
|
X |
|
X |
X* |
| Mississippi |
X |
X |
|
X |
X |
X |
X |
| Montana |
|
|
|
X |
|
|
X* |
| Nebraska |
X |
|
X |
X |
X |
|
X |
| Nevada |
X |
X |
|
X |
|
X |
X |
| New Hampshire |
|
|
X |
|
X |
** |
X |
| New Mexico |
X |
|
X |
|
X |
|
X |
| North Dakota |
|
|
|
|
X |
|
|
| Rhode Island |
|
X |
|
X |
|
X |
|
| South Dakota |
|
|
|
|
X |
** |
|
| Utah |
X |
X |
X |
|
X |
X |
X |
| Vermont |
|
|
|
X |
|
X* |
|
| West Virginia |
X |
|
X |
|
X |
|
X |
| Wyoming |
|
|
X |
|
|
|
X |
Note: An X indicates that State-level estimates are available for that year; a blank indicates that there are no estimates for that year.
* States received an additional sample that supported a full set of State estimates not otherwise possible.
** States received an additional sample that supported estimates for smaller firms only.
Federal agencies, State governments, and non-profit organizations have occasionally provided additional funding to increase the MEPS-IC samples in selected States. The two most common reasons for funding larger State samples are 1) to improve the accuracy of the State estimates for that year or 2) to provide sufficient sample for production of State estimates in a year where no estimates would have been produced otherwise. In the table below, States that received increased samples are listed by year. In 2001 and 2002, the increased samples resulted in additional States for which estimates could be produced. These additional estimates are provided on the MEPS-IC Web site to all data users.
List of States for the year with sample purchases
| Year |
States with additional sample purchases |
| 1998 |
Arizona, Massachusetts, Washington |
| 2000 |
Arkansas, Wisconsin |
| 2001 |
Delaware*,
Vermont*,
Kansas**,
New Hampshire**,
South Dakota**,
Wisconsin |
| 2002 |
Hawaii*,
Maine*,
Montana*,
Maryland, Virgin Islands*** |
| 2003 |
Virginia |
* States received an additional sample that supported a full set of State estimates not otherwise possible.
** States received an additional sample that supported estimates for smaller firms only.
*** The U.S. Virgin Islands received a special sample to support a full set of estimates. These data are not included in the calculation of totals for the United States.
^top
Starting with the 2002 data collection, the sample allocation and design of the MEPS-IC sample also supports a limited set of reliable private sector metropolitan-level estimates of the following:
- The percent of establishments that offer health insurance
- The percent of employees that enroll in health insurance plans, are eligible to enroll, and enroll when they are eligible
- Average premiums and employee contributions for those enrolled in employer-sponsored health insurance plans
Estimates are provided for the 20 largest metro areas nationwide and for at least one metro area within each state. The metropolitan statistical areas with a sufficient sample size to support reliable estimates with the MEPS-IC are geographically defined in the following three tables:
^top
The MEPS-IC private-sector sample is selected, and collection takes place at the establishment (unit) level. An establishment is generally a single physical location; a firm can consist of just a single establishment or multiple establishments. The sampling unit for governments is the parent agency and any dependent agencies. In the following discussion, the term establishment is used to refer to both the private-sector and state and local government sampling unit.
For all sample units except 1) State governments, 2) very large local governments, and 3) those in complex multi-unit (those with nine or more establishments in the sample) private sector firms, each sample unit is initially prescreened by telephone. The purpose of this screening is to:
-
Determine whether or not health insurance is offered to employees at each establishment.
-
Obtain the name, title, and address of an appropriate person in each establishment to whom a MEPS-IC questionnaire will be mailed (for establishments offering health insurance).
-
Identify any establishment that no longer exists, has closed, or has merged with others.
If the employer did not offer health insurance, a brief set of questions about establishment characteristics are asked during the screening process and the case is considered a complete response. This provides an inexpensive method to collect the necessary data from the large number of employers who did not offer health insurance, while minimizing the collection burden on those generally small employers.
If the employer did offer health insurance, several short questions are asked, and the employer is later mailed a MEPS-IC questionnaire to obtain the remaining needed information. All establishments not reached during the screening process are given the option of responding electronically first. If an establishment fails to respond, a follow-up request is sent a few weeks later. Establishments that also fail to respond are then sent paper survey forms. If the establishments continue to not respond they are contacted by telephone and the survey is conducted using computer-assisted telephone interviewing (CATI) technology.
For the purpose of this survey, establishments indicating that they offered health insurance to their employees must answer key information on their health insurance offerings to be considered full respondents. Callbacks are made to respondents not providing all of the key information in order to complete their questionnaires. Respondents that do not provide this key information, but are known to offer insurance, are considered partial respondents. Establishments that were not prescreened, did not return the mail questionnaires and did not respond to follow-up phone calls are classified as non-respondents. For this group, the availability of health insurance for employees at the establishment is unknown.
Data for large governments and very large private-sector firms are collected using specialized staffs and forms. This is done to make the data collection process simple and flexible and to reduce the burden as much as possible. For some of these data collections, survey staff may abstract data directly from company records and plan brochures.
^top
In sample surveys like the MEPS-IC, non-certainty sample establishments represent not only themselves but also other similar establishments in the survey population. Therefore, in order to produce the survey estimates and standard errors presented in the MEPS-IC tables, weights must be created for all responding establishments. A brief description of this process is provided here. During the sample design and selection process, each establishment on the frame is given a probability of selection that is dependent on its stratum. These probabilities vary among establishments and assure that the sample sizes in each stratum are equal to that required by the allocation scheme. The inverse of this probability of selection is the establishment's base weight. The use of the base weight and the formula
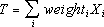
provides an unbiased estimate of a total T, if there is no non-response.
Because there is non-response, respondents' weights are adjusted to account for non-response so that these weights, when used with responding establishment data, will reduce the bias attributable to survey non-response. To accomplish this, the sample is divided into cells similar to the original sampling strata and the weights for each respondent in a specific cell are adjusted upward by the same percentage. The sum of the adjusted weights for respondents in these cells is equal to the sum of the base weights for all in-scope sampled establishments in the cell. Because it is assumed that the expected value of all responding establishments in each individual cell defined is equal to that of all the eligible respondents, use of the adjusted weights with respondents should produce the desired unbiased estimates of totals. Additional details on the enrollment and expenditure estimation process are available in MEPS Methodology Report No. 14, June 2003.
After adjustment for non-response, weights are post-stratified (Madow, Olkin, and Rubin, 1983.) using the frame of establishments in business during the last quarter of the year for which estimates would be made to produce control totals. For detailed information concerning construction of weights, see MEPS Methodology Report No. 28, October 2013.
Although railroads are included in the sample, the largest railroads are not included in the MEPS-IC tables (except in the Series IV National totals). Employment for these railroads cannot be broken down by State so their inclusion would distort results for States in which the headquarters of these railroads are located.
» Reliability of Estimates
For each table of estimates, a corresponding table of standard errors is provided. Beginning with 2014 data, standard errors are computed using the Taylor series linearization method - a widely used method of variance estimation for sample survey estimates. For details about the Taylor series method of variance estimation see Lohr (2009); Särndal, Swensson, and Wretman (1992); Lee, Forthoffer, and Lorimor (1989); and Wolter (1985). The computational details of the Taylor series variance estimation method for all different types of estimates in tables can be found in SAS Stat User's Guide (2012) or SUDAAN Technical Manual (1996).
As an example, under the Taylor series method, the variance (square of standard error) of an estimator of total,
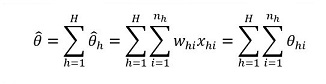
can be expressed as:
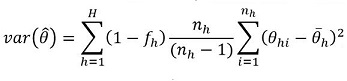
with
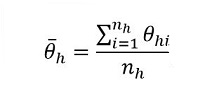
where, h represents the sampling stratum, nh is the sample size after nonresponse in stratum h, xhi is the value of a survey variable for establishment i in stratum h, whi is the corresponding final nonresponse-adjusted sampling weight for the same establishment, and
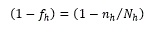
is the finite population correction (FPC) factor. Initially the FPC factor was not included in the Taylor Series variance estimation formula but starting in 2017 it was incorporated to improve estimation by accounting for sampling rates (Chowdhury et al., 2018).
Prior to 2014, standard errors for MEPS-IC estimates were produced using the method of random groups (Wolter, 1985; Skinner, Holt and Smith, 1989). During the sample selection process, each selected establishment was assigned a number from 0-9 sequentially to form 10 random groups. Considering each of these groups as a subsample similar to the full sample and assigning subsample weights that are 10 times the weights of the full sample, ten subsample estimates, θi , i = 1, 2, ...10 were made in addition to the full sample estimate, θ. The variance was then calculated as
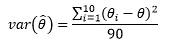
^top
The MEPS-IC tables are numbered in a hierarchical structure that facilitates locating estimates, helps clarify specifically what the estimates are measuring, and provides a mechanism for calculating count estimates for tables where percentages are provided.
The first level of the table numbering system is by the following categories and by year:
- Private-sector national level data by firm size, industry group, census region, and other characteristics
- Private-sector data by firm size, state, industry groupings, ownership type, age of firm, employee characteristics, and average wage quartiles
- Public-sector data by state and local government type, government size, and census division
- National totals for enrollees and cost of health insurance coverage for the private and public sectors
- Private-sector estimates
- Public-sector estimates
- Private-sector data by industry groupings and state
- Private-sector data by ownership type, age of firm, and state
- Private-sector data by proportion of employees who are full-time or low-wage and state
- Private-sector data by average wage quartiles and state
- Private-sector data by metro areas
- Private-sector data by percentile distributions of premiums, employee contributions, and employer costs and state
- Civilian data by private and state/local government sectors and census divisions
- Private-sector data 3-year pooled estimates
Within each of these categories (excluding Tables IV, IX, and X), tables are subsequently grouped by:
- Establishment-level tables
- Employee-level tables
- Premiums, employee contributions, and enrollment tables for single coverage plans
- Premiums, employee contributions, and enrollment tables for family coverage plans
- Premiums, employee contributions, and enrollment tables for employee-plus-one coverage plans
- Deductible, copayment, and coinsurance tables
- Percentile distributions of premiums, employee contributions, and employer costs (Tables I and III only)
Tables within each of these categories are ordered based on their inter-relationships.
For each of the MEPS-IC tables (excluding Tables IV, IX, and X), Figure 1 below identifies the denominator table of that table.
Examples of how to use Figure 1 to calculate approximate counts from the percentage estimates in the MEPS-IC tables are provided in the next section.
Figure 1. Listing of MEPS-IC table numbers and denominators for tables
| Table Number |
Denominator
for table |
| A.1. |
n/a |
| A.1.a. |
A.1. |
| A.2. |
A.1. |
| A.2.a |
A.2. |
| A.2.b. |
A.2. |
| A.2.b.(1). |
A.2. |
| A.2.b.(2). |
A.2. |
| A.2.b.(3). |
A.2. |
| A.2.c. |
A.2. |
|
A.2.c.(1). |
A.2. |
| A.2.c.(2). |
A.2. |
|
| Table Number |
Denominator
for table |
| A.2.c.(3). |
A.2. |
| A.2.d. |
A.2. |
| A.2.e. |
A.2. |
| A.2.f. |
A.2. |
| A.2.g. |
A.2. |
| A.2.h. |
A.2. |
| A.2.i. |
A.2. |
| A.2.j. |
A.2. |
| A.2.k. |
n/a |
| A.2.l. |
A.1. |
| A.2.m. |
A.1. |
|
| Table Number |
Denominator
for table |
| B.1. |
n/a |
| B.1.a. |
B.1. |
| B.2. |
B.1. |
| B.2.a. |
B.2. |
| B.2.a.(1). |
B.2.a |
| B.2.b. |
B.2. |
| B.2.b.(1). |
B.2.b. |
| B.2.b.1.a. |
B.2.b.1. |
| B.2.b.1.b. |
B.2.b.1. |
| B.2.c. |
B.2. |
| B.2.d. |
B.2.b. |
| B.2.e. |
B.2. |
| B.2.f. |
B.2. |
| B.2.g. |
B.2.g. |
| B.2.h. |
B.1. |
| B.2.i. |
B.1. |
|
| Table Number |
Denominator
for table |
| B.2.j. |
B.2.b. |
| B.2.k. |
B.2.b. |
| B.2.l. |
B.1. |
| B.2.m. |
B.1. |
| B.3. |
n/a |
| B.3.a. |
B.3. |
| B.3.b. |
B.3. |
| B.3.b.(1). |
B.3.b. |
| B.3.b.(1).(a). |
B.3.b.(1). |
| B.3.b.(2). |
B.3.b. |
| B.4. |
n/a |
| B.4.a. |
B.4. |
| B.4.b. |
B.4. |
| B.4.b.(1). |
B.4.b. |
| B.4.b.(1).a. |
B.4.b.(1). |
| B.4.b.(2). |
B.4.b. |
|
| Table Number |
Denominator
for table |
| C.1. |
C.4. |
| C.1.a. |
n/a |
| C.1.b. |
n/a |
| C.1.c. |
n/a |
| C.1.d. |
C.5. |
| C.1.e. |
C.6. |
| C.2. |
C.4. |
| C.2.a. |
n/a |
|
C.2.b. |
n/a |
| C.2.c. |
n/a |
| C.2.d. |
C.5. |
| C.2.e. |
C.6. |
|
| Table Number |
Denominator
for table |
| C.3. |
C.1. |
| C.3.a. |
C.1.a. |
| C.3.b. |
C.1.b. |
| C.3.c. |
C.1.c. |
| C.3.d. |
C.1.d. |
| C.3.e. |
C.1.e. |
| C.4. |
B.2.b. |
| C.4.a. |
C.4. |
| C.4.b. |
C.4. |
| C.5. |
100% - B.2.b.(1). |
|
C.6. |
B.2.b.(1). |
| | |
|
| Table Number |
Denominator
for table |
| D.1. |
D.4. |
| D.1.a. |
n/a |
| D.1.b. |
n/a |
| D.1.c. |
n/a |
| D.1.d. |
D.5. |
| D.1.e. |
D.6. |
| D.2. |
D.4. |
| D.2.a. |
n/a |
| D.2.b. |
n/a |
| D.2.c. |
n/a |
| D.2.d. |
D.5. |
|
| Table Number |
Denominator
for table |
| D.2.e. |
D.6. |
| D.3. |
D.1. |
| D.3.a. |
D.1.a. |
| D.3.b. |
D.1.b. |
| D.3.c. |
D.1.c. |
| D.4. |
B.2.b. |
| D.4.a. |
D.4. |
| D.4.b. |
D.4. |
| D.5. |
100% - B.2.b.(1). |
|
D.6. |
B.2.b.(1). |
| | |
|
| Table Number |
Denominator
for table |
| E.1. |
E.4. |
| E.1.d. |
E.5. |
| E.1.e. |
E.6. |
| E.2. |
E.4. |
| E.2.d. |
E.5. |
| E.2.e. |
E.6. |
| E.3. |
E.1. |
|
| Table Number |
Denominator
for table |
| E.3.d. |
E.1.d. |
| E.3.e. |
E.1.e. |
| E.4. |
B.2.b. |
| E.4.a. |
E.4. |
| E.4.b. |
E.4. |
| E.5. |
100% - B.2.b.(1). |
| E.6. |
B.2.b.(1). |
|
| Table Number |
Denominator
for table |
| F.1. |
B.2.b. |
| F.2. |
C.4. |
| F.3. |
D.4. |
| F.4. |
B.2.b. |
| F.5. |
F.4. |
| F.6. |
F.7. |
| F.7. |
B.2.b. |
| F.8. |
C.4. |
| F.9. |
D.4. |
| F.10. |
F.8. |
| F.11. |
F.9. |
| F.12. |
C.4. |
| F.12.a. |
F.12. |
| F.12.b. |
C.4. |
| F.12.c. |
C.4. |
| F.12.d. |
C.4. |
| F.12.e. |
C.4. |
| F.13. |
C.4. |
| F.14. |
C.4. |
| F.15. |
D.4. |
| F.15.a. |
F.15. |
| F.15.b. |
D.4. |
| F.15.c. |
D.4. |
| F.15.d. |
D.4. |
| F.15.e. |
D.4. |
| F.16. |
D.4. |
| F.17. |
D.4. |
| F.18. |
B.2.b. |
|
| Table Number |
Denominator
for table |
| F.19. |
F.18. |
| F.20. |
F.21. |
| F.21. |
B.2.b. |
| F.22. |
B.2.b. |
| F.23. |
B.2.b. |
| F.24. |
F.22. |
| F.25. |
F.23. |
| F.26. |
F.27. |
| F.27. |
B.2.b. |
| F.28. |
B.2.b. |
| F.29. |
F.28. |
| F.30. |
B.2.b. |
| F.31. |
F.30. |
| F.32. |
B.2.b. |
| F.33. |
F.32. |
| F.34. |
B.2.b. |
| F,35. |
B.2.b. |
| F.36. |
F.35 |
| F.37. |
C.4. |
| F.38. |
E.4. |
| F.39. |
D.4. |
| F.40. |
B.2.b. |
| F.41. |
B.2.b. |
| F.42. |
B.2.b. |
| F.43. |
C.4. |
| F.44. |
E.4. |
| F.45. |
D.4. |
| |
|
|
| Table Number |
Denominator
for table |
| G.1. |
n/a |
| G.2. |
n/a |
| G.3. |
n/a |
|
| Table Number |
Denominator
for table |
| G.4. |
n/a |
| G.5. |
n/a |
| | |
|
Note: Denominators are available only for tables that provide percentage estimates of counts. No “G” tables have percentage estimates of counts. Also, the “X” series of percentile distributions has no percentage estimates of counts.
^top
Many of the MEPS-IC tables contain percent estimates instead of count estimates. For instance, Table I.B.2 gives the percent of employees who work in establishments that offer health insurance. Table I.B.2.a gives the percent of employees who work at establishments that offer health insurance and who are eligible for health insurance. For most tables of percents, a count of the number of employees or establishments in any cell in the table can be calculated using data, for that cell, from the current table and one or more tables containing the denominator(s) for that cell.
To produce count estimates, multiply the cell values from the selected table and all of the denominators for that cell. For example, to estimate the total number of establishments that offer health insurance, use the percentage of these establishments in Table I.A.2 and determine from Figure 1 above that Table I.A.1 contains the value in the denominator of this percentage.
Thus, the estimated total number of establishments that offer health insurance in 2013 is:
.499(percents must be converted to decimals) x 7,009,707 = 3,497,844.
The first number (.499) is from Table I.A.2 and the second (7,009,707) is from Table I.A.
An approximate standard error for this count estimate can be computed using this formula:
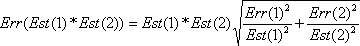
where Est(1) and Est(2) are the estimates from the two tables and Err(1) and Err(2) are the standard errors for those estimates.
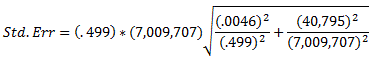
For some tables, a hierarchical structure exists so more than two tables are needed to derive an approximate count. For example, look at Table I.B.2.a, the percent of employees eligible for health insurance. Table I.B.2 is listed as its denominator for Table I.B.2.a and Table I.B.1 is the denominator for Table I.B.2. The values from all three tables, I.B.1, I.B.2, and I.B.2.a must be used to derive an estimate of the count. Thus, the estimated total number of employees eligible for health insurance in 2013 is .778 x .849 x 113,947,523 = 75,264,846, with the three values coming from Tables I.B.2.a, I.B.2, and I.B.1 respectively. Basically, one must multiply by a series of denominators until one reaches a table with numbers instead of percents (the shaded areas of the Table 1 on the previous page). The standard error for this count estimate (674,645) can be computed by using a logical expansion of the standard error formula provided above.
^top
Each year the MEPS-IC survey undergoes a number of changes in an effort to improve the existing survey while maintaining continuity from one year to the next. Listed below are the most significant changes that occurred in each year. In addition to the changes listed here, there were also changes to the wording and question order based on feedback from survey respondents.
| Survey year |
Major changes |
|
1996 |
|
| 1997 |
Establishment Form
- Dropped questions on retiree health insurance at the establishment-level and revised for collection at the company-level.
Company Form
- Added company-level forms (15 and 15S) for cases where data collection at the establishment-level was not feasible.
Methodology
- A rotation schedule to produce estimates for smaller States was introduced.
- Dropped sample of Self Employed with No Employees sample.
Tables
- Added a significant number of tables, introduced a new table-numbering system, and revised 1996 tables (using improved imputation and weighting methods) were reissued. The 1996 tables posted on the MEPS-IC Web site reflect these changes.
|
| 1998 |
Establishment Form
- Added follow-up questionnaire 10M for interviews of multi-establishment respondents where the Computer Assisted Telephone Instrument was not functioning.
Plan Form
- Removed the "first" plan-level questionnaire from the establishment and government questionnaires.
- Added follow-up questionnaire 10MS for interviews of multi-establishment respondents.
MEPSnet/IC
- MEPSnet/IC – an interactive search mechanism that produces trend output for all available years was introduced.
|
| 1999 |
Government Form
- The government questionnaire was split into front and rear parts – based on feedback from government respondents.
Methodology
- Dropped attempts to collect both current year data in addition to retrospective data.
Tables
- Expanded State-level estimates by providing three new sets of tables with estimates by industry groupings, ownership type, age of firm, and percent of full-time and low-wage employees.
|
| 2000 |
Establishment Form
- Expanded retiree health insurance questions and estimates.
- Changed industry categories to conform to the change from SIC codes to NAICS codes. Comparisons between 1999 and 2000 are not recommended.
- Changed definition of a low-wage employee so it would be automatically updated each year as wages increase or decrease. Comparisons by low-wage employees between 1999 and 2000 are not recommended.
|
| 2001 |
Plan Form
- Added questions on employee-plus-one premiums and employee contributions.
Tables
- Added State-level estimate tables by average wage quartiles.
- Added tables for employee-plus-one premiums and employee contributions.
|
| 2002 |
Methodology
- Changed post-data collection processes to reduce the time it takes to post estimates on the MEPS Web site.
- Added additional sample and produced separate estimates for the Virgin Islands.
Tables
- Added Metro-area tables with estimates for the 20 largest MSAs in the US and one or more MSAs within each State.
|
| 2003 |
Plan Form
- Added more detailed questions about the Prescription Drug benefits.
Methodology
|
| 2004 |
Plan Form
- Added questions on Health Savings Accounts (HSAs) and Health Reimbursement Arrangements (HRAs).
|
| 2005 |
Plan Form
- Revised questions on HSA and HRA.
- Revised questions on prescription drug tiers and services covered by the plans.
Tables
- Added Tables with estimates of average deductibles (single and family), and average copayments and coinsurances. Tables were created starting with year 2002.
|
| 2006 |
Plan Form
- Added questions on employer deposits to HSA accounts.
Tables
- Added Tables with percentile distributions of premiums, employee contributions, and employer costs.
|
| 2007 |
Methodology
- No MEPS-IC data are available for 2007 due to the transition from retrospective to current data collection.
|
| 2008 |
Establishment Form
- Revised question on cost of optional insurance coverage and changed reference from annual to monthly.
Methodology
- Changed data collection from retrospective (calendar year following survey year) to current (calendar year same as survey year). Current collection makes private sector estimates for the survey year available 12 months earlier and government estimates available eight months earlier, compared to retrospective collection.
|
| 2009 |
Establishment Form
- Added questions about limits on covering the spouse of an enrollee and about incentives provided to employees if they did not elect to take coverage.
Methodology
- Web based data collection was introduced.
|
| 2010 |
Tables
- Added a new set of tables that provide comparable estimates at the Census Division level for the private-sector, State and local governments, and a combination of both.
|
| 2011 |
|
| 2012 |
Establishment Form
- Added question on number of employees earning above a specific hourly wage (to be updated annually).
- Added question for small employers only on whether Small Business Health Care Tax Credit will be claimed.
|
| 2013 |
Establishment Form
- Added questions on health insurance offers to unmarried domestic partners.
Plan Form
- Added question on stop loss coverage amount for self-insured plans.
- Added question on grandfathered plans under the ACA.
- Revised question on the list of services covered by the plan.
- Revised question on whether premiums vary for plan.
- Revised question on whether employee contributions vary for plan.
- Dropped question on HRAs.
- Dropped question about limits on spousal coverage.
- Dropped question on length of waiting period.
- Dropped question on number of tiers in prescription drug plan.
- Dropped question on annual maximum amount plan pays per enrollee.
|
| 2014 |
Establishment Form
- Added question for small businesses on whether insurance was obtained through a SHOP exchange under the ACA.
- Added question on number of employees who worked less than 30 hours per week.
- Added question on whether employees' spouses were eligible for health insurance coverage.
- Added question on whether organization offered health insurance in prior year.
- Revised question on whether organization offers health insurance.
- Dropped question on the last year the organization offered health insurance.
- Dropped question on whether organization offered health insurance to temporary or seasonal employees.
Plan Form
- Added question on metal level or tier of plan for small employers.
- Added question on actuarial value of plan for large employers.
- Added question on whether premium varied by employees' ages.
- Added question on whether total premium for family coverage varied by the number of family members.
- Revised question on whether employee contribution varied by participation in health programs or by employee age.
- Added question on how employee contributions varied by age.
- Revised question on how much and/or what percentage did enrollee pay out-of-pocket for prescription drug covered (Generic, Preferred Brand Name, Non-preferred Brand Name).
- Dropped question on pre-existing medical or health conditions.
- Dropped question on requiring a waiting period before covering pre-existing conditions.
Methodology
|
| 2015 |
Establishment Form
- Added question about the use of a private exchange for large firms (greater than 50 employees).
- Revised response categories for question "Were employees' SPOUSES eligible for health insurance coverage through your organization?"
- Combined questions on coverage for unmarried domestic partners into a single question.
- Dropped questions on prescription drug coverage for retirees under 65 years of age and retirees 65 years of age or older.
Plan Form
- Added question about Health Reimbursement Arrangement (HRA), this question is being reinstated after being deleted in 2013.
- Added a specialty drug tier to the existing question on prescription drug copayments and coinsurance.
- Dropped the response category "Older employees pay more" for question "Did the amount individual EMPLOYEES contributed toward their SINGLE coverage premium vary by any of these characteristics?"
|
| 2016 |
Establishment Form
- Added question about using a third party, such as an insurance broker or agent, to help purchase insurance plan(s).
- Revised definition of a small business from 50 or fewer to 100 or fewer employees and definition of a large business from more than 50 to more than 100 employees.
Plan Form
- Combined metal level question and actuarial value question; the respondent is asked to report either actuarial value or metal level.
- Deleted the question "Why did older employees contribute more toward their single coverage premium."
- Deleted the option to report separate deductibles for physician care and hospital care.
- Revised the question wording for employer contributions to a health savings account (HSA).
- Revised the question wording for a health reimbursement arrangement (HRA).
- Added question about out-of-pocket copayment or coinsurance for specialist physician office visits after any annual deductible was met.
- Added a question to determine if the plan has a separate annual deductible that applies only to prescription drugs.
- Added a question for the annual deductible (in dollars) for prescription drugs for single coverage.
|
| 2017 |
Establishment Form
- Renumbered questions on the form.
- Added question about the use of a private exchange for small employers.
- Revised question about financial compensation or incentives to employees.
- Revised question labels for retirees age 65 years or older.
- Added respondent's email address fill-in box.
Plan Form
- Removed HSA instruction under Plan Premium.
- Revised question on out-of-pocket payment for prescription drugs.
Methodology
- Included FPC factor in sampling error methodology.
- Sampled all certainty establishments for the private-sector sample.
- Added additional sample of government units and sampled all dependent agencies for certainty governments.
|
| 2018 |
Establishment Form
- Revised plan choice wording from conventional plan to PPO.
- Changed section on retirees from single to double column format.
Plan Form
- Revised wording for questions on individual and family deductible.
- Added questions on monthly HSA contributions for single and family coverage.
- Added questions on annual HRA contributions for single and family coverage.
- Added Telemedicine to question on services covered by plan.
Methodology
- Included Percentages of women and employees ages 50 or older in National-level tables characteristics.
- Longitudinal Business Database extract from the 2017 survey year used to calculate FIRMAGE values for 2018.
|
| 2019 |
Establishment Form
- Added question on Qualified Small Employer Health Reimbursement Arrangement.
- Deleted question on Small Business Health Options Program exchange.
- Deleted question on Small Business Health Care tax credit.
Plan Form
- Added question on employee-plus-one deductible.
- Added question on maximum annual out of pocket for employee-plus-one coverage.
- Revised wording for question on union or trade association to include Association Health Plans.
|
| 2020 |
Establishment Form
- Added question on Individual Coverage Health Reimbursement Arrangement.
- Added response category "critical illness insurance" for question "Did your organization offer the following fringe benefits to its employees at this location?"
Methodology
- Secure email messaging system was introduced for respondents.
- Due to limited availability of current year source data for the agriculture sector (NAICS 111 and 112), prior year agriculture data was used for the reweighting adjustments. This prior year agriculture data was adjusted down by 3% based on BLS employment change between 2019 and 2020.
- Data collection became web-first instead of mail-first.
Tables
- Added Metro Area tables with estimates calculated using 3-year averages.
|
| 2021 |
Methodology
- Due to limited availability of current year source data for the agriculture sector (NAICS 111 and 112), prior year agriculture data was used for the reweighting adjustments.
Plan Form
- Added Questions on out-of-network coverage.
|
| 2022 |
Methodology
- Made modifications to the Death model weight adjustment methods.
|
| 2023 |
Plan Form
- Added question about level-funded plan
- Added question about plan covering TELEMEDICINE
- Added question about plan covering TELEMEDICINE for mental health and substance abuse
|
| 2025 |
Methodology
- Precanvass operation replaces Prescreener operation.
|
^top
Chowdhury, S., Kashihara, D., and Thompson, M. (2018). Incorporating a Finite Population Correction into the Variance Estimation of a National Business Survey. Proceedings of the Federal Committee on Statistical Methods (FCSM), 2018 Annual Conference.
Cochran, W.G. (1977), Sampling Techniques, Third Edition, New York: John Wiley & Sons, Inc.
Fuller, W.A. (1975), Regression Analysis for Sample Survey, Sankhya, 37 (3), Series C, 117–132.
Kashihara, D. Construction of Weights for the 2011 Medical Expenditure Panel Survey Insurance Component, AHRQ Methodology Report 28.
Lee, E. S., Forthoffer, R. N., and Lorimor, R. J. (1989), Analyzing Complex Survey Data, Sage University Paper series on Quantitative Applications in the Social Sciences, series no. 07-071, Beverly Hills and London: Sage Publications, Inc.
Lohr, S. L. (2009), Sampling: Design and Analysis, Second Edition, Pacific Grove, CA: Duxbury Press.
Madow, W.G., Olkin, I., Rubin D.B. Incomplete data in sample surveys, Volume 2: Theory and bibliographies. New York: Academic Press; 1983.
Sarndal, C.E., Swenson, B., and Wretman, J. (1992), Model Assisted Survey Sampling, New York: Springer-Verlag Inc.
Skinner, C. J., Holt, D. and Smith, T. M. F. eds. (1989), Analysis of Complex Surveys. Chichester: Wiley.
Wolter, K. M. (1985), Introduction to Variance Estimation, New York: Springer-Verlag Inc.
Woodruff, R.S. (1971), A Simple Method for Approximating the Variance of a Complicated Estimate, Journal of the American Statistical Association, 66(334), 411–414.
^top
|
Suggested Citation:
MEPS Insurance Component: Technical Notes and Survey Documentation. Agency for Healthcare Research and Quality, Rockville, Md. http://www.meps.ahrq.gov/survey_comp/ic_technical_notes.shtml
|
|
